Giriş
Regresyon analizi yöntemlerinden biri olan multiple (çoklu) regresyon analiz (MRA) yöntemi, bağımlı değişkenin ya da cevap değişkeninin
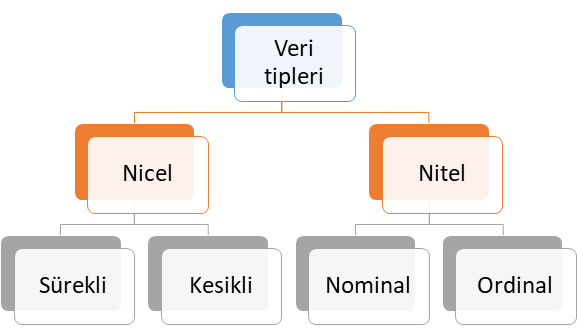
nicel sürekli veya kesikli olduğu bağımlı değişkenler (dependent variables) ile bağımsız değişken veya değişkenler (independent variables) arasındaki ilişkiyi ortaya koyan regresyon analiz yöntemidir. Veri tipleri kendi içerisinde 4 farklı alt sınıfta ele alınabilir. Bu veri tipleri Şekil 1’de verilmiştir.
Şekil 1: Veri Tipleri
Nitel Veri (Qualitative Data)
Şekil 1’de verilen sunulan nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek vererek ele alalım.
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
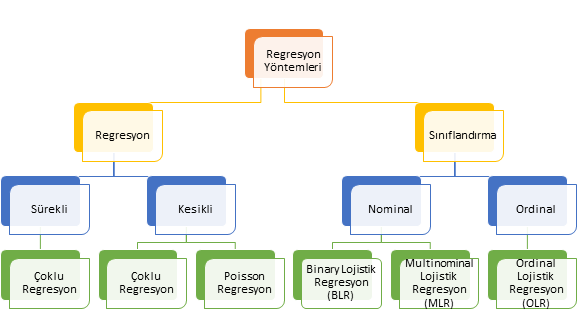
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek regresyon analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Eğer cevap değişkeni nitel ise aslında sınıflandırma problemini çözmek için analizi kullanıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisi tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemi de değiştirecektir. Bağımlı (dependent) değişkenin tipine göre kullanılan regresyon analiz yöntemleri Şekil 2’de genel hatlarıyla verilmiştir.
Şekil 2: Cevap Değişkeninin Veri Tipine Göre Regresyon Analiz Yöntemleri
Modeller oluşturulurken temel amaç, bias ve varyans dengesinin kurulmasıdır. Bu uyumu sağlarsak iyi model uyumu (good-fit) elde etmiş oluruz. Makine öğrenme ve derin öğrenme problemlerinin çözümünde modelleme hatalarına bağlı olarak varyans ve bias değişiklik göstermektedir. Bu iki durum şöyle ele alınabilir:
- Eksik model uyumu (under-fitting): Kurulan modelde elde edilen tahmin değerleri gözlem verisine yeterince uyum göstermediğinde ortaya çıkar. Bu durumda varyans düşükken bias yüksektir. Buradan şunu anlamak gerekir: gözlem verisi ile tahmin edilen veri arasındaki fark büyükse, diğer bir deyişle kurulan modelle bağımlı değişken iyi tahmin edilemiyorsa bu durumda under-fitting oluşur. Under-fitting sonraki kısımlarında anlatılan sınıflandırma ve regresyon hata metrikleri ile kolaylıkla ortaya konulabilir.
- Aşrı model uyumu (over-fitting): Kurulan modelde eğitilen veri seti (training data set)’yle gözlem verisine aşırı uyum gösterdiğinde ortaya çıkar. Bu durumda varyans yüksekken bias düşüktür.
Bahsedilen bu iki durumu kafamızda daha da canlı tutmak için bias ve varyans ilişkisi Şekil 2’de verilmiştir. Şekil’de biz modeli kurgularken olması gereken durumu gösteren Düşük Varyans-Düşük Bias uyumunu, diğer bir ifadeyle yüksek kesinlik (precision)-yüksek doğruluk (accuracy) hedefliyoruz. Diğer bir deyişle kurguladığımız model (Şekil 2 1 nolu model) ile gözlem değerlerini olabildiğince en yüksek doğruluk oranı ile tahmin ederken aynı zamanda varyansı düşük (yüksek kesinlik (precision)) tutmayı hedefliyoruz. Buna başardığımızda aslında iyi model uyumunu (good-fit) sağlamış ve iyi bir model kurmuş oluyoruz. Eksik model uyumu (under-fitting)’nda ise Şekil 2’de 3 nolu modelde görüleceği üzere elde edilen tahmin değerleri gözlem değerleri (kırmızı alan)’nden uzaklaşmakla birlikte hala tahmin değerleri ile gözlem değerleri arasında farklar, diğer bir deyişle varyans düşüktür. Aşırı model uyumu (over-fitting)’da ise Şekil 2’de 2 nolu modelde görüleceği üzere varyans yüksek iken bias düşüktür. 2 nolu modelde doğru değerler (gözlem değerleri)’i kurulan modelde yüksek doğrulukla (düşük bias=yüksek doğruluk (accuracy) tahmin edilse de gözlem değerleri ile tahmin değerleri arasındaki varyans yüksektir.
Şekil 2: Bias-Varyans İlişkisi

Veri Tipleri
Yükseltme algoritmaları ile sınıflandırma problemi çözüyorsak bağımlı değişkenin ya da cevap değişkeninin veri tipi nitel ve kategoriktir. Ancak, bu yöntem ile regresyon problemini çözüyorsak bağımlı değişkenin ya da cevap değişkeninin veri tipi niceldir. Veri tipleri kendi içerisinde 4 farklı alt sınıfta ele alınabilir. Bu veri tipleri alt sınıflarıyla birlikte Şekil 3’te verilmiştir.
Şekil 3: Veri Tipleri
Nicel Veri (Quantitative Data)
Şekil 3’te sunulan nicel veri tipi ölçülebilen veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek verelim.
- Sürekli veri (Continous data): Tam sayı ile ifade edilmeyen veri tipi olup, zaman, sıcaklık, beden kitle endeksi, boy ve ağırlık ölçümleri bu veri tipine örnek verilebilir.
- Kesikli veri (Discrete Data): Tam sayı ile ifade edilebilen veri tipi olup, bu veri tipine proje sayısı, popülasyon sayısı, öğrenci sayısı örnek verilebilir.
Nitel Veri (Qualitative Data)
Şekil 3’te verilen nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar şöyledir:
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisini tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemini de değiştirecektir.
Kullanılan analiz yöntemi ile kurulan modelde ya sınıflandırma problemini ya da regresyon problemini çözdüğümüzü ifade etmiştik. Ancak kurulan modellerde çözülen problemin sınıflandırma ya da regresyon oluşuna göre performans değerlendirmesi farklılaşmaktadır. Sınıflandırma problemlerinde kullanılan hata metrikleri ile regresyon hata metrikleri aynı değildir. Bu bağlamda ilk olarak sınıflandırma problemlerinin çözümünde kullanılan hata metriklerini ele alalım.
Sınıflandırma Problemlerinde Hata Metrikleri
Karışıklık matrisi (confusion matrix) olarak olarak adlandırılan bu matris sınıflandırma problemlerinin çözümünde hata metriklerini ortaya koyarak kurulan modelin veya modellerin hata oranını değerlendirmektedir. Hata matrisinin makine ve derin öğrenme metotlarının değerlendirilmesinde sıklıkla kullanıldığı görülmektedir. Tablo 1’de hata metriklerinin hesaplanmasına esas teşkil eden karışıklık matrisi (confisioun matrix) verilmiştir. Bu tabloyla sınıflandırma hataları hesaplanabilmektedir. Tabloda yer verilen Tip 1 hata (Type 1 error) istatistikte alfa hatasını göstermektedir. Tip 1 hata H0 hipotezi (null hpypothesis) doğru olduğu halde reddedilmesidir. Tabloda Tip 2 hata (Type II error) olarak adlandırılan hata ise istatistikte Beta hatası olarak da bilinmektedir. Tip 2 hata ise H0 hipotezi (null hpypothesis) yanlış olduğu halde kabul edilmesidir.
Tablo 1: Karışıklık Matrisi (Confusion Matrix)

Tablo 1’de TP: Doğru Pozitifleri, FN: Yanlış Negatifleri, FP: Yanlış Pozitifleri ve TN: Doğru Negatifleri göstermektedir.
Şekil 3’te de yer verildiği üzere literatürde sınıflandırma modellerinin performansını değerlendirmede aşağıdaki hata metriklerinden yaygın bir şekilde yararlanıldığı görülmektedir. Sınıflandırma problemlerinin çözümüne yönelik Yükselme (Boosting: AdaBoost) algoritması kullanarak R’da yapmış olduğum çalışmanın linkini ilgilenenler için aşağıda veriyorum.
- Doğruluk (Accuracy): TP+TN / TP+TN+FP+FN eşitliği ile hesaplanır. Modelin genel performansını ortaya koyar. Bu sınıflandırma metriği ile aslında biz informal bir şekilde dile getirirsek doğru tahminlerin toplam tahminler içindeki oranını hesaplamış oluyoruz.
- Kesinlik (Precision): TP / TP+FP eşitliği ile hesaplanır. Doğru tahminlerin ne kadar kesin olduğunu gösterir.
- Geri çağırma (Recall): TP / TP+FN eşitliği ile hesaplanır. Gerçek pozitif örneklerin oranını verir.
- Özgünlük (Specificity): TN / TN+FP eşitliği ile hesaplanır. Gerçek negatif örneklerin oranını gösterir.
- F1 skoru : 2TP / 2TP+FP+FN eşitliği ile hesaplanır. Dengesiz sınıflar için yararlı hibrit bir metrik olup, kesinlik (precision) ve geri çağırma (recall) skorlarının ağırlıklı ortalamasını ifade etmektedir.
