Lojistik regresyon analizi yöntemlerinden biri olan multinominal lojistik regresyon analiz yöntemi, bağımlı değişkenin ya da cevap değişkeninin 2’den fazla kategoriye sahip olduğu durumlarda bağımlı değişkenler (dependent variables) ile bağımsız değişken veya değişkenler (independent variables) arasındaki ilişkiyi ortaya koyan regresyon analiz yöntemidir. Burada bağımlı değişkenin multinominal olmasından kasıt kategorik değişkenin ikiden fazla cevap seçeneği olduğu anlaşılmalıdır. Multinominal kategorik değişken tipi ile binary (iki: binomial ya da dikotomik) değişken tipi karıştırılmamalıdır. Veri tipleri kendi içerisinde 4 farklı alt sınıfta ele alınabilir. Bu veri tipleri Şekil 1’de verilmiştir.
Şekil 1: Veri Tipleri
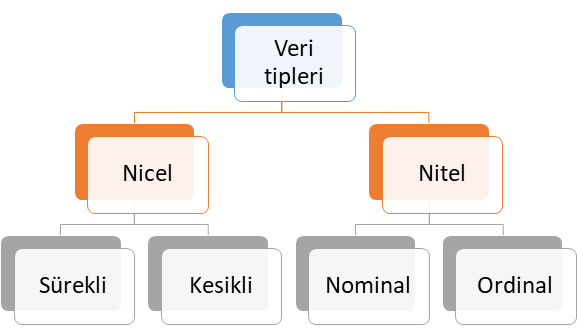
Nicel Veri (Quantitative Data)
Şekil 1’de verilen sunulan nicel veri tipi ölçülebilen veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek verelim.
- Sürekli veri: Tam sayı ile ifade edilmeyen veri tipi olup, zaman, sıcaklık, beden kitle endeksi, boy ve ağırlık ölçümleri bu veri tipine örnek verilebilir.
- Kesikli veri: Tam sayı ile ifade edilebilen veri tipi olup, bu veri tipine proje sayısı, popülasyon sayısı, öğrenci sayısı örnek verilebilir.
Nitel Veri (Qualitative Data)
Şekil 1’de verilen sunulan nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek vererek ele alalım.
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek regresyon analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Eğer cevap değişkeni nitel ise aslında sınıflandırma problemini çözmek için analizi kullanıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisi tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemi de değiştirecektir. Bağımlı (dependent) değişkenin tipine göre kullanılan regresyon analiz yöntemleri Şekil 2’de genel hatlarıyla verilmiştir.
Şekil 2: Cevap Değişkeninin Veri Tipine Göre Regresyon Analiz Yöntemleri
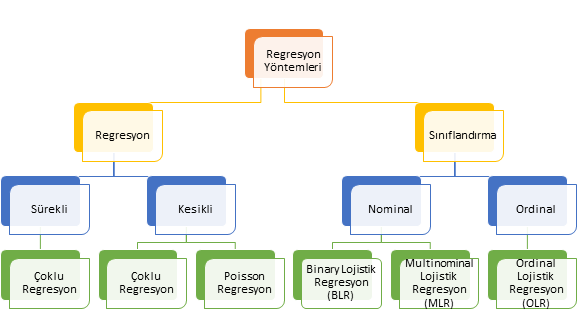
Bu kapsamda cevap değişkeni (bağımlı değişken) üzerinden uygulamalı olarak multinominal lojistik regresyon analizi yapılacaktır. Analizde R programlama dili kullanılarak analiz adımları R kod bloklarında adım adım verilmiştir.
1972 yılından bu yana Genel Sosyal Araştırma (GSS) kapsamında, Amerikan toplumunun tutumları, davranışları ve bunlardaki eğilimleri ve değişimleri belirli aralıklarla izlenerek yüz yüze (face to face) yapılan görüşmelerle veri toplanmaktadır. Araştırmada kullanılan veri seti de Genel Sosyal Araştırma (GSS) kapsamında üretilen 2018 yılı verilerini içermektedir.
Veri seti stata uzantılı olarak aşağıda verilen resmi web sitesinden indirilmiştir. Analizde kullanılan veri setini dta (stata) uzantılı olarak aşağıdaki linkten indirebilirsiniz.
http://gss.norc.org/Documents/stata/2018_stata.zip
Veri setinde belirlenen değişkenlerle Amerikan toplumunun siyasi eğilimleri özgün bu çalışmaya tahmin edilmeye çalışılmıştır. Veri setindeki gözlem sayısı 2348, değişken sayısı ise 9’dur. Veri setinde değişkenler şöyledir:
- age: Cevaplayıcının yaşını göstermekte olup, değişken tipi nicel ve kesiklidir.
- sex: Cevaplayıcının cinsiyetini göstermekte olup, değişken tipi nitel ve dikotomik kategoriktir.
- wrkstat: Cevaplayıcının çalışma durumunu göstermekte olup, değişken tipi nitel ve kategoriktir. Cevap kategorileri 1’den 10’a kadar kodlanmıştır.
- region: Cevaplayıcının bulunduğu bölgeyi göstermekte olup, değişken tipi nitel ve kategoriktir. Cevap kategorileri 1’den 9’a kadar kodlanmıştır.
- marital: Cevaplayıcının bulunduğu medeni durumunu göstermekte olup, değişken tipi nitel ve kategoriktir. Cevap kategorileri 1’den 5’e kadar kodlanmıştır.
- childs: Cevaplayıcının sahip olduğu çocuk sayısını göstermekte olup, değişken tipi nicel ve kesiklidir.
- degree: Cevaplayıcının eğitim düzeyini göstermekte olup, değişken tipi nitel ve kategoriktir. Cevap kategorileri 1’den 5’e kadar kodlanmıştır.
- relig: Cevaplayıcının dini görüşünü göstermekte olup, değişken tipi nitel ve kategoriktir. Cevap kategorileri 1’den 13’e kadar kodlanmıştır.
- polviews: Cevaplayıcının siyasi görüşünü göstermekte olup, değişken tipi nitel ve kategoriktir. Cevap kategorileri 1’den 7’ye kadar kodlanmıştır.
Yüklenecek R kütüphaneleri
gereklikütüphaneler<-sapply(c("dplyr","tibble","tidyr","ggplot2","formattable","ggthemes","readr","readxl","xlsx","ggpubr", "gghighlight","pastecs","gridExtra","officer","flextable","ggstance", "jtools", "huxtable", "aod", "DescTools", "readstata13", "nnet","foreign","stargazer","margins", "reshape2","writexl","car", "nnet", "caret", "forcats"), require, character.only = TRUE)
gereklikütüphaneler
Ver setinin okunması
Bu kısımda ilk olarak csv uzantılı veri seti kaynağından okunmuş, ardından veri setindeki ilk 10 gözlem verilmiştir.
#stata (dta) uzantılı veri setinin okunması
df <- read.dta13("GSS2018.dta") %>% select(age, sex,wrkstat,region,marital,childs, degree, relig, polviews)
formattable(head(df,10))
#veri setinin "xlsx" uzantılı dosyaya yazdırılması
write_xlsx(df, "analizsurveydata2018.xlsx")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki ilk 10 gözlem aşağıdaki tabloda verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasıyla veri seti xlsx uzantılı dosyaya yazdırılmış olup, aşağıdaki linkten veri setini indirebilirsiniz.
Keşifsel Veri Analizi
Veri setinin yapısı
Aşağıdaki kod bloğu ile veri setinin yapısı gözden geçirilmiştir.
glimpse(veri)
#alternatif
str (veri)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen veri setinin yapısına ilişkin istatistikler aşağıda verilmiştir. Görüleceği üzere veri 2348 gözlem ve 9 değişkenden oluşmaktadır. Modelde bağımlı değişken olarak yer alan değişken “polviews” olup, kalan değişkenler bağımsız (predictor) değişkenlerdir.
Observations: 2,348
Variables: 9
$ age <int> 43, 74, 42, 63, 71, 67, 59, 43, 62, 55, 59, 34, 61, 44,...
$ sex <fct> male, female, male, female, male, female, female, male,...
$ wrkstat <fct> "temp not working", "retired", "working fulltime", "wor...
$ region <fct> new england, new england, new england, new england, new...
$ marital <fct> never married, separated, married, married, divorced, w...
$ childs <int> 0, 3, 2, 2, 0, 2, 6, 0, 4, 2, 2, 3, 2, 2, 2, 4, 0, 2, 2...
$ degree <fct> junior college, high school, bachelor, bachelor, gradua...
$ relig <fct> christian, catholic, none, protestant, catholic, cathol...
$ polviews <fct> conservative, NA, slghtly conservative, moderate, extrm...
Veri setinden eksik gözlemlerin (NAs) çıkarılması
tamveri<-df %>% drop_na()
Değişken bazlı görselleştirme
#veri setindeki ilk 3 değişkenin görselleştirilmesi
tamveri[,1:3] %>% explore_all()
#veri setindeki 4,5 ve 6. değişkenlerin görselleştirilmesi
tamveri[,4:6] %>% explore_all()
#veri setindeki 7 ve 8. değişkenlerin görselleştirilmesi
tamveri[,c(7,8)] %>% explore_all()
#veri setindeki 9. değişkenlerin görselleştirilmesi
tamveri %>% explore(polviews)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen değişken bazlı grafikler aşağıda verilmiştir. İlk olarak veri setindeki ilk 3 değişken görselleştirilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen veri setindeki 4, 5 ve 6. değişken görselleştirilmiştir.
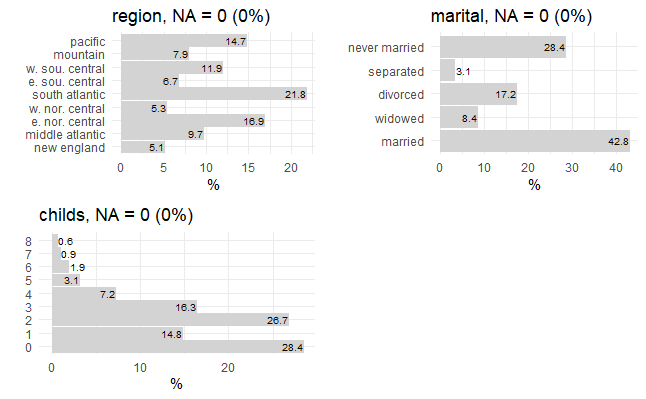
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen veri setindeki 7 ve 8. değişkenler görselleştirilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen veri setindeki 9. değişken görselleştirilmiştir.

