Giriş
Topluluk (ensemble) öğrenme algoritmaları tahmine dayalı analitik çalışmalarda en başarılı yaklaşımlardan biridir. Bu algoritmalar somut bir problemi çözmek için bir araya gelen modeller setinden oluşmaktadır. Amaç modeller setinin ürettiği tahminleri birleştirerek doğruluğu (accuracy) artırmaktır. Topluluk algoritmaları kendi içerisinde üç grupta ele alınır.
- Torbalama (Bagging: Bootsrap Aggregating)
- Yükseltme (Boosting)
- AdaBoost
- Gradient Boosting
- XGBoost
- LightGBM
- İstif (Stacking)
Topluluk (ensemble) öğrenme ve yükseltme algoritmalarından biri olan gradyan yükseltme, ingilizce ifadeyle gradient boosting, temel olarak Leo Breiman tarafından 1997 yılında geliştirilen sınıflandırma, regresyon ve sıralama problemlerinin çözümünde kullanılan makine öğrenmesine dayanan topluluk algoritmasıdır. Gradyan yükseltme algoritmaları yinelemeli olarak çalışır. Bu yöntemde her bir yinelemede yeni bir zayıf öğrenici ilave edilerek güçlü bir öğrenici oluşturulur. Diğer bir ifadeyle, zayıf öğrenicilerin bir araya gelmesiyle güçlü bir öğrenici oluşturulur. Bu yöntemde her ağaç bir öncekinden ardışık düzende öğrenerek sığ ağaçlardan oluşan bir topluluk oluşturulur. Bu topluluk oluşturmak için yeni modellerin eklendiği yinelemeli (iteratif) bir süreçten oluşur. Bu bir anlamda adaptiftir. Algoritmanın her yeni yinelenmesinde, yeni modeller önceki yinelemelerde yapılan hataların üstesinden gelmek için inşa edilir. Bu yöntemde, sonraki her bir modelin önceki modeldeki hataları düzeltmeye çalıştığı sıralı (sequential) bir işlem yapılır. Yani sonraki modeller önceki modele bağımlıdır. Bu yöntem çok çeşitli sorunlara en uygun çözümleri bulabilen çok genel bir optimizasyon algoritmasıdır. Gradyan algortimasının temel fikri, maliyet fonksiyonunu en aza indirmek için parametreleri tekrarlamaktır. Ağaç eklerken kaybı en aza indirmek için gradyan iniş prosedürü kullanılır. Gradyan yükseltme üç unsur içerir:
- Optimize edilecek bir kayıp (loss) fonksiyonu.
- Tahmin yapmak için zayıf bir öğrenici.
- Kayıp fonksiyonu en aza indirmek için zayıf öğrenicilere eklenecek için bir katkı modeli.
Yükseltme algoritmasının işleyiş süreci Şekil 1’de verilmiştir.
Şekil 1: Gradyan Yükseltme (Gradient Boosting) Algoritmasının İşleyiş Süreci

Kaynak: https://www.akira.ai
Yükseltme algoritmaları topluluk üyelerinin her biri birbirine bağımlıdır. Torbalama algoritmaları paralel düzende, yükseltme algoritmaları ise ardışık (sequential) düzende çalışmaktadır.
Modeller oluşturulurken temel amaç, bias ve varyans dengesinin kurulmasıdır. Bu uyumu sağlarsak iyi model uyumu (good-fit) elde etmiş oluruz. Makine öğrenme ve derin öğrenme problemlerinin çözümünde modelleme hatalarına bağlı olarak varyans ve bias değişiklik göstermektedir. Bu iki durum şöyle ele alınabilir:
- Eksik model uyumu (under-fitting): Kurulan modelde elde edilen tahmin değerleri gözlem verisine yeterince uyum göstermediğinde ortaya çıkar. Bu durumda varyans düşükken bias yüksektir. Buradan şunu anlamak gerekir: gözlem verisi ile tahmin edilen veri arasındaki fark büyükse, diğer bir deyişle kurulan modelle bağımlı değişken iyi tahmin edilemiyorsa bu durumda under-fitting oluşur. Under-fitting sonraki kısımlarında anlatılan sınıflandırma ve regresyon hata metrikleri ile kolaylıkla ortaya konulabilir.