- ROC (Receiver operating characteristic): Yukarıda karışıklık matrisinde belirtilen parametrelerden yararlanılarak hesaplanır. ROC eğrisi olarak da adlandırılmaktadır. ROC eğrileri, herhangi bir tahmin modelinin doğru pozitifler (TP) ve negatifler (TN) arasında nasıl ayrım yapabileceğini görmenin güzel bir yoludur. Sınıflandırma modellerin perfomansını eşik değerler üzerinden hesaplar. ROC iki parametre üzerinden hesaplanır. Doğru Pozitiflerin Oranı (TPR) ve Yanlış Pozitiflerin Oranı (FPR) bu iki parametreyi ifade eder. Burada aslında biz TPR ile Geri Çağırma (Recall), FPR ile ise 1-Özgünlük (Specificity)‘ü belirtiyoruz.
- Cohen Kappa: Kategorik cevap seçenekleri arasındaki tutarlılığı ve uyumu gösterir. Cohen, Kappa sonucunun şu şekilde yorumlanmasını önermiştir: ≤ 0 değeri uyumun olmadığını, 0,01–0,20 çok az uyumu, 0,21-0,40 az uyumu, 0,41-0,60 orta, 0,61-0,80 iyi uyumu ve 0,81–1,00 çok iyi uyumu göstermektedir. 1 değeri ise mükemmel uyum anlamına gelmektedir.
Sınıflandırma hata metriklerini anlattıktan sonra daha kalıcı olması ve öğrenilmesi adına hazırladığım excel üzerinde bahsedilen bu metriklerin nasıl hesaplandığı gösterilmiştir. Excel dosyasını aşağıdaki linkten indirebilirsiniz.
Regresyon Problemlerinde Hata Metrikleri
Regresyon modellerinin performansını değerlendirmede literatürde aşağıdaki hata metriklerinden yaygın bir şekilde yararlanılmaktadır. Regresyon metrikleri eşitliklerinin verilmesi yerine sade bir anlatımla neyi ifade ettiği anlatılacaktır. Böylece formüllere boğulmamış olacaksınız.
- SSE (Sum of Square Error): Tahmin edilen değerler ile gözlem değerleri arasındaki farkların kareleri toplamını ifade eder.
- MSE (Mean Square Error): Ortalama kare hatası olarak adlandırılan bu hata tahmin edilen değerler ile gözlem değerleri arasındaki farkların karelerinin ortalamasını ifade eder.
- RMSE (Root Mean Square Error): Kök ortalama kare hatası olarak adlandırılan bu hata ortalama kare hatasının karekökünü ifade etmektedir.
- MAE (Mean Absolute Error): Ortalama mutlak hata olarak adlandırılan bu hata türü ise tahmin edilen değerler ile gözlem değerleri arasındaki farkların mutlak değerlerinin ortalamasını ifade etmektedir.
- MAPE (Mean Absolute Percentage Error): Ortalama mutlak yüzdesel hata olarak adlandırılan bu hata türünde ilk olarak tahmin edilen değerler ile gözlem değerleri arasındaki farkların mutlak değerleri hesaplanır. Daha sonra hesaplanan farkları mutlak değerleri mutlak değerleri alınan gözlem değerlerine bölünür. En son durumda ise elde edilen bu değerlerin ortalaması alınır.
- Bias: Tahmin edilen değerler ile gözlem değerleri arasındaki farkların ortalamasıdır. Bu yönüyle ortalama mutlak hata (MAE)’ya benzemektedir.
Regresyon hata metriklerini anlattıktan sonra daha kalıcı olması ve öğrenilmesi adına hazırladığım excel üzerinde bahsedilen bu metriklerin nasıl hesaplandığı gösterilmiştir. Excel dosyasını aşağıdaki linkten indirebilirsiniz.
Çalışma kapsamında R programlama dili içerisinde bulunan “mlbench” paketi içerisinde “BostonHousing” veri seti kullanılarak multiple regresyon yöntemiyle regresyon problemi çözülecektir. Bu amaçla bağımlı değişken olan ABD’nin Boston bölgesindeki konutların medyan fiyatları tahmin edilecektir.
Metodoloji ve Uygulama Sonuçları
Çoklu Doğrusal Regresyon Yöntemi
Regresyon modeli aşağıdaki eşitlikteki gibi ifa edilebilir.
Yi=β0+β1X i1 +β2Xi2+…+βkXik +𝜀𝑖𝑗
Burada i=1,2,…n j=1,2,…k şeklinde tanımlanır.
Eşitlikte;
Yi: Bağımlı değişkeninin gözlenen i.inci
değerini
Xij: j.inci bağımsız değişkenin i.inci
düzeyindeki değerini
βj: j.inci regresyon katsayısını
εij: Hata terimini
k: Bağımsız değişken sayısını göstermektedir
Çoklu Doğrusal Regresyon Yöntemi Varsayımları
Çoklu doğrusal regresyon yöntemi gözlemlere en iyi uyum sağlayan regresyon doğrusunu çizmek için en küçük kareler yöntemini kullanır. Hesaplanan en küçük kareler regresyon denklemi regresyon doğrusu ile gözlemler arasındaki minimum kare hataları toplamına veya sapmalara sahiptir. Söylenenleri kafamızda daha da canlandırmak adına en küçük kareler yöntemi (method of least squares)’nin işleyişi Şekil 4’de verilmiştir.
Şekil 4: En Küçük Kareler Yöntemi (Method Of Least Squares)’nin İşleyişi

Kaynak: https://www.jmp.com
Değişken tipleri: Bütün bağımsız değişkenler nicel veya kategorik olmalıdır. Bağımlı değişken ise nicel kesikli veya süreklidir.
Varyans: Bağımsız değişkenlerin varyansı 0 olmamalıdır.
Çoklu doğrusal ilişki (Multicollinearity): 2 veya daha çok bağımsız değişken arasında mükemmel (r= 1 veya -1) veya mükemmele yakın (-1 veya 1’e yakın) bir ilişki olmamalıdır. Yani değişkenler arasında çok yüksek bir korelasyon bulunmamalıdır. Eğer kurulan regresyon modelinde değişkenler arasında güçlü bir ilişki varsa değişkenlerin bireysel önem düzeyinin belirlenmesi zorlaşacaktır. Bu ilişkiyi belirlemenin bir yolu da değişkenler arasındaki korelasyonun korelasyon matrisi ile ortaya konulmasıdır. Tabi burada belirtilen korelasyon katsayıların 0,80 ve üzerinde olmasıdır. Yaygın olarak kullanılan ilişki belirleme yöntemi varyans enflasyon faktörü (variance inflation factor) kısa adıyla VIF’tir. VIF de korelasyon matrisi gibi bağımsız değişkenler arasındaki ilişkinin gücünü ortaya koymaktadır. VIF değeri 10’dan büyükse kurulan regresyon modelinde endişe kaynağı olarak görülmelidir. VIF 1 / 1-R2 eşitliği ile hesaplanmaktadır. VIF ölçüm parametresine bağlı olarak hesaplanan tolerans (tolerance) seviyesi de çoklu doğrusal ilişkiyi ortaya koymada yardımcı olabilmektedir. Tolerans seviyesi VIF parametresinin çarpmaya göre tersidir. Diğer bir ifadeyle 1 / VIF eşitliği ile hesaplanmaktadır. 0,1’in altındaki tolerans seviyeleri çoklu doğrusal ilişki açısından gözden geçirilmelidir. Çoklu doğrusal ilşkiyi ortaya koymanın bir yolu da kurulan modelden üretilen varyans oranları ve normalize edilmiş özvektör değerlerinin hesaplanmasıdır.
Homoskedastisite (Homoscedasticity): Bağımsız değişkenlerin her seviyesinde artıklar (residuals)’ın varyansı aynı / sabit kalmalıdır, diğer bir ifadeyle varyanslar homojen olmalıdır. Eğer varyanslar eşit değilse heteroskedastisite (heteroscedasticity) durumu ortaya çıkar. Bu iki durum aşağıdaki grafikte karşılaştırmalı olarak verilmiştir.
Şekil 4: Homoskedastisite ve Heteroskedastisite
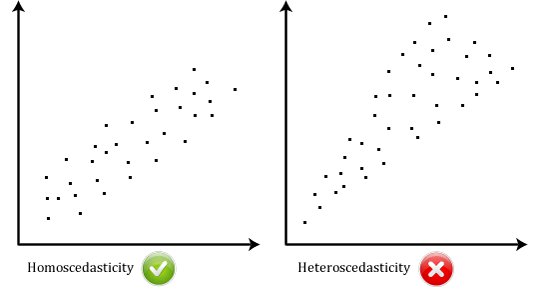
Kaynak: https://marcfbellemare.com/
Otokorelasyon: Hataların bağımsızlığı anlamına da gelen otokorelasyon bir gözlemle ilişkili hataların, diğer gözlemlerin hataları arasında korelasyon olmaması gerektiğini ileri sürer. Otokorelasyon testi için artıkların hatalarına bakılır. Bu varsayım Durbin-Watson testi test edilebilir. Test istatistiği 0 ile 4 arasında değişmektedir. 2’den büyük bir değer negatif otokorelasyonu, 2’den küçük değer ise pozitif otokorelasyonu göstermektedir.
Doğrusallık (Linearity): Modellenen ilişkinin doğrusal olması gerektiğini öne sürer. Eğer doğrusal olmayan (non-linear) bir ilişki varsa bulguların genellenebilirliği açısından problem oluşturacaktır.
Kurulan regresyon analiz modellerinde güvenilir bir regresyon modeli kurmak için örneklem büyüklüğünün asgari şartları karşılaması gerekmektedir. Buna göre;
- Kurulan regresyon modelinin tamamını değerlerdirmek için önerilen minimum örneklem büyüklüğü 50 + 8k‘tır. k burada bağımsız değişkenlerin sayısını göstermektedir. Örneğin bağımsız değişkenlerin sayısı 10 ise minimum örneklem büyüklüğü 50 + 8 X 10 eşitliğinden 130’dur.