Bağımlı değişkene göre gruplandırılmış görselleştirme
#cinsiyete göre siyasi görüşler
agg <- count(tamveri, sex, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(sex~.)+
theme(axis.text.x = element_text(angle = 90))
#alternatif grafik: üst üste bağımlı değişken seviyelerinin eklenmesi
ggplot(agg) +
geom_col(aes(x = sex, y = n, fill = polviews), position = "fill")


#yaş gruplarına göre siyasi tercihleri
yas<-tamveri %>% mutate(agegroup=cut(tamveri$age,breaks=5,dig.lab=2, labels=c("19-32","33-46","47-61","62-75","76-89")))
agg <- count(yas, agegroup, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(agegroup~.)+
theme(axis.text.x = element_text(angle = 90))

#çalışma durumuna göre siyasi tercihleri
agg <- count(tamveri, wrkstat, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(~wrkstat)+
theme(axis.text.x = element_text(angle = 90))

#Bölgeye göre siyasi tercihleri
agg <- count(tamveri, region, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(region~.)+
theme(axis.text.x = element_text(angle = 90))

#Medeni duruma göre siyasi tercihleri
agg <- count(tamveri, marital, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(marital~.)+
theme(axis.text.x = element_text(angle = 90))

#Çocuk sayısına göre siyasi tercihleri
agg <- count(tamveri, childs, polviews)
ggplot(agg)+
geom_col(aes(x = n, y = polviews, fill = polviews))+
facet_wrap(childs~.)+
theme(axis.text.x = element_text(angle = 90))

#Eğitim düzeyine göre siyasi tercihleri
agg <- count(tamveri, degree, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(degree~.)+
theme(axis.text.x = element_text(angle = 90))

#Dini görüşüne düzeyine göre siyasi tercihleri
agg <- count(tamveri, relig, polviews)
ggplot(agg)+
geom_col(aes(x = polviews, y = n, fill = polviews))+
facet_wrap(relig~.)+
theme(axis.text.x = element_text(angle = 90))

Bağımlı değişkene göre gruplandırılmış görselleştirme: Waffle grafik örneği
count(tamveri, polviews)
waffle(c("extremely liberal"=round(121/10,0), liberal=round(275/10,0), "slightly liberal"=round(254/10,0), moderate=round(844/10,0), "slghtly conservative"=round(283/10,0),conservative=round(351/10,0),"extrmly conservative"=round(97/10,0)), rows = 10, title = "Siyasi Görüşlerin Dağılımı")

#kadın ve erkeklerin siyasi görüşlerinin dağılımı
say<-count(tamveri, sex, polviews)
filter(say, sex=="female")#erkek için filter(say, sex=="male")
iron(waffle(c("extremely liberal"=round(65/10,0), liberal=round(161/10,0), "slightly liberal"=round(130/10,0), moderate=round(483/10,0), "slghtly conservative"=round(152/10,0),conservative=round(182/10,0),"extrmly conservative"=round(51/10,0)), rows = 6,glyph_size = 6,
title = "Siyasi Görüşlerin Dağılımı: Kadın"),
waffle(c("extremely liberal"=round(56/10,0), liberal=round(114/10,0), "slightly liberal"=round(124/10,0), moderate=round(361/10,0), "slghtly conservative"=round(131/10,0),conservative=round(169/10,0),"extrmly conservative"=round(46/10,0)), rows = 6,glyph_size = 6,
title = "Siyasi Görüşlerin Dağılımı:Erkek"))

Kategorik değişkenlerin sıklıkları (n) ve yüzdeleri (%)
tamveri %>% describe_num(age)
tamveri %>% describe(sex)
tamveri %>% describe(wrkstat)
tamveri %>% describe(region)
tamveri %>% describe(marital)
tamveri %>% describe(childs)
tamveri %>% describe(degree)
tamveri %>% describe(relig)
tamveri %>% describe(polviews)
Yaş (age) değişkenine göre tanımlayıcı istatistikler
variable = age
type = integer
na = 0 of 2 225 (0%)
unique = 72
min|max = 18 | 89
q05|q95 = 22 | 79
q25|q75 = 34 | 63
median = 48
mean = 48.97124
Cinsiyet (sex) değişkenine göre tanımlayıcı istatistikler
variable = sex
type = factor
na = 0 of 2 225 (0%)
unique = 2
male = 1 001 (45%)
female = 1 224 (55%)
Çalışma durumu (wrkstat) değişkenine göre tanımlayıcı istatistikler
variable = wrkstat
type = factor
na = 0 of 2 225 (0%)
unique = 8
working fulltime = 1 080 (48.5%)
working parttime = 250 (11.2%)
temp not working = 50 (2.2%)
unempl, laid off = 72 (3.2%)
retired = 428 (19.2%)
school = 76 (3.4%)
keeping house = 225 (10.1%)
other = 44 (2%)
Bölge (region) değişkenine göre tanımlayıcı istatistikler
variable = region
type = factor
na = 0 of 2 225 (0%)
unique = 9
new england = 113 (5.1%)
middle atlantic = 216 (9.7%)
e. nor. central = 377 (16.9%)
w. nor. central = 118 (5.3%)
south atlantic = 485 (21.8%)
e. sou. central = 150 (6.7%)
w. sou. central = 264 (11.9%)
mountain = 175 (7.9%)
pacific = 327 (14.7%)
Medeni durum (marital) değişkenine göre tanımlayıcı istatistikler
variable = marital
type = factor
na = 0 of 2 225 (0%)
unique = 5
married = 953 (42.8%)
widowed = 188 (8.4%)
divorced = 382 (17.2%)
separated = 69 (3.1%)
never married = 633 (28.4%)
Çocuk sayısı (childs) değişkenine göre tanımlayıcı istatistikler
variable = childs
type = integer
na = 0 of 2 225 (0%)
unique = 9
0 = 632 (28.4%)
1 = 329 (14.8%)
2 = 595 (26.7%)
3 = 363 (16.3%)
4 = 160 (7.2%)
5 = 69 (3.1%)
6 = 42 (1.9%)
7 = 21 (0.9%)
8 = 14 (0.6%)
Eğitim düzeyi (degree) değişkenine göre tanımlayıcı istatistikler
variable = degree
type = factor
na = 0 of 2 225 (0%)
unique = 5
lt high school = 230 (10.3%)
high school = 1 115 (50.1%)
junior college = 188 (8.4%)
bachelor = 450 (20.2%)
graduate = 242 (10.9%)
Dini görüş (relig) değişkenine göre tanımlayıcı istatistikler
variable = relig
type = factor
na = 0 of 2 225 (0%)
unique = 13
protestant = 1 099 (49.4%)
catholic = 465 (20.9%)
jewish = 38 (1.7%)
none = 512 (23%)
other = 31 (1.4%)
buddhism = 19 (0.9%)
hinduism = 8 (0.4%)
other eastern = 1 (0%)
moslem/islam = 15 (0.7%)
orthodox-christian = 6 (0.3%)
Siyasi görüş (polviews) değişkenine göre tanımlayıcı istatistikler
variable = polviews
type = factor
na = 0 of 2 225 (0%)
unique = 7
extremely liberal = 121 (5.4%)
liberal = 275 (12.4%)
slightly liberal = 254 (11.4%)
moderate = 844 (37.9%)
slghtly conservative = 283 (12.7%)
conservative = 351 (15.8%)
extrmly conservative = 97 (4.4%)
Bağımsız değişkenlerin bağımlı değişkene göre sıklıkları (n) ve yüzdeleri
Bu kısımda bağımsız değişkenlerin bağımlı değişken olan siyasi görüş (polviews) değişkenine göre sıklıkları (n) ve yüzdeleri verilmiştir. Aşağıdaki R kod bloğunda her çift değişkene ilişkin bu istatistikler sırasıyla verilmiş, kod bloğundan sonra ise değişken çiftlerine ilişkin ilk 10 gözlem tablolara yansıtılmıştır.
yas<-tamveri %>% mutate(agegroup=cut(tamveri$age,breaks=5,dig.lab=2, labels=c("19-32","33-46","47-61","62-75","76-89")))
yt<-yas %>% group_by(agegroup,polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde))#%>% slice(yüzde, n = 10)
formattable(head(yt,10))
#cinsiyet (sex)
cinsiyet<-tamveri %>% group_by(sex, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde)) #%>% slice(yüzde, n = 10)
formattable(head(cinsiyet,10))
#çalışma durumu (wrkstat)
cd<-tamveri %>% group_by(wrkstat, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde)) #%>% slice(yüzde, n = 10)
formattable(head(cd,10))
#bölge (region)
rg<-tamveri %>% group_by(region, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde))#%>% slice(yüzde, n = 10)
formattable(head(rg,10))
#medeni durum (marital)
md<-tamveri %>% group_by(marital, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde))
formattable(head(md,10))
#çocuk sayısı (childs)
cs<-tamveri %>% group_by(childs, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde))
formattable(head(cs,10))
#eğitim düzeyi (degree)
ed<-tamveri %>% group_by(degree, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde))
formattable(head(ed,10))
#dini görüş (relig)
dg<-tamveri %>% group_by(relig, polviews) %>% summarise(n=n())%>% mutate("yüzde"=round(n/sum(n)*100,1))%>% arrange(desc(yüzde))
formattable(head(dg,10))
Yaş (kategorize edilmiş) değişkenine göre siyasi görüşler