- Aşrı model uyumu (over-fitting): Kurulan modelde eğitilen veri seti (training data set)’yle gözlem verisine aşırı uyum gösterdiğinde ortaya çıkar. Bu durumda varyans yüksekken bias düşüktür.
Bahsedilen bu iki durumu kafamızda daha da canlı tutmak için bias ve varyans ilişkisi Şekil 2’de verilmiştir. Şekil’de biz modeli kurgularken olması gereken durumu gösteren Düşük Varyans-Düşük Bias uyumunu, diğer bir ifadeyle yüksek kesinlik (precision)-yüksek doğruluk (accuracy) hedefliyoruz. Diğer bir deyişle kurguladığımız model (Şekil 2 1 nolu model) ile gözlem değerlerini olabildiğince en yüksek doğruluk oranı ile tahmin ederken aynı zamanda varyansı düşük (yüksek kesinlik (precision)) tutmayı hedefliyoruz. Buna başardığımızda aslında iyi model uyumunu (good-fit) sağlamış ve iyi bir model kurmuş oluyoruz. Eksik model uyumu (under-fitting)’nda ise Şekil 2’de 3 nolu modelde görüleceği üzere elde edilen tahmin değerleri gözlem değerleri (kırmızı alan)’nden uzaklaşmakla birlikte hala tahmin değerleri ile gözlem değerleri arasında farklar, diğer bir deyişle varyans düşüktür. Aşırı model uyumu (over-fitting)’da ise Şekil 2’de 2 nolu modelde görüleceği üzere varyans yüksek iken bias düşüktür. 2 nolu modelde doğru değerler (gözlem değerleri)’i kurulan modelde yüksek doğrulukla (düşük bias=yüksek doğruluk (accuracy) tahmin edilse de gözlem değerleri ile tahmin değerleri arasındaki varyans yüksektir.
Şekil 2: Bias-Varyans İlişkisi

Veri Tipleri
Yükseltme algoritmaları ile sınıflandırma problemi çözüyorsak bağımlı değişkenin ya da cevap değişkeninin veri tipi nitel ve kategoriktir. Ancak, bu yöntem ile regresyon problemini çözüyorsak bağımlı değişkenin ya da cevap değişkeninin veri tipi niceldir. Veri tipleri kendi içerisinde 4 farklı alt sınıfta ele alınabilir. Bu veri tipleri alt sınıflarıyla birlikte Şekil 3’te verilmiştir.
Şekil 3: Veri Tipleri
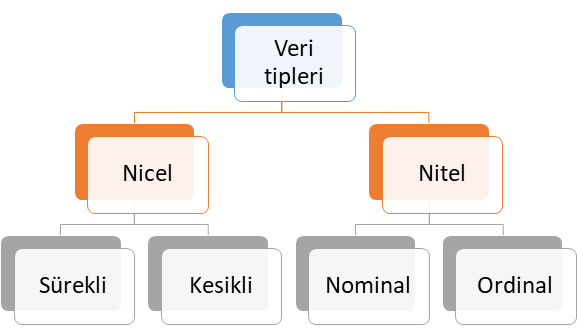
Nicel Veri (Quantitative Data)
Şekil 3’te sunulan nicel veri tipi ölçülebilen veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek verelim.
- Sürekli veri (Continous data): Tam sayı ile ifade edilmeyen veri tipi olup, zaman, sıcaklık, beden kitle endeksi, boy ve ağırlık ölçümleri bu veri tipine örnek verilebilir.
- Kesikli veri (Discrete Data): Tam sayı ile ifade edilebilen veri tipi olup, bu veri tipine proje sayısı, popülasyon sayısı, öğrenci sayısı örnek verilebilir.
Nitel Veri (Qualitative Data)
Şekil 3’te verilen nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar şöyledir:
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisini tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemini de değiştirecektir.
Kullanılan analiz yöntemi ile kurulan modelde ya sınıflandırma problemini ya da regresyon problemini çözdüğümüzü ifade etmiştik. Ancak kurulan modellerde çözülen problemin sınıflandırma ya da regresyon oluşuna göre performans değerlendirmesi farklılaşmaktadır. Sınıflandırma problemlerinde kullanılan hata metrikleri ile regresyon hata metrikleri aynı değildir. Bu bağlamda ilk olarak sınıflandırma problemlerinin çözümünde kullanılan hata metriklerini ele alalım.