- Eğer bireysel olarak bağımsız değişkenler değerlendirilecek ise minimum örneklem büyüklüğü 104 + k‘tır. Örneğin bağımsız değişkenlerin sayısı 10 ise minimum örneklem büyüklüğü 104 + 8 eşitliğinden 112’dir.
- Diğer taraftan örneklem büyüklüğü ve bağımsız değişkenin sayısına göre Cohen’in kriterini kullanarak etki büyüklüğünü hesaplayabiliriz. Cohen’in etki büyüklüğü örneklem büyüklüğü ve bağımsız değişken sayısı artıkça etki büyüklüğü azalış göstermektedir. Bu durum istenen bir durumdur. Cohen’in etki büyüklüğü R= k / (N-1) formülü ile hesaplanmaktadır. k burada bağımsız değişken sayısını, N ise örneklem / popülasyon büyüklüğünü / gözlem sayısını göstermektedir. Yukarıdaki veriler kullanılarak örnek vermek gerekirse 8 / ( 112-1) =0,07‘dir. R katsayısının 0 olması etki olmadığı anlamına gelmektedir ki, bu durumda örneklem büyüklüğünün ve değişken sayısının kurulan regresyon modelinde optimal noktaya ulaştığı anlamına gelir.
Veri seti
ABD’nin Boston bölgesinde konutların medyan fiyatları (hedef değişken) tahmin edilmiştir. Diğer bir ifadeyle, bu çalışmada regresyon problemi çözmüş olacağız. Analizde kullanılan veri seti ABD Nüfus Bürosu tarafından Boston bölgesindeki konutlarla ilgili olarak toplanan verilerden oluşmaktadır. Veri setindeki toplam gözlem sayısı 506, değişken sayısı ise 14’tür. Bu veri setine R programlama yazılımında “mlbench” paketi içerisinde “BostonHousing” olarak yer verilmiştir. Veri setinde yer alan değişkenler ve değişkenlerin veri tipleri şöyledir:
- crim: per capita crime rate by town. Veri tipi nicel ve süreklidir.
- zn: proportion of residential land zoned for lots over 25,000 sq.ft. Veri tipi nicel ve kesiklidir.
- indus: proportion of non-retail business acres per town. Veri tipi nicel ve süreklidir.
- chas: Charles River dummy variable (1 if tract bounds river; 0 otherwise). Veri tipi nitel ve nominal kategoriktir.
- nox: nitric oxides concentration (parts per 10 million): Veri tipi nicel ve süreklidir.
- rm: average number of rooms per dwelling. Veri tipi nicel ve süreklidir.
- age: proportion of owner-occupied units built prior to 1940. Veri tipi nicel ve süreklidir.
- dis: weighted distances to five Boston employment centres. Veri tipi nicel ve kesiklidir.
- rad: index of accessibility to radial highways. Veri tipi nicel ve süreklidir.
- tax: full-value property-tax rate per $10,000. Veri tipi nicel ve kesiklidir.
- ptratio: pupil-teacher ratio by town. Veri tipi nicel ve süreklidir.
- b: 1000(Bk – 0.63)^2 where Bk is the proportion of blacks by town. Veri tipi nicel ve süreklidir.
- lstat: % lower status of the population. Veri tipi nicel ve süreklidir.
- medv: Median value of owner-occupied homes in $1000’s. Veri tipi nicel ve süreklidir.
Bu kapsamda cevap değişkeni (bağımlı değişken) olan “medv” yani konut fiyatlarının medyan değeri geri kalan 13 bağımsız değişken kullanılarak çoklu doğrusal regresyon analiz yöntemiyle tahmin edilecektir. Analizde kullanılan veri setini aşağıdaki linkten indirebilirsiniz.
Boston Konut Fiyatları Veri Seti İndir
Şimdi veri setini tanıdıktan sonra adım adım (step by step) analize başlayabiliriz. Analizde R programlama dili kullanarak analiz adımları R kod bloklarında verilmiştir.
Yüklenecek R kütüphaneleri
rm(list=ls())
kütüphaneler = c("dplyr","tibble","tidyr","ggplot2","formattable","readr","readxl","xlsx", "pastecs","fpc", "DescTools","e1071", "DMwR","caret", "viridis","GGally","ggpurr","psych","writexl","ggfortify","explore","MASS","gbm")
sapply(kütüphaneler, require, character.only = TRUE)
Ver setinin okunması
data(BostonHousing)
veri<-BostonHousing
Ver setinin xlsx dosyasına yazdırılması
write_xlsx(veri, "Bostonkonutfiyatları.xlsx")#xlsx dosyası için
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri seti xlsx uzantılı dosyaya yazdırılmıştır. Elde edilen veri seti dosyası xlsx uzantılı olarak aşağıdan indirilebilir.Boston Konut Fiyatları Veri Setiİndir
Veri setinin görselleştirilmesi ve tanımlayıcı istatistikler
#veri setindeki ilk 3 değişkenin görselleştirilmesi
veri[,1:3] %>% explore_all()
#veri setindeki 4,5,6 ve 7. değişkenlerin görselleştirilmesi
veri[,4:7] %>% explore_all()
#veri setindeki 8,9 ve 10. değişkenlerin görselleştirilmesi
veri[,8:10] %>% explore_all()
#veri setindeki 11,12,13 ve 14. değişkenlerin görselleştirilmesi
veri[,11:14] %>% explore_all()
#veri setindeki ilk 10 gözlem
formattable(head(veri,10))
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki ilk 3 değişkenin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki 4,5,6 ve 7. değişkenlerin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki 8,9 ve 10. değişkenlerin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki 11, 12, 13 ve 14. değişkenlerin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.
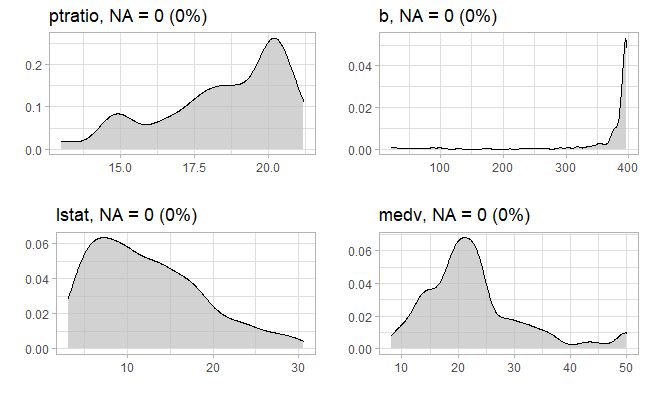
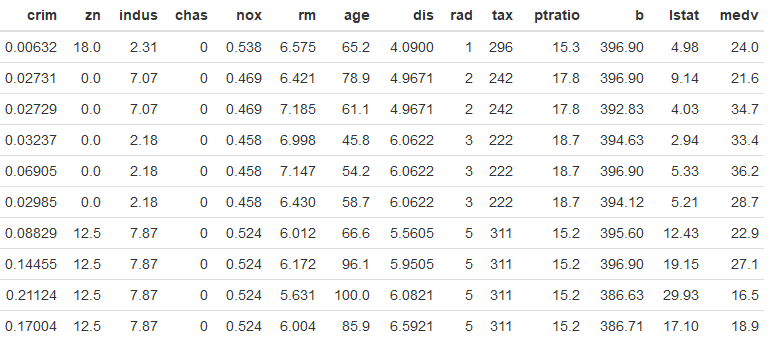
Yukarıdaki R kod bloğunun çalıştırılmasından sonra Boston Konut Fiyatları veri setindeki ilk 10 gözlem aşağıdaki tabloda verilmiştir.
Değişkenler arasındaki korelasyonun hesaplanması
Kategorik değişkenlerin korelasyon katsayılarını hesaplamak için yazılan R kod bloğu aşağıdadır. Değişkenler arasındaki korelasyonu hesaplamak için Kikare ve Anova testleri kullanılmıştır. Korelasyon katsayısı hesaplanacak her iki değişkenin de nitel ve nominal olmasından dolayı Kikare, korelasyon katsayısı hesaplanacak değişkenlerden biri nicel kesikli ve diğeri nominal olduğundan Anova testleri yapılmıştır. Korelasyon katsayısı hesaplanacak değişkenlerden biri ordinal (sıralı) olsaydı bu durumda Spearman korelasyon (SpearmanRho) katsayısının hesaplanması gerekecekti. Diğer taraftan, eğer her iki değişken nicel (sürekli ve kesikli) olsaydı bu durumda Pearson korelasyon katsayısını hesaplayacaktık.
#Pearson korelasyon matrisi
cor.plot(veri[,-4], main="Korelasyon Matrisi")#grafik formatında
kormatris<-cor(veri[,-4])#matris formatınta
kormatris
findCorrelation(kormatris, cutoff=0.8,names=TRUE, exact = TRUE)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra nicel ve kesikli değişkenlere ait Pearson korelasyon matrisi aşağıdaki şekilde verilmiştir. Değişken çiftleri nicel (sürekli ve kesikli) olduğu için Pearson korelasyon katsayılarını hesapladık.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen korelasyon katsayıları matris formatında aşağıda verilmiştir.