Cinsiyet (sex) değişkenine göre siyasi görüşler

Çalışma durumu (wrkstat) değişkenine göre siyasi görüşler
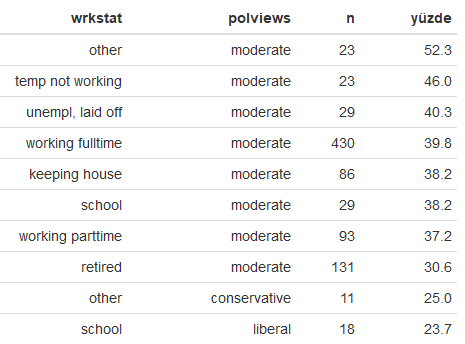
Bölge (region) değişkenine göre siyasi görüşler

Medeni durum (marital) değişkenine göre siyasi görüşler

Çocuk sayısı (childs) değişkenine göre siyasi görüşler
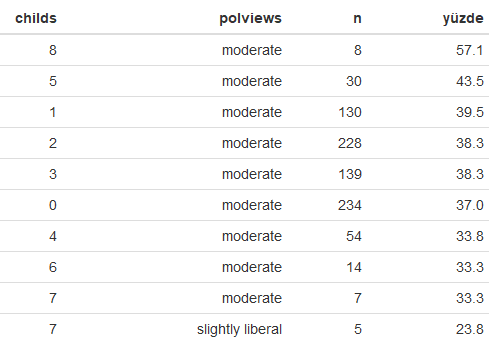
Eğitim düzeyi (degree) değişkenine göre siyasi görüşler

Dini görüş (relig) değişkenine göre siyasi görüşler
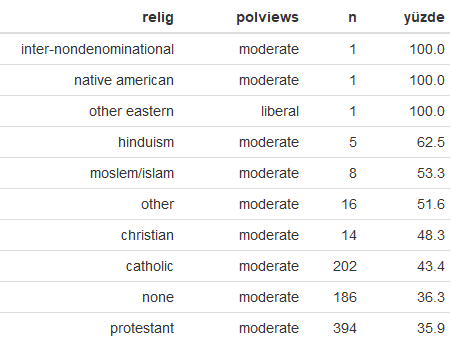
Değişkenler arasındaki korelasyonun hesaplanması
Kategorik değişkenlerin korelasyon katsayılarını hesaplamak için yazılan R kod bloğu aşağıdadır. Değişkenler arasındaki korelasyonu hesaplamak için Kikare ve Anova testleri kullanılmıştır. Korelasyon katsayısı hesaplanacak her iki değişkenin de nitel ve nominal olmasından dolayı Kikare, korelasyon katsayısı hesaplanacak değişkenlerden biri nicel kesikli ve diğeri nominal olduğundan Anova testleri yapılmıştır. Korelasyon katsayısı hesaplanacak değişkenlerden biri ordinal (sıralı) olsaydı bu durumda Spearman korelasyon (SpearmanRho) katsayısının hesaplanması gerekecekti. Diğer taraftan, eğer her iki değişken nicel (sürekli ve kesikli) olsaydı bu durumda Pearson korelasyon katsayısını hesaplayacaktık.
df1<-tamveri %>% droplevels()
#Kikare Testleri
p<-data.frame(lapply(df1[,-1], function(x) chisq.test(table(x,df1$polviews), simulate.p.value = TRUE)$p.value))
pvalue<-p %>% as_tibble() %>% pivot_longer(cols = sex:polviews, names_to="Degisken", values_to = "p") %>% mutate(Sonuc=ifelse(p<0.05,"Anlamlı", "Anlamlı Değil")) %>% mutate_if(is.numeric, round, 4)
chi<-data.frame(lapply(df1[,-1], function(x) chisq.test(table(x,df1$polviews), simulate.p.value = TRUE)$statistic))
chivalue<-chi %>% as_tibble() %>% pivot_longer(cols = sex:polviews, names_to="Degisken", values_to = "Kikare Test İstatistiği")%>% mutate_if(is.numeric, round, 2)
formattable(cbind(chivalue, pvalue[,-1]))
#Anova testi
#Veri tipi nicel kesikli olan bir değişken ile nominal veri tipine sahip değişken arasındaki ilişki ortaya konulduğundan Anova testi kullanılmıştır.
anova<-summary(aov(df1$age~df1$polviews))
anova
Yukarıdaki R kod bloğunun çalıştırılmasından sonra nominal veri tipine sahip değişkenlerin Kikare test istatistikleri aşağıdaki tabloda verilmiştir.
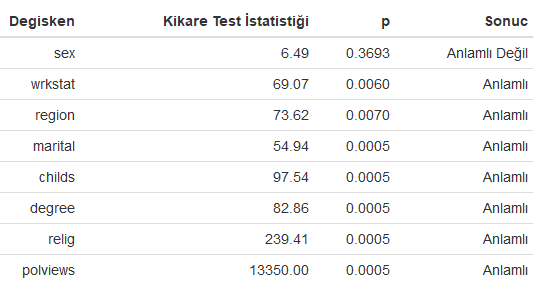
Yukarıdaki R kod bloğunun son satırında veri tipi nicel kesikli olan bir değişken ile nominal veri tipine sahip değişken arasındaki ilişki Anova testi ile ortaya konulmuş olup, sonuçlar aşağıda verilmiştir. Elde edilen bulgular age (yaş) değişkeni ile siyasi görüş arasında istatistiksel olarak anlamlı bir fark olduğunu göstermektedir.
Df Sum Sq Mean Sq F value Pr(>F)
df1$polviews 6 18004 3000.6 9.505 2.46e-10 ***
Residuals 2218 700197 315.7
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Nicel kesikli değişkenin normal dağılıma uyup uymadığının kontrol edilmesi
#Q-Q plot ile yaş değişkeninin normal dağılıma uyumu incelenmiştir.
ggqqplot(df1$age, ylab = "age", color="red")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra kesikli yaş (age) değişkeninin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafiği aşağıda verilmiştir.