Sınıflandırma Problemlerinde Hata Metrikleri
Karışıklık matrisi (confusion matrix) olarak olarak adlandırılan bu matris sınıflandırma problemlerinin çözümünde hata metriklerini ortaya koyarak kurulan modelin veya modellerin hata oranını değerlendirmektedir. Hata matrisinin makine ve derin öğrenme metotlarının değerlendirilmesinde sıklıkla kullanıldığı görülmektedir. Tablo 1’de hata metriklerinin hesaplanmasına esas teşkil eden karışıklık matrisi (confisioun matrix) verilmiştir. Bu tabloyla sınıflandırma hataları hesaplanabilmektedir. Tabloda yer verilen Tip 1 hata (Type 1 error) istatistikte alfa hatasını göstermektedir. Tip 1 hata H0 hipotezi (null hpypothesis) doğru olduğu halde reddedilmesidir. Tabloda Tip 2 hata (Type II error) olarak adlandırılan hata ise istatistikte Beta hatası olarak da bilinmektedir. Tip 2 hata ise H0 hipotezi (null hpypothesis) yanlış olduğu halde kabul edilmesidir.
Tablo 1: Karışıklık Matrisi (Confusion Matrix)

Tablo 1’de TP: Doğru Pozitifleri, FN: Yanlış Negatifleri, FP: Yanlış Pozitifleri ve TN: Doğru Negatifleri göstermektedir.
Şekil 3’te de yer verildiği üzere literatürde sınıflandırma modellerinin performansını değerlendirmede aşağıdaki hata metriklerinden yaygın bir şekilde yararlanıldığı görülmektedir. Sınıflandırma problemlerinin çözümüne yönelik Yükselme (Boosting: AdaBoost) algoritması kullanarak R’da yapmış olduğum çalışmanın linkini ilgilenenler için aşağıda veriyorum.
- Doğruluk (Accuracy): TP+TN / TP+TN+FP+FN eşitliği ile hesaplanır. Modelin genel performansını ortaya koyar. Bu sınıflandırma metriği ile aslında biz informal bir şekilde dile getirirsek doğru tahminlerin toplam tahminler içindeki oranını hesaplamış oluyoruz.
- Kesinlik (Precision): TP / TP+FP eşitliği ile hesaplanır. Doğru tahminlerin ne kadar kesin olduğunu gösterir.
- Geri çağırma (Recall): TP / TP+FN eşitliği ile hesaplanır. Gerçek pozitif örneklerin oranını verir.
- Özgünlük (Specificity): TN / TN+FP eşitliği ile hesaplanır. Gerçek negatif örneklerin oranını gösterir.
- F1 skoru : 2TP / 2TP+FP+FN eşitliği ile hesaplanır. Dengesiz sınıflar için yararlı hibrit bir metrik olup, kesinlik (precision) ve geri çağırma (recall) skorlarının ağırlıklı ortalamasını ifade etmektedir.
- ROC (Receiver operating characteristic): Yukarıda karışıklık matrisinde belirtilen parametrelerden yararlanılarak hesaplanır. ROC eğrisi olarak da adlandırılmaktadır. ROC eğrileri, herhangi bir tahmin modelinin doğru pozitifler (TP) ve negatifler (TN) arasında nasıl ayrım yapabileceğini görmenin güzel bir yoludur. Sınıflandırma modellerin perfomansını eşik değerler üzerinden hesaplar. ROC iki parametre üzerinden hesaplanır. Doğru Pozitiflerin Oranı (TPR) ve Yanlış Pozitiflerin Oranı (FPR) bu iki parametreyi ifade eder. Burada aslında biz TPR ile Geri Çağırma (Recall), FPR ile ise 1-Özgünlük (Specificity)‘ü belirtiyoruz.
- Cohen Kappa: Kategorik cevap seçenekleri arasındaki tutarlılığı ve uyumu gösterir. Cohen, Kappa sonucunun şu şekilde yorumlanmasını önermiştir: ≤ 0 değeri uyumun olmadığını, 0,01–0,20 çok az uyumu, 0,21-0,40 az uyumu, 0,41-0,60 orta, 0,61-0,80 iyi uyumu ve 0,81–1,00 çok iyi uyumu göstermektedir. 1 değeri ise mükemmel uyum anlamına gelmektedir.