crim zn indus nox rm age
crim 1.0000000 -0.2004692 0.4065834 0.4209717 -0.2192467 0.3527343
zn -0.2004692 1.0000000 -0.5338282 -0.5166037 0.3119906 -0.5695373
indus 0.4065834 -0.5338282 1.0000000 0.7636514 -0.3916759 0.6447785
nox 0.4209717 -0.5166037 0.7636514 1.0000000 -0.3021882 0.7314701
rm -0.2192467 0.3119906 -0.3916759 -0.3021882 1.0000000 -0.2402649
age 0.3527343 -0.5695373 0.6447785 0.7314701 -0.2402649 1.0000000
dis -0.3796701 0.6644082 -0.7080270 -0.7692301 0.2052462 -0.7478805
rad 0.6255051 -0.3119478 0.5951293 0.6114406 -0.2098467 0.4560225
tax 0.5827643 -0.3145633 0.7207602 0.6680232 -0.2920478 0.5064556
ptratio 0.2899456 -0.3916785 0.3832476 0.1889327 -0.3555015 0.2615150
b -0.3850639 0.1755203 -0.3569765 -0.3800506 0.1280686 -0.2735340
lstat 0.4556215 -0.4129946 0.6037997 0.5908789 -0.6138083 0.6023385
medv -0.3883046 0.3604453 -0.4837252 -0.4273208 0.6953599 -0.3769546
dis rad tax ptratio b lstat
crim -0.3796701 0.6255051 0.5827643 0.2899456 -0.3850639 0.4556215
zn 0.6644082 -0.3119478 -0.3145633 -0.3916785 0.1755203 -0.4129946
indus -0.7080270 0.5951293 0.7207602 0.3832476 -0.3569765 0.6037997
nox -0.7692301 0.6114406 0.6680232 0.1889327 -0.3800506 0.5908789
rm 0.2052462 -0.2098467 -0.2920478 -0.3555015 0.1280686 -0.6138083
age -0.7478805 0.4560225 0.5064556 0.2615150 -0.2735340 0.6023385
dis 1.0000000 -0.4945879 -0.5344316 -0.2324705 0.2915117 -0.4969958
rad -0.4945879 1.0000000 0.9102282 0.4647412 -0.4444128 0.4886763
tax -0.5344316 0.9102282 1.0000000 0.4608530 -0.4418080 0.5439934
ptratio -0.2324705 0.4647412 0.4608530 1.0000000 -0.1773833 0.3740443
b 0.2915117 -0.4444128 -0.4418080 -0.1773833 1.0000000 -0.3660869
lstat -0.4969958 0.4886763 0.5439934 0.3740443 -0.3660869 1.0000000
medv 0.2499287 -0.3816262 -0.4685359 -0.5077867 0.3334608 -0.7376627
medv
crim -0.3883046
zn 0.3604453
indus -0.4837252
nox -0.4273208
rm 0.6953599
age -0.3769546
dis 0.2499287
rad -0.3816262
tax -0.4685359
ptratio -0.5077867
b 0.3334608
lstat -0.7376627
medv 1.0000000
Korelasyon katsayılarının kontrol edilmesi
Bu kısımda pearson korelasyon katsayılarının 0,80 üzerinde olup olmadığı kontrol edilmiş olup, buna ilişkin yazılan R kod bloğuna aşağıda yer verilmiştir.
kormatris<-cor(veri[,-4])
findCorrelation(kormatris, cutoff=0.8,names=TRUE, exact = TRUE)
Yukarıdaki R kod bloğunun run edilmesi ile elde edilen sonuç aşağıda verilmiştir. Tablodan tax değişkeninin korelasyon katsayısının tamamının 0.80’in üzerinde olduğu (r=0,92) olduğu görülmektedir. Bu değişken ilk modelde yer alacaktır ancak kurulacak ikinci modelde yer almayacaktır.
[1] "tax"
Nicel değişkenlerin normal dağılıma uyup uymadığının kontrol edilmesi
#Q-Q plot ile crim değişkeninin normal dağılıma uyumu incelenmiştir.
v1<-ggqqplot(veri$crim, ylab = "crim", color="red")
#Q-Q plot ile zn değişkeninin normal dağılıma uyumu incelenmiştir.
v2<-ggqqplot(veri$zn, ylab = "zn", color="red")
#Q-Q plot ile indus değişkeninin normal dağılıma uyumu incelenmiştir.
v3<-ggqqplot(veri$indus, ylab = "indus", color="red")
#Q-Q plot ile nox değişkeninin normal dağılıma uyumu incelenmiştir.
v4<-ggqqplot(veri$nox, ylab = "crim", color="red")
#Q-Q plot ile rm değişkeninin normal dağılıma uyumu incelenmiştir.
v5<-ggqqplot(veri$rm, ylab = "rm", color="red")
#Q-Q plot ile age değişkeninin normal dağılıma uyumu incelenmiştir.
v6<-ggqqplot(veri$age, ylab = "age", color="red")
#Q-Q plot ile dis değişkeninin normal dağılıma uyumu incelenmiştir.
v7<-ggqqplot(veri$dis, ylab = "dis", color="red")
#Q-Q plot ile rad değişkeninin normal dağılıma uyumu incelenmiştir.
v8<-ggqqplot(veri$rad, ylab = "rad", color="red")
#Q-Q plot ile tax değişkeninin normal dağılıma uyumu incelenmiştir.
v9<-ggqqplot(veri$tax, ylab = "tax", color="red")
#Q-Q plot ile ptratio değişkeninin normal dağılıma uyumu incelenmiştir.
v10<-ggqqplot(veri$ptratio, ylab = "ptratio", color="red")
#Q-Q plot ile b değişkeninin normal dağılıma uyumu incelenmiştir.
v11<-ggqqplot(veri$b, ylab = "b", color="red")
#Q-Q plot ile lstat değişkeninin normal dağılıma uyumu incelenmiştir.
v12<-ggqqplot(veri$lstat, ylab = "lstat", color="red")
#Q-Q plot ile medv değişkeninin normal dağılıma uyumu incelenmiştir.
v13<-ggqqplot(veri$medv, ylab = "medv", color="red")
ggarrange(v1,v2,v3,v4)#ilk dört değişken
ggarrange(v5,v6,v7,v8)#2. ilk dört değişken
ggarrange(v9,v10,v11,v12, v13)#3. ilk beş değişken
Yukarıdaki R kod bloğunun çalıştırılmasından sonra ilk gruba ait dört değişkeninin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafiği aşağıda verilmiştir.
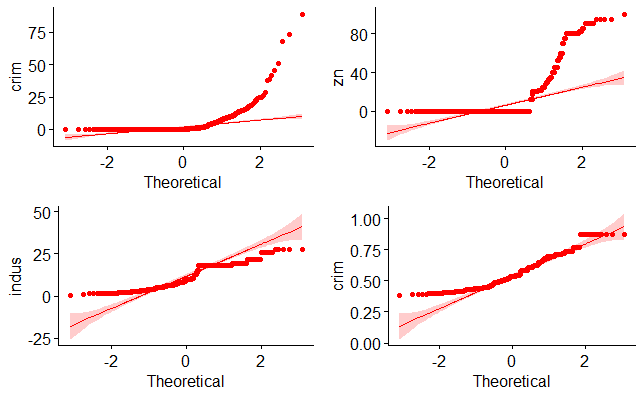
Yukarıdaki R kod bloğunun çalıştırılmasından sonra ikinci grup ilk dört değişkeninin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafiği aşağıda verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra üçüncü gruba ait ilk beş değişkeninin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafiği aşağıda verilmiştir.
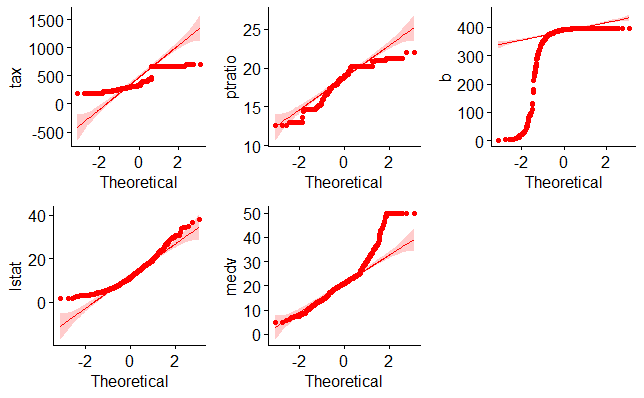
Çoklu regresyon modelinin kurulması
Kurulan çoklu regresyon modelinde bağımlı değişken medv, diğer değişkenler ise bağımsız olup, regresyon modeline ilişkin R kod bloğu aşağıda verilmiştir.
model1 <- glm(medv ~. , data = veri)
summ(model1)
#alternatif
model1 <- lm(medv ~. , data = veri)
summary(model1)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen regresyon model özeti aşağıda verilmiştir. Çıktıda yer verilen AIC (Akaike information criterion) parametresi kurulan tek bir modelin değerlendirilmesinde çok fazla anlam ifade etmemekle birlikte BIC (Akaike information criterion) parametresinde olduğu gibi ne kadar düşük olursa kurulan modelin o kadar gözlem verisine uyum sağladığını göstermektedir. Bu açıdan bakıldığında aslında bu iki parametrenin kurulan birden fazla modelin performansının değerlendirilmesinde kullanılması daha uygundur.
MODEL INFO:
Observations: 506
Dependent Variable: medv
Type: Linear regression
MODEL FIT:
χ²(13) = 31637.51, p = 0.00
Pseudo-R² (Cragg-Uhler) = 0.74
Pseudo-R² (McFadden) = 0.19
AIC = 3027.61, BIC = 3091.01
Standard errors: MLE
-------------------------------------------------
Est. S.E. t val. p
----------------- -------- ------ -------- ------
(Intercept) 36.46 5.10 7.14 0.00
crim -0.11 0.03 -3.29 0.00
zn 0.05 0.01 3.38 0.00
indus 0.02 0.06 0.33 0.74
chas1 2.69 0.86 3.12 0.00
nox -17.77 3.82 -4.65 0.00
rm 3.81 0.42 9.12 0.00
age 0.00 0.01 0.05 0.96
dis -1.48 0.20 -7.40 0.00
rad 0.31 0.07 4.61 0.00
tax -0.01 0.00 -3.28 0.00
ptratio -0.95 0.13 -7.28 0.00
b 0.01 0.00 3.47 0.00
lstat -0.52 0.05 -10.35 0.00
-------------------------------------------------
Estimated dispersion parameter = 22.52
Kurulan modelin özetinde eğer güven aralıklarını da verecek olursak aşağıdaki R kod bloğu ile bu mümkündür.
summ(model1, confint = TRUE, digits = 3)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde çoklu regresyon model çıktısına güven aralıkları ile birlikte aşağıda yer verilmiştir.