Multinominal lojistik regresyon (MLR) modelinin oluşturulması
#olağandışı seviyelerin dışarıda bırakılması
tamveri<-tamveri %>% droplevels()
#Referan Kategorisi Oluşturma
tamveri$polviews2= relevel(tamveri$polviews, ref = "moderate")
tamveri
#Multinominal lojistik regresyon modelinin kurulması
mnmodel<-multinom(polviews2 ~ ., data=tamveri[,-9])
summary(mnmodel)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde multinominal lojistik regresyon model çıktısına aşağıda yer verilmiştir. Çıktıda yer verilen AIC (Akaike information criterion) parametresi kurulan tek bir modelin değerlendirilmesinde çok fazla anlam ifade etmemekle birlikte BIC (Akaike information criterion) parametresinde olduğu gibi ne kadar düşük olursa kurulan modelin o kadar gözlem verisine uyum sağladığını göstermektedir. Bu açıdan bakıldığında aslında bu iki parametrenin kurulan birden fazla modelin performansının değerlendirilmesinde kullanılması daha uygundur.
# weights: 280 (234 variable)
initial value 4329.650082
iter 10 value 3831.869309
iter 20 value 3664.489568
iter 30 value 3583.538601
iter 40 value 3574.274551
iter 50 value 3572.174882
iter 60 value 3570.652143
iter 70 value 3570.015918
iter 80 value 3569.720026
iter 90 value 3569.629772
iter 100 value 3569.593444
final value 3569.593444
stopped after 100 iterations
Call:
multinom(formula = polviews2 ~ ., data = tamveri[, -9])
Coefficients:
(Intercept) age sexfemale
extremely liberal -1.781055 0.005910691 -0.1333435
liberal -1.221537 0.002270619 0.1618255
slightly liberal -2.201346 -0.001389145 -0.1942267
slghtly conservative -1.156245 0.007939849 -0.1221374
conservative -1.907110 0.020809416 -0.2710894
extrmly conservative -2.795112 0.024111685 -0.1799307
wrkstatworking parttime wrkstattemp not working
extremely liberal 0.4588744 0.7519384
liberal 0.3868059 -1.5356292
slightly liberal -0.1584033 -0.8047907
slghtly conservative -0.1421631 0.1367354
conservative 0.4450416 -0.2253727
extrmly conservative 0.1740380 -0.7799903
wrkstatunempl, laid off wrkstatretired wrkstatschool
extremely liberal 0.74371035 0.46069782 0.3741055
liberal 0.55439226 0.55837113 0.6985156
slightly liberal -0.07994692 0.40385492 -0.1067726
slghtly conservative -0.02156486 0.06982105 0.2061969
conservative -0.07487960 0.17601685 -0.1283045
extrmly conservative -0.23313938 0.03959420 0.2835348
wrkstatkeeping house wrkstatother regionmiddle atlantic
extremely liberal 0.6853264 -0.7188634 0.01074032
liberal 0.1750060 0.1817457 -0.04034211
slightly liberal 0.2212480 -1.6536568 0.37296325
slghtly conservative -0.1545760 -1.4130541 -0.52427178
conservative 0.3797224 0.2306858 0.25323521
extrmly conservative 0.1912571 -1.2323626 0.69383354
regione. nor. central regionw. nor. central
extremely liberal -0.25404993 -1.194124729
liberal -0.32520490 -0.691807051
slightly liberal 0.53354844 0.231318101
slghtly conservative 0.09977572 -0.009891193
conservative 0.12340841 0.007035935
extrmly conservative 0.28179743 0.912692010
regionsouth atlantic regione. sou. central
extremely liberal -0.1358998 -0.2015682
liberal -0.5708286 -0.2922345
slightly liberal 0.2811713 0.7635301
slghtly conservative -0.2275224 -0.1726452
conservative 0.2988351 0.2678516
extrmly conservative 0.5741333 0.4550126
regionw. sou. central regionmountain regionpacific
extremely liberal -0.42650996 -0.09817787 0.0373986
liberal -0.50956245 -0.66829266 -0.0174256
slightly liberal 0.32129965 0.64376764 0.3833209
slghtly conservative 0.03881327 -0.31662255 -0.5504044
conservative 0.31174426 0.25843852 0.2372300
extrmly conservative 0.19145088 -0.48667751 0.5706989
maritalwidowed maritaldivorced maritalseparated
extremely liberal -0.07011156 0.08209546 0.42415246
liberal -0.18462234 -0.24046203 -0.21630928
slightly liberal 0.20439901 0.10404778 0.15159236
slghtly conservative -0.40363303 -0.36305074 -0.16856326
conservative -0.77914907 -0.62345753 -0.30536149
extrmly conservative -0.97263232 -0.18171354 -0.03363137
maritalnever married childs degreehigh school
extremely liberal 0.06472947 -0.084127078 -0.8748119
liberal -0.05189592 -0.075530020 -0.4295016
slightly liberal 0.43263316 0.015616245 0.2852313
slghtly conservative -0.30005125 -0.021040642 0.3220330
conservative -0.27704987 0.006577674 0.1975295
extrmly conservative -0.45602523 -0.079193655 -0.1769595
degreejunior college degreebachelor degreegraduate
extremely liberal -1.1832487 -0.02676944 0.2704660
liberal -0.2226313 0.39224324 0.9735811
slightly liberal 0.3494094 0.95399223 0.8097130
slghtly conservative 0.1323961 0.55525103 0.6328583
conservative 0.2727731 0.48194094 0.3352982
extrmly conservative -0.4099729 -0.85835109 0.2178098
religcatholic religjewish relignone religother
extremely liberal -1.43925263 0.728170247 0.8567975 -10.3273872
liberal -0.37279618 0.992652090 0.8647175 0.7327783
slightly liberal -0.01359356 -0.622900777 0.2971319 -0.2099243
slghtly conservative -0.14023655 -0.941110243 -0.5740601 -0.6073292
conservative -0.38400936 0.001007363 -0.8000609 -2.0197220
extrmly conservative -0.53719058 -0.812113026 -1.0571556 -9.6322742
religbuddhism relighinduism religother eastern
extremely liberal 1.8525294 -10.9666421 -1.724592
liberal 1.6925155 -0.5523906 15.249595
slightly liberal 1.2089028 -0.6896704 -1.335510
slghtly conservative -7.9315793 -12.1433213 -1.224771
conservative 0.3793666 -12.6426342 -2.451906
extrmly conservative -7.4214176 -11.5256348 -2.012006
religmoslem/islam religorthodox-christian
extremely liberal -10.5995933 -6.7326504
liberal -0.3737873 -7.8583228
slightly liberal -0.2483495 0.5506598
slghtly conservative -11.1283531 0.8097191
conservative -0.2645441 0.1686029
extrmly conservative -10.0526416 -6.6225117
religchristian relignative american
extremely liberal 0.13357335 -1.073439
liberal -0.47233178 -3.343673
slightly liberal -1.33302959 -5.646808
slghtly conservative -1.00222797 -6.578869
conservative 0.04962471 -5.251041
extrmly conservative -0.52576354 -3.867512
religinter-nondenominational
extremely liberal -2.633177
liberal -5.351359
slightly liberal -4.194009
slghtly conservative -5.734080
conservative -7.643212
extrmly conservative -3.799506
Std. Errors:
(Intercept) age sexfemale
extremely liberal 0.7233285 0.008957709 0.2126684
liberal 0.5213076 0.006624797 0.1534045
slightly liberal 0.5921547 0.006665665 0.1524650
slghtly conservative 0.5228057 0.006202656 0.1470326
conservative 0.5123799 0.005659438 0.1389007
extrmly conservative 0.8848568 0.009407843 0.2306779
wrkstatworking parttime wrkstattemp not working
extremely liberal 0.3323578 0.5107674
liberal 0.2385692 0.7661197
slightly liberal 0.2634735 0.6302954
slghtly conservative 0.2489135 0.4150855
conservative 0.2121887 0.4784841
extrmly conservative 0.3600841 1.0432543
wrkstatunempl, laid off wrkstatretired wrkstatschool
extremely liberal 0.5298788 0.3585109 0.5432450
liberal 0.3859357 0.2630175 0.3472929
slightly liberal 0.4215255 0.2625651 0.4121903
slghtly conservative 0.4058658 0.2419826 0.4304514
conservative 0.4226209 0.2203254 0.5106840
extrmly conservative 0.7613984 0.3499976 0.7766461
wrkstatkeeping house wrkstatother regionmiddle atlantic
extremely liberal 0.3457320 1.0526695 0.5202780
liberal 0.2732873 0.5254631 0.3560433
slightly liberal 0.2597759 1.0335050 0.4388225
slghtly conservative 0.2679951 0.7530973 0.3923364
conservative 0.2295483 0.3992324 0.3823219
extrmly conservative 0.3949556 1.0492660 0.6900124
regione. nor. central regionw. nor. central
extremely liberal 0.4984969 0.8481745
liberal 0.3398264 0.4676760
slightly liberal 0.4110672 0.4967742
slghtly conservative 0.3315777 0.3992429
conservative 0.3584127 0.4304242
extrmly conservative 0.6642710 0.7100160
regionsouth atlantic regione. sou. central
extremely liberal 0.4753587 0.5959194
liberal 0.3333234 0.4125389
slightly liberal 0.4101605 0.4538988
slghtly conservative 0.3309178 0.4044922
conservative 0.3458008 0.4072637
extrmly conservative 0.6383835 0.7303768
regionw. sou. central regionmountain regionpacific
extremely liberal 0.5455188 0.5344561 0.4856008
liberal 0.3713177 0.3976170 0.3297321
slightly liberal 0.4355096 0.4398608 0.4181391
slghtly conservative 0.3472286 0.3930438 0.3638416
conservative 0.3651717 0.3917122 0.3632049
extrmly conservative 0.6894718 0.8434987 0.6645007
maritalwidowed maritaldivorced maritalseparated
extremely liberal 0.4291298 0.2967404 0.5359200
liberal 0.3085405 0.2224439 0.4611628
slightly liberal 0.3034937 0.2178886 0.4502206