Sınıflandırma hata metriklerini anlattıktan sonra daha kalıcı olması ve öğrenilmesi adına hazırladığım excel üzerinde bahsedilen bu metriklerin nasıl hesaplandığı gösterilmiştir. Excel dosyasını aşağıdaki linkten indirebilirsiniz.
Regresyon Problemlerinde Hata Metrikleri
Regresyon modellerinin performansını değerlendirmede literatürde aşağıdaki hata metriklerinden yaygın bir şekilde yararlanılmaktadır. Regresyon metrikleri eşitliklerinin verilmesi yerine sade bir anlatımla neyi ifade ettiği anlatılacaktır. Böylece formüllere boğulmamış olacaksınız.
- SSE (Sum of Square Error): Tahmin edilen değerler ile gözlem değerleri arasındaki farkların kareleri toplamını ifade eder.
- MSE (Mean Square Error): Ortalama kare hatası olarak adlandırılan bu hata tahmin edilen değerler ile gözlem değerleri arasındaki farkların karelerinin ortalamasını ifade eder.
- RMSE (Root Mean Square Error): Kök ortalama kare hatası olarak adlandırılan bu hata ortalama kare hatasının karekökünü ifade etmektedir.
- MAE (Mean Absolute Error): Ortalama mutlak hata olarak adlandırılan bu hata türü ise tahmin edilen değerler ile gözlem değerleri arasındaki farkların mutlak değerlerinin ortalamasını ifade etmektedir.
- MAPE (Mean Absolute Percentage Error): Ortalama mutlak yüzdesel hata olarak adlandırılan bu hata türünde ilk olarak tahmin edilen değerler ile gözlem değerleri arasındaki farkların mutlak değerleri hesaplanır. Daha sonra hesaplanan farkları mutlak değerleri mutlak değerleri alınan gözlem değerlerine bölünür. En son durumda ise elde edilen bu değerlerin ortalaması alınır.
- Bias: Tahmin edilen değerler ile gözlem değerleri arasındaki farkların ortalamasıdır. Bu yönüyle ortalama mutlak hata (MAE)’ya benzemektedir.
Regresyon hata metriklerini anlattıktan sonra daha kalıcı olması ve öğrenilmesi adına hazırladığım excel üzerinde bahsedilen bu metriklerin nasıl hesaplandığı gösterilmiştir. Excel dosyasını aşağıdaki linkten indirebilirsiniz.
Çalışma kapsamında gradyan yükseltme algoritmasıyla sınıflandırma problemi çözülecektir. Bu amaçla Wisconsin Üniversitesi Hastanesinden alınan Meme Kanseri veri seti kullanılarak bağımlı değişken olan meme kanserinin tipi tahmin edilecektir.
Metodoloji ve Uygulama Sonuçları
Bu bölümde gradyan algoritması kullanılarak meme kanserinin türü (iyi huylu: benign, kötü huylu: malign) tahmin edilmiştir. Diğer bir ifadeyle, bu çalışmada sınıflandırma problemi çözmüş olacağız. Analizde kullanılan veri seti Wisconsin Üniversitesi Hastanelerinde 15 Temmuz 1992 tarihine kadar tedavi görmüş hastalardan alınan meme biyopsi verilerini içermektedir. Biyopsi’den bahsetmişken ne anlama geldiğini de açıklayalım. Biyopsi, vücudun farklı bölgelerinden mikroskop yardımıyla inceleme ve farklı tetkikler yaparak hastalık şüphesi bulunan bölgeden tanı amaçlı hücre ya da doku alma işlemidir. Veri setinde 15 Temmuz 1992’ye kadar 699 hastaya ait meme tümör biyopsi gözlemleri bulunmaktadır. Veri setindeki toplam gözlem sayısı 699, değişken sayısı ise 10 (ID numarası hariç)’dur. Bu veri setine R programlama yazılımında “MASS” paketi içerisinde “biopsy” olarak yer verilmiştir. Ancak veri setinde değişkenlerin adları tam olarak yazılmadığı için R programlama dilinde revize edilmiş ve R programlama dili kullanılarak gradyan yükseltme (gradient boosting) algoritmasıyla analiz edilmiştir.