MODEL INFO:
Observations: 506
Dependent Variable: medv
Type: Linear regression
MODEL FIT:
χ²(13) = 31637.511, p = 0.000
Pseudo-R² (Cragg-Uhler) = 0.741
Pseudo-R² (McFadden) = 0.186
AIC = 3027.609, BIC = 3091.007
Standard errors: MLE
-----------------------------------------------------------------
Est. 2.5% 97.5% t val. p
----------------- --------- --------- --------- --------- -------
(Intercept) 36.459 26.457 46.462 7.144 0.000
crim -0.108 -0.172 -0.044 -3.287 0.001
zn 0.046 0.020 0.073 3.382 0.001
indus 0.021 -0.100 0.141 0.334 0.738
chas1 2.687 0.998 4.375 3.118 0.002
nox -17.767 -25.253 -10.280 -4.651 0.000
rm 3.810 2.991 4.629 9.116 0.000
age 0.001 -0.025 0.027 0.052 0.958
dis -1.476 -1.866 -1.085 -7.398 0.000
rad 0.306 0.176 0.436 4.613 0.000
tax -0.012 -0.020 -0.005 -3.280 0.001
ptratio -0.953 -1.209 -0.696 -7.283 0.000
b 0.009 0.004 0.015 3.467 0.001
lstat -0.525 -0.624 -0.425 -10.347 0.000
-----------------------------------------------------------------
Estimated dispersion parameter = 22.518
Regresyon denkleminin yazılması
Değişkenlerin coefficient (katsayı) tahminlerinden yola çıkarak 1 nolu çoklu doğrusal regresyon modelimizin denklemini yazalım.
Medv (y)= intercept + crim*x1 + zn*x2 + indus*x3 + chas1*x4 + nox*x5 + rm*x6 + age*x7 + dis*x8 + rad*x9 + tax*x10 + ptratio*x11 + b*x12 + lstat*x13
Şimdi yukarıda hesaplanan katsayıları denklemde yerine yazalım. Ancak denkleme sadece istatistiksel olarak anlamlı çıkan değişkenleri dahil edelim.
Medv (y)= 36.459 – 0.108*X1 + 0.046*x2 + 2.687*x4 – 17.767*x5 + 3.810*x6 – 1.476*x8 + 0.306*x9 – 0.012*x10 – 0.953*x11 + 0.009*x12 – 0.525*x13
Elde edilen denkleme göre çoklu doğrusal regresyon modelini şöyle yorumlayabiliriz.
1. crim değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini 0,108 kat azaltmaktadır.
2. zn değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini 0.046 kat artırmaktadır. Etkisi bağımlı değişken üzerinde yok denecek kadar azdır
3. chas katogorik değişkenindeki bir birimlik değişim 0 kategorisine göre bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini 2.687 kat artırmaktadır.
5. nox değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini -17.767 kat azaltmaktadır.
6. rm değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini 3.810 kat artırmaktadır.
7. dis değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini -1.476 kat azaltmaktadır.
8. rad değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini 0.306 kat artırmaktadır.
9. tax değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini -0.012 kat azaltmaktadır. Etkisi bağımlı değişken üzerinde yok denecek kadar azdır.
10. ptratio değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini -0.953 kat azaltmaktadır.
11. b değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini 0.009 kat artırmaktadır. Etkisi bağımlı değişken üzerinde yok denecek kadar azdır.
12. lstat değişkenindeki bir birimlik değişim bağımlı değişken olan medv (medyan ev fiyatlarını) değişkenini -0.525 kat azaltmaktadır.
13. zn değişkenindeki bir birimlik değişim ise medv (medyan ev fiyatlarını) değişkenini 0.046 artırmaktadır.
Regresyon modelinin raporlanması
Regresyon modelini kurduk ve özetini aldık. Şimdi de kurduğum bu regresyon modelini aşağıda yazdığım R kod bloğu yardımıyla raporlayalım ve xlsx uzantılı bir dosyaya yazdıralım.
export_summs(model1, scale = FALSE, to.file = "xlsx", file.name = "model1.xlsx")#aynı zamanda xlsx uzantılı dosyaya yazdırmak için
export_summs(model1, scale = FALSE, to.file = "docx", file.name = "model1.docx")
Yukarıdaki R kod bloğu çalıştırılması ile hem model xlsx dosyasına yazdırılmış hem de R konsolunda sonuçlarına ulaştık. Model rapor çıktısı aşağıda verilmiştir. Raporda parantez içinde yer alanlar standart hata (S.E)’yı göstermektedir.
─────────────────────────────────────────────────
Model 1
─────────────────────────
(Intercept) 36.46 ***
(5.10)
crim -0.11 **
(0.03)
zn 0.05 ***
(0.01)
indus 0.02
(0.06)
chas1 2.69 **
(0.86)
nox -17.77 ***
(3.82)
rm 3.81 ***
(0.42)
age 0.00
(0.01)
dis -1.48 ***
(0.20)
rad 0.31 ***
(0.07)
tax -0.01 **
(0.00)
ptratio -0.95 ***
(0.13)
b 0.01 ***
(0.00)
lstat -0.52 ***
(0.05)
─────────────────────────
N 506
AIC 3027.61
BIC 3091.01
Pseudo R2 0.74
─────────────────────────────────────────────────
*** p < 0.001; ** p < 0.01; * p < 0.05.
Şimdi de aynı kod bloğunun çalıştırılması ile raporun xlsx dosyasına yazdırılmış versiyonunu verelim. Aşağıdaki linkten raporun xlsx uzantılı versiyonunu indirebilirsiniz.
Kurulan modelin özeti alternatif olarak aşağıda yazılan R kod bloğunun çalıştırılması ile de elde edilebilir.
stargazer(model1, scale=F, type="text", digits=2)#fonksiyon içerisine out="....txt" yazarsınız özeti txt uzantılı olarak kaydetmek de mümkündür.
Yukarıdaki R kod bloğunun çalıştırılması ile elde edilen model özeti aşağıda verilmiştir.
===============================================
Dependent variable:
---------------------------
medv
-----------------------------------------------
crim -0.11***
(0.03)
zn 0.05***
(0.01)
indus 0.02
(0.06)
chas1 2.69***
(0.86)
nox -17.77***
(3.82)
rm 3.81***
(0.42)
age 0.001
(0.01)
dis -1.48***
(0.20)
rad 0.31***
(0.07)
tax -0.01***
(0.004)
ptratio -0.95***
(0.13)
b 0.01***
(0.003)
lstat -0.52***
(0.05)
Constant 36.46***
(5.10)
-----------------------------------------------
Observations 506
R2 0.74
Adjusted R2 0.73
Residual Std. Error 4.75 (df = 492)
F Statistic 108.08*** (df = 13; 492)
===============================================
Note: *p<0.1; **p<0.05; ***p<0.01
======
110.24
------
Değişkenlerin modeldeki nispi önem düzeyleri
Kurulan regresyon modelinde nispi önem ağrlıklarını (relative importances) hesaplamak için iki yöntem kullanılmış ve karşılaştırmalı olarak sunulmuştur. Kullanılan yöntemlerinden ilki lmg olup, regresörler arasındaki sıralamalara göre ortalama R ^ 2 katkısını ifade etmektedir. Diğer yöntem ise betasq olup, normalize edilmiş kare katsayını göstermektedir. Nispi önem ağırlıklarını hesaplamak için yazılan R kod bloğu aşağıda verilmiştir.
nispionem<-calc.relimp(model1, type = c("lmg","betasq"), rela = TRUE)
nispionem#lmg ve betasq yöntemleri kullanarak karşılaştırmalı olarak nispi önem ağırlıklarını vermek için
Yukarıdaki R kod bloğunun son satırı çalıştırılmasından sonra lmg ve betasq yöntemlerine göre bağımsız değişkenlerin nispi önem ağırlıkları aşağıda verilmiştir. Elde edilen bulgular en yüksek nispi önem ağırlığına sahip değişkenin lstat değişkeni olduğunu göstermektedir. Bu değişkeni sırasıyla rm ve ptratio değişkenleri izlemiştir.
Response variable: medv
Total response variance: 84.58672
Analysis based on 506 observations
13 Regressors:
crim zn indus chas nox rm age dis rad tax ptratio b lstat
Proportion of variance explained by model: 74.06%
Metrics are normalized to sum to 100% (rela=TRUE).