slghtly conservative 0.2860078 0.2015107 0.4239529
conservative 0.2607239 0.1907283 0.3798894
extrmly conservative 0.4618231 0.2883806 0.5718139
maritalnever married childs degreehigh school
extremely liberal 0.2802580 0.07315676 0.3142326
liberal 0.2015505 0.05449600 0.2538245
slightly liberal 0.2055867 0.05198222 0.2799284
slghtly conservative 0.2046726 0.04957249 0.2645797
conservative 0.1923968 0.04450023 0.2319102
extrmly conservative 0.3412632 0.07532249 0.3465538
degreejunior college degreebachelor degreegraduate
extremely liberal 0.5151006 0.3492843 0.3999911
liberal 0.3431002 0.2797062 0.3089430
slightly liberal 0.3654581 0.3057678 0.3628079
slghtly conservative 0.3536759 0.2963213 0.3393943
conservative 0.3046753 0.2640001 0.3149962
extrmly conservative 0.4966326 0.4741018 0.4521798
religcatholic religjewish relignone religother
extremely liberal 0.4212281 0.6271805 0.2327484 1.480395e-05
liberal 0.2184262 0.4673383 0.1799625 4.716166e-01
slightly liberal 0.1932956 0.7845526 0.1859720 6.509197e-01
slghtly conservative 0.1741356 0.7794009 0.2063630 6.495092e-01
conservative 0.1684722 0.5056191 0.2057652 1.043551e+00
extrmly conservative 0.2820126 1.0689695 0.3793453 3.154641e-05
religbuddhism relighinduism religother eastern
extremely liberal 0.7995995940 8.029968e-06 5.419618e-09
liberal 0.6931823829 9.013806e-01 7.576152e-08
slightly liberal 0.7282224050 1.126501e+00 4.301253e-09
slghtly conservative 0.0003205968 4.313696e-06 3.684150e-09
conservative 0.7854453653 3.620553e-06 2.219957e-09
extrmly conservative 0.0002137204 5.227826e-06 6.483847e-09
religmoslem/islam religorthodox-christian
extremely liberal 1.000699e-05 0.0005659433
liberal 8.328414e-01 0.0003234143
slightly liberal 8.186326e-01 1.2500144651
slghtly conservative 1.106865e-05 1.0274835968
conservative 7.062654e-01 1.2392106117
extrmly conservative 1.131282e-05 0.0005891459
religchristian relignative american
extremely liberal 0.7873163 2.755389e-03
liberal 0.7796096 2.406257e-04
slightly liberal 1.0490001 5.704922e-05
slghtly conservative 0.7711007 2.435787e-05
conservative 0.4840948 5.890693e-05
extrmly conservative 1.0569571 2.680461e-04
religinter-nondenominational
extremely liberal 6.497791e-04
liberal 6.951759e-05
slightly liberal 1.638623e-04
slghtly conservative 5.006574e-05
conservative 1.433041e-05
extrmly conservative 3.624374e-04
Residual Deviance: 7139.187
AIC: 7607.187
Yukarıdaki sonuçlar aşağıdaki R kod bloğu ile raporlanmak istenirse katsayılar ve standart hatanın olduğu bir tablo edilmesi de mümkündür.
stargazer(mnmodel, type="text", out="mnmodel.txt")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen model özet tablosu aşağıda verilmiştir.
================================================================================================================================
Dependent variable:
---------------------------------------------------------------------------------------------------
extremely liberal liberal slightly liberal slghtly conservative conservative extrmly conservative
(1) (2) (3) (4) (5) (6)
--------------------------------------------------------------------------------------------------------------------------------
age 0.006 0.002 -0.001 0.008 0.021*** 0.024**
(0.009) (0.007) (0.007) (0.006) (0.006) (0.009)
sexfemale -0.133 0.162 -0.194 -0.122 -0.271* -0.180
(0.213) (0.153) (0.152) (0.147) (0.139) (0.231)
wrkstatworking parttime 0.459 0.387 -0.158 -0.142 0.445** 0.174
(0.332) (0.239) (0.263) (0.249) (0.212) (0.360)
wrkstattemp not working 0.752 -1.536** -0.805 0.137 -0.225 -0.780
(0.511) (0.766) (0.630) (0.415) (0.478) (1.043)
wrkstatunempl, laid off 0.744 0.554 -0.080 -0.022 -0.075 -0.233
(0.530) (0.386) (0.422) (0.406) (0.423) (0.761)
wrkstatretired 0.461 0.558** 0.404 0.070 0.176 0.040
(0.359) (0.263) (0.263) (0.242) (0.220) (0.350)
wrkstatschool 0.374 0.699** -0.107 0.206 -0.128 0.284
(0.543) (0.347) (0.412) (0.430) (0.511) (0.777)
wrkstatkeeping house 0.685** 0.175 0.221 -0.155 0.380* 0.191
(0.346) (0.273) (0.260) (0.268) (0.230) (0.395)
wrkstatother -0.719 0.182 -1.654 -1.413* 0.231 -1.232
(1.053) (0.525) (1.034) (0.753) (0.399) (1.049)
regionmiddle atlantic 0.011 -0.040 0.373 -0.524 0.253 0.694
(0.520) (0.356) (0.439) (0.392) (0.382) (0.690)
regione. nor. central -0.254 -0.325 0.534 0.100 0.123 0.282
(0.498) (0.340) (0.411) (0.332) (0.358) (0.664)
regionw. nor. central -1.194 -0.692 0.231 -0.010 0.007 0.913
(0.848) (0.468) (0.497) (0.399) (0.430) (0.710)
regionsouth atlantic -0.136 -0.571* 0.281 -0.228 0.299 0.574
(0.475) (0.333) (0.410) (0.331) (0.346) (0.638)
regione. sou. central -0.202 -0.292 0.764* -0.173 0.268 0.455
(0.596) (0.413) (0.454) (0.404) (0.407) (0.730)
regionw. sou. central -0.427 -0.510 0.321 0.039 0.312 0.191
(0.546) (0.371) (0.436) (0.347) (0.365) (0.689)
regionmountain -0.098 -0.668* 0.644 -0.317 0.258 -0.487
(0.534) (0.398) (0.440) (0.393) (0.392) (0.843)
regionpacific 0.037 -0.017 0.383 -0.550 0.237 0.571
(0.486) (0.330) (0.418) (0.364) (0.363) (0.665)
maritalwidowed -0.070 -0.185 0.204 -0.404 -0.779*** -0.973**
(0.429) (0.309) (0.303) (0.286) (0.261) (0.462)
maritaldivorced 0.082 -0.240 0.104 -0.363* -0.623*** -0.182
(0.297) (0.222) (0.218) (0.202) (0.191) (0.288)
maritalseparated 0.424 -0.216 0.152 -0.169 -0.305 -0.034
(0.536) (0.461) (0.450) (0.424) (0.380) (0.572)
maritalnever married 0.065 -0.052 0.433** -0.300 -0.277 -0.456
(0.280) (0.202) (0.206) (0.205) (0.192) (0.341)
childs -0.084 -0.076 0.016 -0.021 0.007 -0.079
(0.073) (0.054) (0.052) (0.050) (0.045) (0.075)
degreehigh school -0.875*** -0.430* 0.285 0.322 0.198 -0.177
(0.314) (0.254) (0.280) (0.265) (0.232) (0.347)
degreejunior college -1.183** -0.223 0.349 0.132 0.273 -0.410
(0.515) (0.343) (0.365) (0.354) (0.305) (0.497)
degreebachelor -0.027 0.392 0.954*** 0.555* 0.482* -0.858*
(0.349) (0.280) (0.306) (0.296) (0.264) (0.474)
degreegraduate 0.270 0.974*** 0.810** 0.633* 0.335 0.218
(0.400) (0.309) (0.363) (0.339) (0.315) (0.452)
religcatholic -1.439*** -0.373* -0.014 -0.140 -0.384** -0.537*
(0.421) (0.218) (0.193) (0.174) (0.168) (0.282)
religjewish 0.728 0.993** -0.623 -0.941 0.001 -0.812
(0.627) (0.467) (0.785) (0.779) (0.506) (1.069)
relignone 0.857*** 0.865*** 0.297 -0.574*** -0.800*** -1.057***
(0.233) (0.180) (0.186) (0.206) (0.206) (0.379)
religother -10.327*** 0.733 -0.210 -0.607 -2.020* -9.632***
(0.00001) (0.472) (0.651) (0.650) (1.044) (0.00003)
religbuddhism 1.853** 1.693** 1.209* -7.932*** 0.379 -7.421***
(0.800) (0.693) (0.728) (0.0003) (0.785) (0.0002)
relighinduism -10.967*** -0.552 -0.690 -12.143*** -12.643*** -11.526***
(0.00001) (0.901) (1.127) (0.00000) (0.00000) (0.00001)
religother eastern -1.725*** 15.250*** -1.336*** -1.225*** -2.452*** -2.012***
(0.000) (0.00000) (0.000) (0.000) (0.000) (0.000)
religmoslem/islam -10.600*** -0.374 -0.248 -11.128*** -0.265 -10.053***
(0.00001) (0.833) (0.819) (0.00001) (0.706) (0.00001)
religorthodox-christian -6.733*** -7.858*** 0.551 0.810 0.169 -6.623***
(0.001) (0.0003) (1.250) (1.027) (1.239) (0.001)
religchristian 0.134 -0.472 -1.333 -1.002 0.050 -0.526
(0.787) (0.780) (1.049) (0.771) (0.484) (1.057)
relignative american -1.073*** -3.344*** -5.647*** -6.579*** -5.251*** -3.868***
(0.003) (0.0002) (0.0001) (0.00002) (0.0001) (0.0003)
religinter-nondenominational -2.633*** -5.351*** -4.194*** -5.734*** -7.643*** -3.800***
(0.001) (0.0001) (0.0002) (0.0001) (0.00001) (0.0004)
Constant -1.781** -1.222** -2.201*** -1.156** -1.907*** -2.795***
(0.723) (0.521) (0.592) (0.523) (0.512) (0.885)
--------------------------------------------------------------------------------------------------------------------------------
Akaike Inf. Crit. 7,607.187 7,607.187 7,607.187 7,607.187 7,607.187 7,607.187
================================================================================================================================
Note: *p<0.1; **p<0.05; ***p<0.01
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen modelin özetini word dosyası olarak aşağıdaki linkten indirebilirsiniz.
Odds Rasyolarının (OR) raporlanması
oddratio<-exp(coef(mnmodel))
stargazer(mnmodel, type="text", coef=list(oddratio), p.auto=FALSE, out="mnmodelor.txt")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen üstel beta (OR) model özet tablosu aşağıda verilmiştir.
=======================================================================================================================================
Dependent variable:
----------------------------------------------------------------------------------------------------------
extremely liberal liberal slightly liberal slghtly conservative conservative extrmly conservative
(1) (2) (3) (4) (5) (6)
---------------------------------------------------------------------------------------------------------------------------------------
age 1.006 1.002 0.999 1.008 1.021*** 1.024**
(0.009) (0.007) (0.007) (0.006) (0.006) (0.009)
sexfemale 0.875 1.176 0.823 0.885 0.763* 0.835
(0.213) (0.153) (0.152) (0.147) (0.139) (0.231)
wrkstatworking parttime 1.582 1.472 0.854 0.867 1.561** 1.190
(0.332) (0.239) (0.263) (0.249) (0.212) (0.360)
wrkstattemp not working 2.121 0.215** 0.447 1.147 0.798 0.458
(0.511) (0.766) (0.630) (0.415) (0.478) (1.043)
wrkstatunempl, laid off 2.104 1.741 0.923 0.979 0.928 0.792
(0.530) (0.386) (0.422) (0.406) (0.423) (0.761)
wrkstatretired 1.585 1.748** 1.498 1.072 1.192 1.040
(0.359) (0.263) (0.263) (0.242) (0.220) (0.350)
wrkstatschool 1.454 2.011** 0.899 1.229 0.880 1.328
(0.543) (0.347) (0.412) (0.430) (0.511) (0.777)
wrkstatkeeping house 1.984** 1.191 1.248 0.857 1.462* 1.211
(0.346) (0.273) (0.260) (0.268) (0.230) (0.395)
wrkstatother 0.487 1.199 0.191 0.243* 1.259 0.292
(1.053) (0.525) (1.034) (0.753) (0.399) (1.049)
regionmiddle atlantic 1.011 0.960 1.452 0.592 1.288 2.001
(0.520) (0.356) (0.439) (0.392) (0.382) (0.690)
regione. nor. central 0.776 0.722 1.705 1.105 1.131 1.326
(0.498) (0.340) (0.411) (0.332) (0.358) (0.664)
regionw. nor. central 0.303 0.501 1.260 0.990 1.007 2.491
(0.848) (0.468) (0.497) (0.399) (0.430) (0.710)
regionsouth atlantic 0.873 0.565* 1.325 0.797 1.348 1.776
(0.475) (0.333) (0.410) (0.331) (0.346) (0.638)
regione. sou. central 0.817 0.747 2.146* 0.841 1.307 1.576
(0.596) (0.413) (0.454) (0.404) (0.407) (0.730)
regionw. sou. central 0.653 0.601 1.379 1.040 1.366 1.211
(0.546) (0.371) (0.436) (0.347) (0.365) (0.689)
regionmountain 0.906 0.513* 1.904 0.729 1.295 0.615
(0.534) (0.398) (0.440) (0.393) (0.392) (0.843)
regionpacific 1.038 0.983 1.467 0.577 1.268 1.770
(0.486) (0.330) (0.418) (0.364) (0.363) (0.665)
maritalwidowed 0.932 0.831 1.227 0.668 0.459*** 0.378**
(0.429) (0.309) (0.303) (0.286) (0.261) (0.462)
maritaldivorced 1.086 0.786 1.110 0.696* 0.536*** 0.834
(0.297) (0.222) (0.218) (0.202) (0.191) (0.288)
maritalseparated 1.528 0.805 1.164 0.845 0.737 0.967
(0.536) (0.461) (0.450) (0.424) (0.380) (0.572)
maritalnever married 1.067 0.949 1.541** 0.741 0.758 0.634
(0.280) (0.202) (0.206) (0.205) (0.192) (0.341)
childs 0.919 0.927 1.016 0.979 1.007 0.924
(0.073) (0.054) (0.052) (0.050) (0.045) (0.075)
degreehigh school 0.417*** 0.651* 1.330 1.380 1.218 0.838
(0.314) (0.254) (0.280) (0.265) (0.232) (0.347)
degreejunior college 0.306** 0.800 1.418 1.142 1.314 0.664
(0.515) (0.343) (0.365) (0.354) (0.305) (0.497)
degreebachelor 0.974 1.480 2.596*** 1.742* 1.619* 0.424*
(0.349) (0.280) (0.306) (0.296) (0.264) (0.474)
degreegraduate 1.311 2.647*** 2.247** 1.883* 1.398 1.243
(0.400) (0.309) (0.363) (0.339) (0.315) (0.452)
religcatholic 0.237*** 0.689* 0.986 0.869 0.681** 0.584*
(0.421) (0.218) (0.193) (0.174) (0.168) (0.282)
religjewish 2.071 2.698** 0.536 0.390 1.001 0.444
(0.627) (0.467) (0.785) (0.779) (0.506) (1.069)
relignone 2.356*** 2.374*** 1.346 0.563*** 0.449*** 0.347***
(0.233) (0.180) (0.186) (0.206) (0.206) (0.379)
religother 0.00003*** 2.081 0.811 0.545 0.133* 0.0001***
(0.00001) (0.472) (0.651) (0.650) (1.044) (0.00003)
religbuddhism 6.376** 5.433** 3.350* 0.0004*** 1.461 0.001***
(0.800) (0.693) (0.728) (0.0003) (0.785) (0.0002)
relighinduism 0.00002*** 0.576 0.502 0.00001*** 0.00000*** 0.00001***
(0.00001) (0.901) (1.127) (0.00000) (0.00000) (0.00001)
religother eastern 0.178*** 4,195,801.000*** 0.263*** 0.294*** 0.086*** 0.134***
(0.000) (0.00000) (0.000) (0.000) (0.000) (0.000)
religmoslem/islam 0.00002*** 0.688 0.780 0.00001*** 0.768 0.00004***
(0.00001) (0.833) (0.819) (0.00001) (0.706) (0.00001)
religorthodox-christian 0.001*** 0.0004*** 1.734 2.247 1.184 0.001***
(0.001) (0.0003) (1.250) (1.027) (1.239) (0.001)
religchristian 1.143 0.624 0.264 0.367 1.051 0.591
(0.787) (0.780) (1.049) (0.771) (0.484) (1.057)
relignative american 0.342*** 0.035*** 0.004*** 0.001*** 0.005*** 0.021***
(0.003) (0.0002) (0.0001) (0.00002) (0.0001) (0.0003)
religinter-nondenominational 0.072*** 0.005*** 0.015*** 0.003*** 0.0005*** 0.022***
(0.001) (0.0001) (0.0002) (0.0001) (0.00001) (0.0004)
Constant 0.168** 0.295** 0.111*** 0.315** 0.149*** 0.061***
(0.723) (0.521) (0.592) (0.523) (0.512) (0.885)
---------------------------------------------------------------------------------------------------------------------------------------
Akaike Inf. Crit. 7,607.187 7,607.187 7,607.187 7,607.187 7,607.187 7,607.187
=======================================================================================================================================
Note: *p<0.1; **p<0.05; ***p<0.01
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen modelin üstel beta (exp(B)) özetini word dosyası olarak aşağıdaki linkten indirebilirsiniz.
AIC ve BIC parametrelerinin hesaplanması
AIC değerinde ilk olarak kurulan modelin serbestlik derecesi 2 ile çarpılır. Ardından modelden elde edilen sapmalar (2 X log olasılıkları (LL) hesaplanır. Daha sonra 1. işlemden ikinci işlem çıkarılarak AIC değeri hesaplanır. Formülize edilirse 2 X Serbestlik Derecesi – 2 X Model Sapması eşitliği şeklinde ifade edilebilmekle birlikte literatürdeki notasyonuna uygun yazacak olursak aşağıdaki gibi bir eşitlik kullanmış oluruz.
AIC=2 X k – 2 X LL
Schwarz’ın Bayesçi kriteri (SBC) olarak da bilinen BIC değerinde ilk olarak kurulan modelden elde edilen sapmaların (2*log olasılıkları) hesaplanır. Ardından kurulan modelin uyum değerlerinin veya modele sokulan gözlem sayısının logaritması alınarak kurulan modelin serbestlik derecesiyle çarpılır. Literatürdeki notasyonuna uygun yazacak olursak BIC değeri aşağıda aşağıdaki eşitlik yardımıyla hesaplanmaktadır.
BIC = −2 X LL+k X (n)
Önceki kısımda model özetinde AIC değeri hesaplansa da aşağıdaki R kod bloğunda BIC değeri ile birlikte hesaplanma şekli sonuçlarıyla gösterilecektir.
#AIC değerini hesaplama
#AIC değerinde ilk olarak kurulan modelin serbestlik derecesi 2 ile çarpılır. Ardından modelden elde edilen sapmalar (2*log olasılıkları) hesaplanır. Daha sonra 1. işlemden ikinci işlem çıkarılarak AIC değeri hesaplanır.
#formülize edilirse 2*Serbestlik Drecesi-2*Model Sapması
#modelin serbestlik derecesi:mnmodel$edf=234
2*234-2*logLik(mnmodel)#AIC=7607.187
2*mnmodel$edf-2*logLik(mnmodel)#AIC=7607.187
2*(mnmodel$edf-logLik(mnmodel))#AIC=7607.187
#BIC (Bayesian Information Criterion) değerini hesaplama
#BIC değerinde ilk olarak kurulan modelden elde edilen sapmaların (2*log olasılıkları) hesaplanır. Ardından kurulan modelin uyum değerlerinin gözlem sayısının logaritmasının alınarak kurulan modelin serbestlik derecesiyle çarpılır.
#-modelsapması+model serbestlik derecesi*log(model uyumdeğerlerindeki gözlem sayısı)
-2*logLik(mnmodel)+mnmodel$edf*log(NROW(mnmodel$fitted.values)) ##8942.745
BIC(mnmodel)#8942.745: Doğrulamak için
AIC(mnmodel)#7607.187: Doğrulamak için
Pseudo R Karelerin ve 2 X LL’nin hesaplanması
Pseudo R Kareler ve 2 X LL (Log Likehood) bütünsel olarak model uyumunu değerlendirme imkanı sunmaktadır.
etiket=c("2*Log Likehood (2LL)","Hosmer and Lemeshow","Cox and Snell","Nagelkerke", "Mc Fadden") %>% as_tibble()%>% rename("2*LL ve Pseudo R Kareler"=value)
etiket
d=mnmodel$deviance# yada deviance(mnmodel)
nd=deviance(update(mnmodel, . ~ 1, trace=F))
l=length(mnmodel$fitted.values)
llm=logLik(mnmodel)#model log olasılıkları
lln=logLik(update(mnmodel, . ~ 1, trace=F))#null model log olasılıkları (sadece intersept değerini içerir)
x0=2*logLik(mnmodel)#kurulan modelin sapmasını gösterir. 2LL değeri 0'a ne kadar yakınsa o kadar iyidir. Yüksek 2LL değerleri, kurulan model ile verinin uyumunun iyi olmadığı göstermektedir.
x1=1-d/nd# The Hosmer-Lemeshow testi goodness of fit testidir.
x2=1-exp(-(nd-d)/l)
x3=x2/(1-exp(-(nd/l)))#Nagelkerke R Kare:Kurulan Modelin açıklama gücünü gösterir.
x4=1-llm/lln
degerler<-c(x0,x1,x2,x3,x4)%>% as_tibble()%>% rename("Değerler"=value)
tablo<-cbind(etiket, round(degerler,3))#etiket ve değer vektörlerinden tablo oluşturulması
formattable(tablo)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen Pseudo R kareler aşağıda verilmiştir.