Relative importance metrics:
lmg betasq
crim 0.03669197 1.597789e-02
zn 0.03349910 2.169676e-02
indus 0.05101231 3.682211e-04
chas 0.02139033 8.620330e-03
nox 0.04511571 7.845783e-02
rm 0.25259867 1.326430e-01
age 0.02975151 7.028187e-06
dis 0.04087946 1.787074e-01
rad 0.03190385 1.314540e-01
tax 0.04967225 7.999602e-02
ptratio 0.10602348 7.875477e-02
b 0.03093651 1.337755e-02
lstat 0.27052485 2.599392e-01
Average coefficients for different model sizes:
1X 2Xs 3Xs 4Xs 5Xs
crim -0.41519028 -0.27876734 -0.21102769 -0.172845863 -0.14899982
zn 0.14213999 0.09177589 0.06926785 0.058187805 0.05208479
indus -0.64849005 -0.49907219 -0.39245035 -0.312711078 -0.25044986
chas 6.34615711 6.13625177 5.79137684 5.378363951 4.96039109
nox -33.91605501 -23.64184669 -17.74630522 -14.537764121 -12.99734886
rm 9.10210898 8.07541798 7.46905711 7.011233964 6.61054979
age -0.12316272 -0.07450317 -0.04834524 -0.033245015 -0.02390811
dis 1.09161302 0.10952005 -0.47255267 -0.833695790 -1.06499158
rad -0.40309540 -0.20593927 -0.08194586 0.001678813 0.06198805
tax -0.02556810 -0.02017034 -0.01665270 -0.014304609 -0.01271040
ptratio -2.15717530 -1.74062066 -1.52445277 -1.389315454 -1.29154159
b 0.03359306 0.02243776 0.01743324 0.014808955 0.01324295
lstat -0.95004935 -0.90871002 -0.86922333 -0.830576846 -0.79243771
6Xs 7Xs 8Xs 9Xs 10Xs
crim -0.13318972 -0.12244878 -0.11518841 -0.110479262 -0.107740227
zn 0.04841098 0.04611642 0.04473486 0.044039341 0.043909618
indus -0.19989046 -0.15740182 -0.12065007 -0.088070978 -0.058531713
chas 4.56663532 4.20812708 3.88683375 3.600046913 3.342756614
nox -12.49075417 -12.61748098 -13.12577086 -13.860628817 -14.730291533
rm 6.23447431 5.87015426 5.51253464 5.160160375 4.813205720
age -0.01774178 -0.01339689 -0.01012959 -0.007506479 -0.005261198
dis -1.21554565 -1.31379414 -1.37739662 -1.417937166 -1.443287731
rad 0.10808364 0.14515543 0.17645934 0.204220581 0.230033618
tax -0.01163317 -0.01094108 -0.01056128 -0.010452258 -0.010588444
ptratio -1.21468054 -1.15187362 -1.09982518 -1.056675250 -1.021201281
b 0.01221866 0.01149901 0.01096173 0.010537971 0.010185605
lstat -0.75484432 -0.71798862 -0.68210391 -0.647421018 -0.614154947
11Xs 12Xs 13Xs
crim -0.106584888 -0.106741334 -1.080114e-01
zn 0.044279575 0.045117684 4.642046e-02
indus -0.031119628 -0.005017834 2.055863e-02
chas 3.108982366 2.892438686 2.686734e+00
nox -15.684182425 -16.698441350 -1.776661e+01
rm 4.472316347 4.137922082 3.809865e+00
age -0.003220995 -0.001266585 6.922246e-04
dis -1.458920162 -1.468724058 -1.475567e+00
rad 0.255062878 0.280176177 3.060495e-01
tax -0.010953167 -0.011536415 -1.233459e-02
ptratio -0.992503316 -0.969873098 -9.527472e-01
b 0.009876605 0.009590626 9.311683e-03
lstat -0.582502652 -0.552645344 -5.247584e-01
Marjinal etki düzeylerinin hesaplanması
Marjinal etki düzeyi, tahmincilerin (bağımsız değişkenlerin) sonuç değişkeni üzerindeki etkisini tanımlamak için kullanılabilecek alternatif bir metriktir. Marjinal etkiler, bağımsız değişkendeki bir birim artışın oluşturduğu değişim olasılığını göstermektedir.
#Marjinal etki düzeyleri tablosu
margineffect= margins(model1)
# Summary of marginal effect
margineffect=summary(margineffect) %>% mutate_at(2:7, round, 3) %>% arrange(desc(AME))
formattable(margineffect)
#Marjinal etki düzeylerinin grafiği
mgrafik= margins(model1)
plot(mgrafik, main="Ortalama Marjinal Etki (AME) Düzeyleri Grafiği", ylab="AME", xlab="Faktörler")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen ortalama marjinal etki düzeyleri (AME) aşağıdaki tabloda verilmiştir.
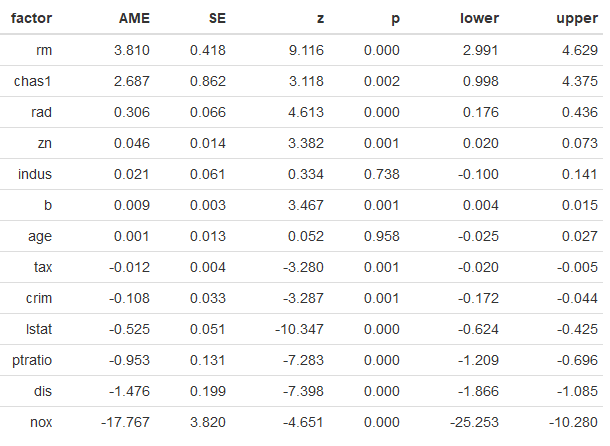
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen ortalama marjinal etki (AME) düzeylerinin grafiği ise aşağıda verilmiştir.

Alternatif: Değişkenlerin önem düzeyleri
n<-varImp(model1)
n<-rownames(n)
n<-n %>% as_tibble()
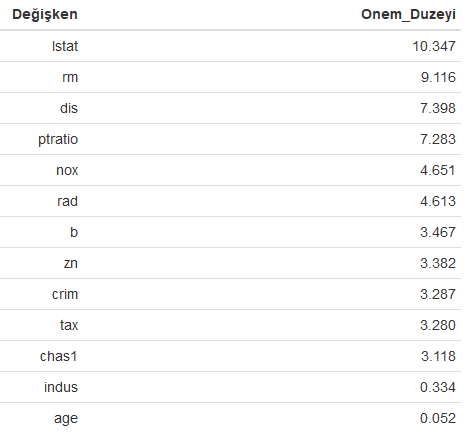
varImp(model1) %>% as_tibble() %>% rename("Onem_Duzeyi"=Overall) %>% add_column("Değişken"=n$value,.before="Onem_Duzeyi") %>% mutate_if(is.numeric, round, 3) %>% arrange(desc(Onem_Duzeyi)) %>% formattable()
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen modeldeki değişkenlerin önem düzeyleri büyükten küçüğe doğru aşağıdaki tabloda verilmiştir.
Tahmin edilen değerler ile test veri setindeki gözlem değerlerinin karşılaştırılması
tahmin<-predict(model1, veri)
karsilastirma<-tibble("Gözlem"=veri$medv, Tahmin=tahmin)
#ilk ve son 10 tahmin değerini gerçek değerle karşılaştırma
ilk10<-head(karsilastirma, 10) %>% rename("Gözlemİlk_10"="Gözlem", Tahminİlk_10=Tahmin) %>% mutate_if(is.numeric, round, 1)
son10<-tail(karsilastirma, 10) %>% rename("GözlemSon_10"="Gözlem", TahminSon_10=Tahmin) %>% mutate_if(is.numeric, round, 1)
formattable(cbind(Sıra=seq(1,10),ilk10, son10))
#sonuçların xlsx dokümanına yazdırılması
write_xlsx(karsilastirma, "karsilatirmasonuc.xlsx.")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra çoklu regresyon modelinden elde edilen ilk ve son 10 tahmin değerleri gözlem değerleri ile birlikte aşağıdaki tabloda karşılaştırmalı olarak verilmiştir.

Yukarıdaki R kod bloğundaki son kod satırının çalıştırılması ile kurulan modelden elde edilen elde edilen tahmin sonuçları ile veri setindeki gözlem değerleri karşılaştırmalı olarak xlsx dokümanında verilmiş olup, aşağıdaki linkten indirebilirsiniz.
Regresyon Hata parametreleri
Kurulan modele ait regresyon hata metriklerinin elde edilmesine yönelik yazılan R kod bloğu aşağıda verilmiştir.
tahmin<-predict(model1, veri)
regresyonmetrik<-tibble("Gözlem"=veri$medv, Tahmin=tahmin) %>% summarise(SSE=sse(Gözlem, Tahmin),MSE=mse(Gözlem, Tahmin),RMSE=rmse(Gözlem, Tahmin), MAE=mae(Gözlem, Tahmin), MAPE=mape(Gözlem, Tahmin)) %>% mutate_if(is.numeric, round, 1)
formattable(regresyonmetrik)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra kurulan modele ait hata parametre değerleri aşağıda verilmiştir.

2 Nolu Çoklu Regresyon Modelinin Kurulması
Daha önce belirtildiği üzere tax değişkenine ait korelasyon katsayısının 0,80’in üzerinde çıktığını bahsetmiştik. İki nolu modelde bu değişkeni çıkararak medyan konu fiyatları (medv) değişkenini tahmin edelim. Kurulan regresyon modeline ilişkin R kod bloğu aşağıda verilmiştir.
model2 <- glm(medv ~. , data = veri)
summ(model2)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen regresyon model özeti aşağıda verilmiştir.
MODEL INFO:
Observations: 506
Dependent Variable: medv
Type: Linear regression
MODEL FIT:
χ²(12) = 31395.25, p = 0.00
Pseudo-R² (Cragg-Uhler) = 0.74
Pseudo-R² (McFadden) = 0.18
AIC = 3036.55, BIC = 3095.73
Standard errors: MLE
-------------------------------------------------
Est. S.E. t val. p
----------------- -------- ------ -------- ------
(Intercept) 34.63 5.12 6.76 0.00
crim -0.11 0.03 -3.22 0.00
zn 0.04 0.01 2.69 0.01
indus -0.07 0.06 -1.21 0.23
chas1 3.03 0.86 3.51 0.00
nox -18.70 3.85 -4.86 0.00
rm 3.91 0.42 9.29 0.00
age -0.00 0.01 -0.05 0.96
dis -1.49 0.20 -7.39 0.00
rad 0.13 0.04 3.26 0.00
ptratio -0.99 0.13 -7.48 0.00
b 0.01 0.00 3.52 0.00
lstat -0.52 0.05 -10.20 0.00
-------------------------------------------------
Estimated dispersion parameter = 22.96
Model karşılaştırmaları
İlk olarak modelleri AIC ve BIC değerleri açısından karşılaştıralım. AIC ve BIC değerlerinin düşük olması tahmin edilen değerlerle gözlem verilerine uyum açısından istenen bir durum olduğu daha önce belirtilmişti. Elde edilen sonuçlar Model 1’in AIC ve BIC değerleri daha düşük olduğundan Model 2’ye göre daha iyi tahmin sonuçları ortaya koyduğu söylenebilir.
Şimdide R kod bloğu yazarak her iki modelin regresyon metriklerine birlikte bakalım.
tahmin<-predict(model1, veri)
regresyonmetrik<-tibble("Gözlem"=veri$medv, Tahmin=tahmin) %>% summarise(SSE=sse(Gözlem, Tahmin),MSE=mse(Gözlem, Tahmin),RMSE=rmse(Gözlem, Tahmin), MAE=mae(Gözlem, Tahmin), MAPE=mape(Gözlem, Tahmin)) %>% mutate_if(is.numeric, round, 2) %>% add_column(Model="Model 1", .before="SSE")
tahmin2<-predict(model2, veri[,-10])
regresyonmetrik2<-tibble("Gözlem"=veri$medv, Tahmin=tahmin2) %>% summarise(SSE=sse(Gözlem, Tahmin),MSE=mse(Gözlem, Tahmin),RMSE=rmse(Gözlem, Tahmin), MAE=mae(Gözlem, Tahmin), MAPE=mape(Gözlem, Tahmin)) %>% mutate_if(is.numeric, round, 2)%>% add_column(Model="Model 2", .before="SSE")
formattable(rbind(regresyonmetrik, regresyonmetrik2))
Yukarıdaki R kod bloğu çalıştırıldıktan sonra kurulan modellere ilişkin karşılatırmalı hata metrikleri aşağıdaki tabloda verilmiştir. Ortaya konulan bulgular AIC ve BIC parametrelerinde olduğu gibi 1 nolu model 2 nolu modele göre daha az hata üretmektedir. Dolayısıyla bu bulgulara bakarak 1 nolu modelin daha iyi olduğu ileri sürülebilir.

Anova testi ile her iki modeli karşılaştırma
Anova testi kullanılarak her iki model karşılaştırarak model performansları ortaya konulmuştur. Aşağıdaki R kod bloğu ile her iki model anova test edilerek modellerdeki iyileşmeler verilmiştir.
model1<-lm(medv ~. , data = veri)
model2<-lm(medv ~. , data = veri [,-10])
anova(model2, model1)
Yukarıdaki R kod bloğu çalıştırıldıktan sonra elde edilen model performansları aşağıda verilmiştir. Elde edilen bulgular istatistiksel olarak 1. modelin 2. modele göre daha iyi olduğunu göstermektedir. Anova testinde F rasyosu bize bu iyileşmeyi göstermektedir. Aşağıdaki raporda 1. modelde elde edilen toplam hata (RSS) 11079, 2. modelde elde edilen hata (RSS) ise 11321’dir. Görüleceği üzere 2. modelde hata da yüksektir. Sum of Sq ifadesi 11079-11321=-242.26 göstermektedir.
AAnalysis of Variance Table
Model 1: medv ~ crim + zn + indus + chas + nox + rm + age + dis + rad +
tax + ptratio + b + lstat
Model 2: medv ~ crim + zn + indus + chas + nox + rm + age + dis + rad +
ptratio + b + lstat
Res.Df RSS Df Sum of Sq F Pr(>F)
1 492 11079
2 493 11321 -1 -242.26 10.758 0.001112 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Her iki modelin birlikte raporlanması
Her iki model yazılan aşağıdaki R kod bloğu birlikte karşılaştırma sağlanabilmesi adına raporlanabilir. Kurulan her iki modelde bağımsız değişkenler bağımlı değişken olan medyan ev fiyatlarındaki varyansın % 74’ünü açıklamaktadır.
export_summs(model1,model2 scale = FALSE, results = 'asis')
Yukarıdaki R kod bloğu çalıştırılarak kurulan modellere ilişkin elde edilen karşılaştırmalı rapor aşağıda verilmiştir.
────────────────────────────────────────────────────
Model 1 Model 2
───────────────────────────────────
(Intercept) 36.46 *** 34.63 ***
(5.10) (5.12)
crim -0.11 ** -0.11 **
(0.03) (0.03)
zn 0.05 *** 0.04 **
(0.01) (0.01)
indus 0.02 -0.07
(0.06) (0.06)
chas1 2.69 ** 3.03 ***
(0.86) (0.86)
nox -17.77 *** -18.70 ***
(3.82) (3.85)
rm 3.81 *** 3.91 ***
(0.42) (0.42)
age 0.00 -0.00
(0.01) (0.01)
dis -1.48 *** -1.49 ***
(0.20) (0.20)
rad 0.31 *** 0.13 **
(0.07) (0.04)
tax -0.01 **
(0.00)
ptratio -0.95 *** -0.99 ***
(0.13) (0.13)
b 0.01 *** 0.01 ***
(0.00) (0.00)
lstat -0.52 *** -0.52 ***
(0.05) (0.05)
───────────────────────────────────
N 506 506
AIC 3027.61 3036.55
BIC 3091.01 3095.73
Pseudo R2 0.74 0.74
────────────────────────────────────────────────────
*** p < 0.001; ** p < 0.01; * p < 0.05.
Column names: names, Model 1, Model 2
Diagnostik Testler
Bu kısımda kurulan 1 nolu modelin regresyon varsayımları gözden geçirilecektir.
Artıkların normal dağılım gösterdiği varsayımı
library(broom)
diagnostiktest <- augment(model1)
plot(model1, 2)
#alternatif
ggqqplot(diagnostiktest$.resid, ylab = "Std. deviance residuals", color="red")
#alternatif
ggqqplot(model1$residuals, ylab = "Std. deviance residuals", color="blue")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen artıkların grafiği aşağıda verilmiştir. Grafikte normal dağılımı bozan değerler olduğu görülmektedir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen artıkların alternatif grafiği aşağıda verilmiştir.

Çoklu doğrusallık varsayımı
Bu kısımda aşağıda yazdığım R kod bloğu ile varyans enflasyon faktörü (VIF) ve tolerans seviyeleri hesaplanmıştır.
varyanseflasyonfaktoru<-VIF(model1)
vif<-tibble(Değişken=names(VIF(model1)), VIF=varyanseflasyonfaktoru) %>% arrange(desc(VIF)) %>% add_column(sıra=1:13, .before="Değişken") %>% mutate(Tolerans=1/VIF) %>% mutate_if(is.numeric, round,2)
formattable(vif,
list(formatter(
"span", style = ~ style(color = "grey",font.weight = "bold")),
`VIF` = color_bar("#00CED1"),
`Tolerans` = color_bar("#00FF7F")
))
Yukarıdaki R kod bloğunun çalıştırılması ile hesaplanan varyans enflasyon faktörü (VIF) ve tolerans seviyeleri aşağıdaki tabloda verilmiştir. Daha önce VIF değerinin 10’dan büyük olmaması ve tolerans seviyesinin ise 0,1’in altına düşmemesi gerektiğini söylemiştir. Elde edilen bulgular VIF ve tolerans değerlerinin kabul edilebilir sınırlar içerisinde kaldığını göstermektedir.

Etkin değerlerin bulunması
Burada etkin değerlerden kasıt Cook’un mesafesi kullanılarak uç (extreme) değerlerin bulunmasıdır. Aşağıda yazılan R kod bloğu ile normal dağılıma uymayan 10 değer Cook’un mesafesi kullanılarak grafiğe yansıtılmıştır.
plot(model1, 4, id.n = 10)
#değerleri de verecek olursak satırlarla birlikte
top10<-diagnostiktest[, -c(15:19,21)] %>%
top_n(10, wt = .cooksd) %>% mutate_if(is.numeric, round,3)
as.matrix(top10)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra Cook’un mesafesini gösteren grafik en yüksek 10 değeri ile birlikte aşağıda verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra Cook’un mesafesini gösteren tablo matris formatında en yüksek 10 gözlem değeri ile birlikte aşağıda verilmiştir.
medv crim zn indus chas nox rm age dis rad
[1,] "23.7" " 0.290" "0" "10.59" "0" "0.489" "5.412" " 9.8" "3.587" " 4"
[2,] "21.9" " 3.474" "0" "18.10" "1" "0.718" "8.780" " 82.9" "1.905" "24"
[3,] "27.5" " 4.556" "0" "18.10" "0" "0.718" "3.561" " 87.9" "1.613" "24"
[4,] "23.1" "13.522" "0" "18.10" "0" "0.631" "3.863" "100.0" "1.511" "24"
[5,] "50.0" " 4.898" "0" "18.10" "0" "0.631" "4.970" "100.0" "1.332" "24"
[6,] "50.0" " 5.670" "0" "18.10" "1" "0.631" "6.683" " 96.8" "1.357" "24"
[7,] "50.0" " 6.539" "0" "18.10" "1" "0.631" "7.016" " 97.5" "1.202" "24"
[8,] "50.0" " 9.232" "0" "18.10" "0" "0.631" "6.216" "100.0" "1.169" "24"
[9,] "50.0" " 8.267" "0" "18.10" "1" "0.668" "5.875" " 89.6" "1.130" "24"
[10,] "17.9" "18.811" "0" "18.10" "0" "0.597" "4.628" "100.0" "1.554" "24"
tax ptratio b lstat .cooksd
[1,] "277" "18.6" "348.93" "29.55" "0.043"
[2,] "666" "20.2" "354.55" " 5.29" "0.069"
[3,] "666" "20.2" "354.70" " 7.12" "0.067"
[4,] "666" "20.2" "131.42" "13.33" "0.045"
[5,] "666" "20.2" "375.52" " 3.26" "0.166"
[6,] "666" "20.2" "375.33" " 3.73" "0.055"
[7,] "666" "20.2" "392.05" " 2.96" "0.044"
[8,] "666" "20.2" "366.15" " 9.53" "0.043"
[9,] "666" "20.2" "347.88" " 8.88" "0.094"
[10,] "666" "20.2" " 28.79" "34.37" "0.050"
Alternatif olarak aşağıdaki R kod bloğunda car paketini kullanarak da uç değerleri (outliers) belirleyebiliriz. Burada Bonferroni düzeltilmiş outlier test’ini kullanıyoruz.
library(car)
outlierTest(model1,10)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen uç değerler aşağıda verilmiştir. Bu uç değerler modelden çıkarılırsa daha iyi sonuçlar elde edilmesi mümkündür. Aşağıda solda yer alan numaralar veri setindeki satır numaralarını göstermektedir.
rstudent unadjusted p-value Bonferroni p
369 5.907411 6.4998e-09 3.2889e-06
372 5.491079 6.4185e-08 3.2478e-05
373 5.322247 1.5617e-07 7.9020e-05
370 3.807609 1.5808e-04 7.9987e-02
413 3.546859 4.2724e-04 2.1618e-01
365 -3.457995 5.9153e-04 2.9932e-01
371 3.367841 8.1712e-04 4.1346e-01
187 3.032720 2.5518e-03 NA
366 2.956763 3.2586e-03 NA
162 2.859666 4.4214e-03 NA
Modelden uç değerlerler çıkarılarak tekrar kurulmuştur. Aşağıda yazılan kod bloğu ile düzeltilmiş R karenin yükseldiği görülmektedir. Bu da bize bağımsız değişkenlerin bağımlı değişkendeki varyansı açıklama oranının yükseldiği göstermektedir.
n<-outlierTest(model1,10)
#küçükten büyüğe doğru satır numaralarını sıralayacak olursak
satir<-sort(names(n$rstudent))#satırlar küçükten büyüğe doğru
#sonuçlar:[1] 162 187 365 366 369 370 371 372 373 413
mmodelucyok<-lm(medv ~. , data = veri[-satir, ])
summary(mmodelucyok)
Yukarıdaki R kod bloğunun çalıştırılması ile uç değerlerin çıkarılmasından sonra elde edilen yeni model özeti aşağıda verilmiştir. Elde edilen bulgular uç değerler çıkartıldığında modelin bağımlı değişkendeki varyansları açıklama gücünün % 73’ten % 81’e çıktığını göstermektedir.