Bağımsız değişkenlerin önem düzeyleri
n<-varImp(mnmodel)
n<-rownames(n)
n<-n %>% as_tibble()
varImp(mnmodel)%>% as_tibble() %>% rename("Onem_Duzeyi"=Overall) %>% add_column("Değişken"=n$value,.before="Onem_Duzeyi") %>% mutate_if(is.numeric, round, 3) %>% arrange(desc(Onem_Duzeyi)) %>% slice(1:10) %>% formattable()
Yukarıdaki R kod bloğunun çalıştırılmasından sonra bağımsız değişkenlerin bağımlı değişken (admit) üzerindeki önem düzeyleri en yüksek olan ilk 10 kayıt aşağıdaki tabloda verilmiştir.

Tahmin edilen olasılıkların (predicted probabilities) hesaplanması
tahminolasilik <- as_tibble(predict(mnmodel, type = "probs")) %>% add_column(id=1:NROW(tamveri), .before="moderate")
o<-tahminolasilik %>% slice(1:10)
formattable(round(o,3))
Hesaplanan tahmin olasılıklarının ilk 10 kaydı aşağıda verilmiştir.

Artıklar (residuals)’ın hesaplanması
artik <- as_tibble(residuals(mnmodel)) %>% #calculate residuals
setNames(paste('resid.', names(.), sep = "")) %>% #değişken adlarını artıklara göre update etme
add_column(id=1:NROW(tamveri), .before="resid.moderate")
a<-artik %>% slice(1:10)
formattable(round(a,3))
Hesaplanan artıkların ilk 10 kaydı aşağıda verilmiştir.

Veri setine tahmin edilen olasılıkların ve artıkların eklenmesi
gv<-cbind(tamveri, tahminolasilik,artik)
gv %>% glimpse()
Yukarıdaki R kod bloğu çalıştırıldıktan sonra aşağıda görüleceği üzere veri setinde değişken sayısı artmış ve sağa doğru veri seti genişlemiştir.
Observations: 2,225
Variables: 26
$ age <int> 43, 42, 63, 71, 67, 59, 43, 62, 59,...
$ sex <fct> male, male, female, male, female, f...
$ wrkstat <fct> "temp not working", "working fullti...
$ region <fct> new england, new england, new engla...
$ marital <fct> never married, married, married, di...
$ childs <int> 0, 2, 2, 0, 2, 6, 0, 4, 2, 3, 2, 2,...
$ degree <fct> junior college, bachelor, bachelor,...
$ relig <fct> christian, none, protestant, cathol...
$ polviews <fct> conservative, slghtly conservative,...
$ polviews2 <fct> conservative, slghtly conservative,...
$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...
$ moderate <dbl> 0.5838392, 0.2880576, 0.2899059, 0....
$ `extremely liberal` <dbl> 1.004563e-01, 1.205577e-01, 5.10348...
$ liberal <dbl> 1.936053e-02, 2.822772e-01, 1.47536...
$ `slightly liberal` <dbl> 0.01568601, 0.10839992, 0.06482509,...
$ `slghtly conservative` <dbl> 9.198692e-02, 1.190447e-01, 2.22417...
$ conservative <dbl> 0.17720300, 0.07557168, 0.19982598,...
$ `extrmly conservative` <dbl> 1.146804e-02, 6.091201e-03, 2.44544...
$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...
$ resid.moderate <dbl> -0.5838392, -0.2880576, 0.7100941, ...
$ `resid.extremely liberal` <dbl> -1.004563e-01, -1.205577e-01, -5.10...
$ resid.liberal <dbl> -1.936053e-02, -2.822772e-01, -1.47...
$ `resid.slightly liberal` <dbl> -0.01568601, -0.10839992, -0.064825...
$ `resid.slghtly conservative` <dbl> -9.198692e-02, 8.809553e-01, -2.224...
$ resid.conservative <dbl> 0.82279700, -0.07557168, -0.1998259...
$ `resid.extrmly conservative` <dbl> -1.146804e-02, -6.091201e-03, -2.44...
Gözlem ve tahmin değerlerinin karşılaştırılması ve doğruluk oranı
gv<-gv[, !duplicated(colnames(gv))]#tekrarlı değişkenlerin veri setinden çıkarılması (örneğin id gibi)
gv <- gv %>% mutate(tahmin = predict(mnmodel, type = "class"))
#modelin doğruluk oranı
paste("Doğruluk oranı: %",round(accuracy(gv$polviews2, gv$tahmin)*100,2))
#elde edilen gözlem değerleri ve tahmin değerlerinin xlsx uzantılı dosyaya yazdırılması
write_xlsx(gv, "karsilastirmafullmodel.xlsx")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra modele ait elde edilen doğruluk (accuracy) oranı % 39,1 olup, aşağıda verilmiştir.
[1] "Doğruluk oranı: % 39.1"
Yukarıdaki R kod bloğunun çalıştırılmasından sonra modele ait elde edilen tahmin değerleri gözlem değerleri ile birlikte karşılaştırmalı olarak aşağıda verilmiş olup, buradaki linkten indirebilirsiniz.
Sınıflandırma tablosunun oluşturulması
Hata Matriksi (Confusion Matrix) değerleri
Karışıklık matrisi olarak olarak da adlandırılan hata matrisi sınıflandırma problemlerinin çözümünde hata metriklerini ortaya koyarak kurulan modelin veya modellerin hata oranını değerlendirmektedir.Hata matrisinin makine ve derin öğrenme metodlarının değerlendirilmesinde sıklıkla kullanıldığı görülmektedir. Aşağıda yer alan tabloda hata metriklerinin hesaplanmasına esas teşkil eden tablo verilmiştir. Bu tabloyla sınıflandırma hataları hesaplanabilmektedir. Tabloda yer verilen Tip 1 hata (Type 1 error) istatistikte alfa hatasını göstermektedir. Tip 1 hata H0 hipotezi (null hpypothesis) doğru olduğu halde reddedilmesidir. Tabloda Tip 2 hata (Type II error) olarak adlandırılan hata ise istatistikte Beta hatası olarak da bilinmektedir. Tip 2 hata ise H0 hipotezi (null hpypothesis) yanlış olduğu halde kabul edilmesidir.
Tablo 1: Karışıklık Matrisi

Kaynak: Stanford Üniversitesi
Tablo 1’de TP: Doğru Pozitifleri, FN: Yanlış Negatifleri, FP: Yanlış Pozitifleri ve TN: Doğru Negatifleri göstermektedir.
- Doğruluk (Accuracy): TP+TN / TP+TN+FP+FN eşitliği ile hesaplanır. Modelin genel performansını ortaya koyar. Bu sınıflandırma metriği ile aslında biz informal bir şekilde dile getirirsek doğru tahminlerin toplam tahminler içindeki oranını hesaplamış oluyoruz.
- Kesinlik (Precision): TP / TP+FP eşitliği ile hesaplanır. Doğru tahminlerin ne kadar kesin olduğunu gösterir.
- Geri çağırma (Recall): TP / TP+FN eşitliği ile hesaplanır. Gerçek pozitif örneklerin oranını verir.
- Özgünlük (Specificity): TN / TN+FP eşitliği ile hesaplanır. Gerçek negatif örneklerin oranını gösterir.
- F1 skoru : 2TP / 2TP+FP+FN eşitliği ile hesaplanır. Dengesiz sınıflar için yararlı hibrit bir metrik olup, kesinlik (precision) ve geri çağırma (recall) skorlarının ağırlıklı ortalamasını ifade etmektedir.
- ROC (Receiver operating characteristic): Yukarıda karışıklık matrisinde belirtilen parametrelerden yararlanılarak hesaplanır. ROC eğrisi olarak da adlandırılmaktadır. ROC eğrileri, herhangi bir tahmin modelinin doğru pozitifler (TP) ve negatifler (TN) arasında nasıl ayrım yapabileceğini görmenin güzel bir yoludur. Sınıflandırma modellerin perfomansını eşik değerler üzerinden hesaplar. ROC iki parametre üzerinden hesaplanır. Doğru Pozitiflerin Oranı (TPR) ve Yanlış Pozitiflerin Oranı (FPR) bu iki parametreyi ifade eder. Burada aslında biz TPR ile Geri Çağırma (Recall), FPR ile ise 1-Özgünlük (Specificity)‘ü belirtiyoruz.
- Cohen Kappa: Kategorik cevap seçenekleri arasındaki tutarlılığı ve uyumu gösterir. Cohen, Kappa sonucunun şu şekilde yorumlanmasını önermiştir: ≤ 0 değeri uyumun olmadığını, 0,01–0,20 çok az uyumu, 0,21-0,40 az uyumu, 0,41-0,60 orta, 0,61-0,80 iyi uyumu ve 0,81–1,00 çok iyi uyumu göstermektedir. 1 değeri ise mükemmel uyum anlamına gelmektedir.
st<-gv %>%
count(polviews, tahmin, .drop = FALSE) %>%
pivot_wider(names_from = tahmin, values_from = n)
formattable(st)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen sınıflandırma tablosu aşağıda verilmiştir. Tabloda satırlar gözlemleri, sütunlar ise tahminleri göstermektedir.
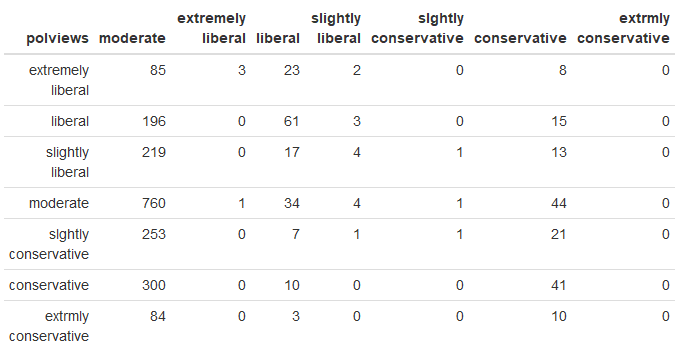
Model etki testi (Parametre Tahminleri)
Anova testi yardımıyla kurulan modelin etkisi test edilmiştir.
Anova(mnmodel, type=c("II","III", 2, 3),
test.statistic=c("LR", "Wald", "F"),
error, error.estimate=c("pearson", "dispersion", "deviance"),)
#yada
Anova(mnmodel)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Anova test sonuçları aşağıda verilmiştir.
Analysis of Deviance Table (Type II tests)
Response: polviews2
LR Chisq Df Pr(>Chisq)
age 19.512 6 0.003381 **
sex 8.150 6 0.227284
wrkstat 54.046 42 0.100714
region 50.427 48 0.377735
marital 35.746 24 0.058085 .
childs 4.606 6 0.595309
degree 84.048 24 1.36e-08 ***
relig 206.960 72 5.51e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Üstel Beta (Exponential Beta: Odds Ratio (OR)) Katsayıları
Lojistik regresyonun yorumlanmasında önemli bir yere sahip üstel Beta katsayı aşağıdaki kod bloğunda hesaplanmıştır. Üstel Beta ya da OR>1 olması pozitif regresyon, OR <1 ise negatif regresyon eğimini göstermektedir. Diğer taraftan, OR = 1 ise regresyon eğimi 0’dır. Bu noktada, OR> 1 olması bağımsız değişken ya da değişkenlerde bir birimlik artışın bağımlı değişken üzerinde artış oluşturduğunu, OR< 1 olması ise bir birimlik artışın bağımlı değişken üzerinde azalış oluşturduğunu göstermektedir. Diğer taraftan OR = 1 olması, bağımsız değişken ya da değişkenlerde bir birimlik artışın bağımlı değişken üzerinde bir değişim oluşturmadığı anlamına gelmektedir.
ga <- confint(mnmodel) # güven aralığı (CI:Confidence Interval)
## OR and CI (Üstel Beta ve Güven Düzeyleri)
exp(cbind(OR = coef(mnmodel), ga))
Yukarıdaki R kod bloğunun ilk satırı çalıştırıldıktan sonra elde edilen üstel Beta (OR) katsayıları güven düzeyleri ile birlikte aşağıda verilmiştir.
(Intercept) age sexfemale wrkstatworking parttime
extremely liberal 0.16846040 1.0059282 0.8751644 1.5822920
liberal 0.29477660 1.0022732 1.1756551 1.4722708
slightly liberal 0.11065417 0.9986118 0.8234712 0.8535055
slghtly conservative 0.31466559 1.0079715 0.8850268 0.8674797
conservative 0.14850901 1.0210274 0.7625484 1.5605552
extrmly conservative 0.06110804 1.0244047 0.8353281 1.1901008
wrkstattemp not working wrkstatunempl, laid off
extremely liberal 2.1211076 2.1037266
liberal 0.2153202 1.7408827
slightly liberal 0.4471815 0.9231653
slghtly conservative 1.1465247 0.9786660
conservative 0.7982186 0.9278552
extrmly conservative 0.4584105 0.7920432
wrkstatretired wrkstatschool wrkstatkeeping house
extremely liberal 1.585180 1.4536904 1.9844193
liberal 1.747823 2.0107656 1.1912533
slightly liberal 1.497587 0.8987300 1.2476328
slghtly conservative 1.072316 1.2289952 0.8567783
conservative 1.192458 0.8795855 1.4618787
extrmly conservative 1.040388 1.3278151 1.2107707
wrkstatother regionmiddle atlantic
extremely liberal 0.4873058 1.0107982
liberal 1.1993091 0.9604608
slightly liberal 0.1913489 1.4520310
slghtly conservative 0.2433988 0.5919863
conservative 1.2594635 1.2881862
extrmly conservative 0.2916028 2.0013732
regione. nor. central regionw. nor. central
extremely liberal 0.7756531 0.3029690
liberal 0.7223793 0.5006705
slightly liberal 1.7049716 1.2602601
slghtly conservative 1.1049231 0.9901576
conservative 1.1313464 1.0070607
extrmly conservative 1.3255102 2.4910194
regionsouth atlantic regione. sou. central
extremely liberal 0.8729301 0.8174478
liberal 0.5650570 0.7465934
slightly liberal 1.3246805 2.1458379
slghtly conservative 0.7965046 0.8414361
conservative 1.3482873 1.3071532
extrmly conservative 1.7755910 1.5761933
regionw. sou. central regionmountain regionpacific
extremely liberal 0.6527834 0.9064877 1.0381067
liberal 0.6007584 0.5125830 0.9827254
slightly liberal 1.3789187 1.9036396 1.4671488
slghtly conservative 1.0395763 0.7286057 0.5767165
conservative 1.3658054 1.2949065 1.2677327
extrmly conservative 1.2110053 0.6146652 1.7695033
maritalwidowed maritaldivorced maritalseparated
extremely liberal 0.9322898 1.0855594 1.5282946
liberal 0.8314182 0.7862645 0.8054861
slightly liberal 1.2267876 1.1096535 1.1636858
slghtly conservative 0.6678892 0.6955511 0.8448778
conservative 0.4587962 0.5360877 0.7368570
extrmly conservative 0.3780865 0.8338402 0.9669279
maritalnever married childs degreehigh school
extremely liberal 1.0668704 0.9193144 0.4169404
liberal 0.9494277 0.9272519 0.6508334
slightly liberal 1.5413107 1.0157388 1.3300697
slghtly conservative 0.7407803 0.9791792 1.3799303
conservative 0.7580167 1.0065994 1.2183890
extrmly conservative 0.6337978 0.9238610 0.8378137
degreejunior college degreebachelor degreegraduate
extremely liberal 0.3062821 0.9735857 1.310575
liberal 0.8004099 1.4802977 2.647408
slightly liberal 1.4182296 2.5960530 2.247263
slghtly conservative 1.1415603 1.7423783 1.882985
conservative 1.3136022 1.6192142 1.398357
extrmly conservative 0.6636683 0.4238604 1.243351
religcatholic religjewish relignone religother
extremely liberal 0.2371049 2.0712872 2.3556047 3.272448e-05
liberal 0.6888056 2.6983813 2.3743352 2.080854e+00
slightly liberal 0.9864984 0.5363862 1.3459928 8.106456e-01
slghtly conservative 0.8691526 0.3901944 0.5632340 5.448040e-01
conservative 0.6811251 1.0010079 0.4493016 1.326924e-01
extrmly conservative 0.5843877 0.4439191 0.3474427 6.557774e-05
religbuddhism relighinduism religother eastern
extremely liberal 6.3759261119 1.726823e-05 1.782457e-01
liberal 5.4331308367 5.755722e-01 4.195801e+06
slightly liberal 3.3498073235 5.017414e-01 2.630241e-01
slghtly conservative 0.0003592186 5.323810e-06 2.938248e-01
conservative 1.4613586298 3.231274e-06 8.612923e-02
extrmly conservative 0.0005983004 9.873711e-06 1.337201e-01
religmoslem/islam religorthodox-christian
extremely liberal 2.492615e-05 0.0011913712
liberal 6.881233e-01 0.0003865216
slightly liberal 7.800872e-01 1.7343969290
slghtly conservative 1.468986e-05 2.2472766422
conservative 7.675558e-01 1.1836500548
extrmly conservative 4.307182e-05 0.0013300860
religchristian relignative american
extremely liberal 1.1429051 0.341831029
liberal 0.6235466 0.035307028
slightly liberal 0.2636772 0.003528762
slghtly conservative 0.3670607 0.001389419
conservative 1.0508766 0.005242058
extrmly conservative 0.5911039 0.020910336
religinter-nondenominational ga
extremely liberal 0.0718498528 0.04081309
liberal 0.0047417046 0.98842146
slightly liberal 0.0150856874 0.57685405
slghtly conservative 0.0032338570 0.82486547
conservative 0.0004792865 0.77946515
extrmly conservative 0.0223818325 0.74465586
Yapılan bu çalışmayla özellikle veri bilimi (data science) ile ilgilenen akademi ve saha çalışanlarına bir katkı sunulması öngörülmektedir.
Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
- https://tevfikbulut.com/2020/07/04/rda-binary-lojistik-regresyon-uzerine-bir-vaka-calismasi-a-case-study-on-binary-logistic-regression-in-r/
- http://gss.norc.org/About-The-GSS
- http://gss.norc.org/Documents/stata/2018_stata.zip
- https://spartanideas.msu.edu/2013/12/01/testing-regression-significance-in-r/
- http://gim.unmc.edu/dxtests/roc3.htm
- https://dss.princeton.edu/training/LogitR101.pdf.
- https://stats.idre.ucla.edu/stata/dae/logistic-regression/
- https://www.mayo.edu/research/documents/data-types/doc-20408956
- https://www2.stat.duke.edu/courses/Fall19/sta210.001/slides/lec-slides/20-multinomial-logistic-pt2.html#11
- https://statistics.laerd.com/statistical-guides/types-of-variable.php
- https://drive.google.com/file/d/1xCLN-jtPMsjl46w4lZzEG6_IWnY-7uqJ/view
- https://sites.google.com/view/statistics-for-the-real-world/contents
- Field, Andy. (2009). Discovering Statistics Using SPSS. Third Edition.
- https://www.r-project.org/
- http://www.sthda.com/english/articles/32-r-graphics-essentials/129-visualizing-multivariate-categorical-data/
- https://stats.idre.ucla.edu
- https://stanford.edu/~shervine/l/tr/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks
- https://stats.idre.ucla.edu/r/whatstat/what-statistical-analysis-should-i-usestatistical-analyses-using-r/#1anova
- https://tevfikbulut.com/2020/05/14/rastgele-orman-algoritmasina-uzerine-bir-vaka-calismasi-a-case-study-on-random-forest-rf-algorithm/
- https://www.sciencedirect.com/topics/medicine-and-dentistry/akaike-information-criterion
- https://astrostatistics.psu.edu/su07/R/library/stats4/html/BIC.html
- https://tevfikbulut.com/2020/05/10/ordinal-lojistik-regres-uzerine-bir-vaka-calismasi-a-case-study-on-ordinal-logistic-regression/