Call:
lm(formula = medv ~ ., data = veri[-satir, ])
Residuals:
Min 1Q Median 3Q Max
-10.2400 -2.2328 -0.5165 1.7342 18.8761
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.430819 4.299288 4.752 2.66e-06 ***
crim -0.093021 0.026329 -3.533 0.000450 ***
zn 0.033153 0.011037 3.004 0.002806 **
indus 0.014326 0.049452 0.290 0.772175
chas1 1.532408 0.728125 2.105 0.035844 *
nox -11.953077 3.091782 -3.866 0.000126 ***
rm 5.467502 0.366377 14.923 < 2e-16 ***
age -0.026620 0.010737 -2.479 0.013506 *
dis -1.175980 0.160622 -7.321 1.04e-12 ***
rad 0.203448 0.053560 3.799 0.000164 ***
tax -0.012625 0.003014 -4.189 3.33e-05 ***
ptratio -0.895774 0.105524 -8.489 2.60e-16 ***
b 0.010020 0.002170 4.617 5.01e-06 ***
lstat -0.303462 0.044016 -6.894 1.70e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.793 on 482 degrees of freedom
Multiple R-squared: 0.8142, Adjusted R-squared: 0.8092
F-statistic: 162.5 on 13 and 482 DF, p-value: < 2.2e-16
Her iki modeli, model 1 ile uç değerlerinin çıkarılarak kurgulandığı yeni modeli karşılaştırmalı olarak aşağıda yazılan R kod bloğu ile de vererek resmi daha yakından görmüş oluruz.
stargazer(model1,mmodelucyok, scale=F, type="text", digits=2)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra bahsedilen her iki karşılaştırmalı olarak aşağıda verilmiştir.
=====================================================================
Dependent variable:
-------------------------------------------------
medv
(1) (2)
---------------------------------------------------------------------
crim -0.11*** -0.09***
(0.03) (0.03)
zn 0.05*** 0.03***
(0.01) (0.01)
indus 0.02 0.01
(0.06) (0.05)
chas1 2.69*** 1.53**
(0.86) (0.73)
nox -17.77*** -11.95***
(3.82) (3.09)
rm 3.81*** 5.47***
(0.42) (0.37)
age 0.001 -0.03**
(0.01) (0.01)
dis -1.48*** -1.18***
(0.20) (0.16)
rad 0.31*** 0.20***
(0.07) (0.05)
tax -0.01*** -0.01***
(0.004) (0.003)
ptratio -0.95*** -0.90***
(0.13) (0.11)
b 0.01*** 0.01***
(0.003) (0.002)
lstat -0.52*** -0.30***
(0.05) (0.04)
Constant 36.46*** 20.43***
(5.10) (4.30)
---------------------------------------------------------------------
Observations 506 496
R2 0.74 0.81
Adjusted R2 0.73 0.81
Residual Std. Error 4.75 (df = 492) 3.79 (df = 482)
F Statistic 108.08*** (df = 13; 492) 162.46*** (df = 13; 482)
=====================================================================
Note: *p<0.1; **p<0.05; ***p<0.01
======
110.24
------
Hataların bağımsızlığı testi
Kurulan regresyon modelinde hataların bağımsızlığını testi için literatürde genellikle Durbin Watson istatistiğinin kullanıldığı görülmektedir. Regresyon modellerinde hatalar bağımsız olması gerekli olup, Durbin Watson değerinin 1 ile 3 arasında olması istenmektedir. Aşağıda yazılan R kod bloğu ile 1 nolu modelin Durbin Watson istatistiği verilmiştir.
lmtest::dwtest(model1)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen Durbin Watson istatistiği aşağıdaki verilmiştir. Elde edilen bulgular Durbin-Watson test istatistiği değerinin referans değerler aralığında kaldığını ve bu sonucun istatistiksel olarak anlamlı olduğunu göstermektedir.
Durbin-Watson test
data: model1
DW = 1.0784, p-value < 2.2e-16
alternative hypothesis: true autocorrelation is greater than 0
Yapılan bu çalışma ile özellikle veri bilimi (data science) ile ilgilenen akademi ve saha çalışanlarına önemli bir katkı sunulacağı düşünülmektedir.
Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
- https://web.stanford.edu/~hastie/TALKS/boost.pdf
- https://iq.opengenus.org/types-of-boosting-algorithms/
- https://tevfikbulut.com/2020/05/21/r-programlama-diliyle-regresyon-problemlerinin-cozumunde-rastgele-orman-algoritmasi-uzerine-bir-vaka-calismasi-a-case-study-on-random-forest-rf-algorithm-in-solving-regression-problems-with-r-progr/
- https://www.stat.berkeley.edu/~breiman/Using_random_forests_V3.1.pdf
- https://www.stat.berkeley.edu/~breiman/RandomForests/
- https://stats.idre.ucla.edu/r/library/r-library-introduction-to-bootstrapping/
- https://stanford.edu/~shervine/l/tr/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks
- http://uzalcbs.org/wp-content/uploads/2016/11/2012_082.pdf
- http://www.ub.edu/stat/docencia/EADB/bagging.html
- https://people.cs.pitt.edu/~milos/courses/cs2750-Spring04/lectures/class23.pdf
- https://www.google.com/search?q=underfitting+and+overfitting&source=lnms&tbm=isch&sa=X&ved=2ahUKEwiI1onvyNvpAhVSQMAKHfYyC28Q_AUoAXoECBAQAw&biw=1366&bih=604#imgrc=m5WcPcAqdpCwEM
- Webb G.I. (2011) Overfitting. In: Sammut C., Webb G.I. (eds) Encyclopedia of Machine Learning. Springer, Boston, MA
- https://www.memorial.com.tr/saglik-rehberleri/biyopsi-nedir-ve-nasil-yapilir/
- https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
- Andriyas, S. and McKee, M. (2013). Recursive partitioning techniques for modeling irrigation behavior. Environmental Modelling & Software, 47, 207–217.
- Chan, J. C. W. and Paelinckx, D. (2008). Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sensing of Environment, 112(6), 2999–3011.
- Chrzanowska, M., Alfaro, E., and Witkowska, D. (2009). The individual borrowers recognition:Single and ensemble trees. Expert Systems with Applications, 36(2), 6409–6414.
- De Bock, K. W., Coussement, K., and Van den Poel, D. (2010). Ensemble classification based on generalized additive models. Computational Statistics & Data Analysis, 54(6), 1535–1546.
- De Bock, K. W. and Van den Poel, D. (2011). An empirical evaluation of rotation-based ensemble classifiers for customer churn prediction. Expert Systems with Applications, 38(10), 12293–12301.
- Fan, Y., Murphy, T.B., William, R. and Watson G. (2009). digeR: GUI tool for analyzing 2D DIGE data. R package version 1.2.
- Garcia-Perez-de-Lema, D., Alfaro-Cortes, E., Manzaneque-Lizano, M. and Banegas-Ochovo, R. (2012). Strategy, competitive factors and performance in small and medium enterprise (SMEs).
- African Journal of Business Management, 6(26), 7714–7726.
- Gonzalez-Rufino, E., Carrion, P., Cernadas, E., Fernandez-Delgado, M. and Dominguez-Petit, R.(2013). Exhaustive comparison of colour texture features and classification methods to discriminate cells categories in histological images of fish ovary. Pattern Recognition, 46, 2391–2407.
- Krempl, G. and Hofer, V. (2008). Partitioner trees: combining boosting and arbitrating. In: Okun, O., Valentini, G. (eds.) Proc. 2nd Workshop Supervised and Unsupervised Ensemble Methods and Their Applications, Patras, Greece, 61–66.
- Torgo, Luis, Data Mining With R. Second Edition.
- https://www.akira.ai/glossary/gradient-boosting/
- http://www.ccs.neu.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf
- Breiman, L. (June 1997). “Arcing The Edge” (PDF). Technical Report 486. Statistics Department, University of California, Berkeley.
- https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/
- https://dergipark.org.tr/tr/download/article-file/219865
- Discovering Statistics Using SPSS (2009), Field, A.
- https://www.jmp.com/en_ch/statistics-knowledge-portal/what-is-multiple-regression/fitting-multiple-regression-model.html
- https://marcfbellemare.com/
- https://www.statisticshowto.com/variance-inflation-factor/
- https://www.rdocumentation.org/packages/psych/versions/1.9.12.31/topics/cor.plot
- https://www.rdocumentation.org/packages/caret/versions/6.0-86/topics/findCorrelation
- https://tevfikbulut.com/2020/07/04/rda-binary-lojistik-regresyon-uzerine-bir-vaka-calismasi-a-case-study-on-binary-logistic-regression-in-r/
- https://cran.r-project.org/web/packages/relaimpo/relaimpo.pdf