- Cl.thickness: Kitlenin kalınlığını (clump thickness) göstermektedir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Cell.size: Hücre büyüklüğünün homojenliğini (uniformity of cell size) göstermektedir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Cell.shape: Hücre şeklinin bütünlüğünü (uniformity of cell shape) göstermektedir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Marg.adhesion: Marjinal yapışmayı göstermektedir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Epith.c.size Epitel hücre büyüklüğünü (single epithelial cell size) göstermektedir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Bare.nuclei: Sitoplazma (hücrenin geri kalanı) ile çevrili olmayan çekirdekler için kullanılan bir terimdir. Bunlar tipik olarak iyi huylu tümörlerde görülür. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Bl.cromatin: Benign (iyi huylu) hücrelerde görülen çekirdeğin muntazam bir “dokusunu” açıklar (bland chromatin). Kanser hücrelerinde kromatin daha kaba olma eğilimindedir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Normal.nucleoli: Nükleoller, çekirdekte görülen küçük yapılardır. Kanser hücrelerinde nükleoller daha belirgin hale gelir. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Mitoses: Mitotik aktivite, hücrelerin ne kadar hızlı bölündüğünün bir ölçüsüdür. Yüksek mitotik aktivite tipik olarak malign tümörlerde görülür. Cevap değişkenleri 1’den 10’a kadar bir ölçekte puanlanmıştır. Veri tipi nicel ve kesiklidir.
- Class: Meme kanserinin tipini (iyi huylu mu yoksa kötü huylu mu) göstermektedir. Değişken kategorileri “benign” ve “malignant“, diğer bir deyişle iyi ve kötü huyludur.Veri tipi nitel ve nominal kategoriktir.
Bu kapsamda cevap değişkeni (bağımlı değişken) olan “Class” yani meme kanserinin türü geri kalan 9 bağımsız değişken kullanılarak yükseltme (boosting) algoritmasıyla tahmin edilecektir. Analizde kullanılan veri setini aşağıdaki linkten indirebilirsiniz.
Şimdi veri setini tanıdıktan sonra adım adım (step by step) analize başlayabiliriz. Analizde R programlama dili kullanarak analiz adımları R kod bloklarında verilmiştir.
Yüklenecek R kütüphaneleri
rm(list=ls())
kütüphaneler = c("dplyr","tibble","tidyr","ggplot2","formattable","readr","readxl","xlsx", "pastecs","fpc", "DescTools","e1071", "DMwR","caret", "viridis","GGally","ggpurr","psych","writexl","ggfortify","explore","MASS","gbm")
sapply(kütüphaneler, require, character.only = TRUE)
Ver setinin okunması ve değişkenlerin adlandırılması
veri<-biopsy %>% rename(Cl.thickness=V1, Cell.size=V2, Cell.shape=V3, Marg.adhesion=V4, Epith.c.size=V5, Bare.nuclei=V6, Bl.cromatin=V7, Normal.nucleoli=V8, Mitoses=V9, Class=class)
veri<-veri[,-1]
Ver setinin xlsx ve csv uzantılı dosyalara yazdırılması
write.csv(veri, "gögüskanseriveriseti.csv")#csv dosyası için
write_xlsx(veri, "gögüskanseriveriseti.xlsx")#xlsx dosyası için
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri seti xlsx ve csv uzantılı dosyalara yazdırılmıştır. Elde edilen veri seti dosyası sadece xlsx uzantılı olarak aşağıdan indirilebilir. Sitem csv dosya yüklemesini desteklemediği için csv uzantılı dosya aşağıda verilememiştir. Ancak yukarıdaki R kod bloğu çalıştırabilir ve csv uzatılı dosya rmd dosyasının bulunduğu klasör içine otomatik olarak kaydedilebilir.
Veri setinin görselleştirilmesi ve tanımlayıcı istatistikler
#veri setindeki ilk 3 değişkenin görselleştirilmesi
veri[,1:3] %>% explore_all()
#veri setindeki 4,5,6 ve 7. değişkenlerin görselleştirilmesi
veri[,4:7] %>% explore_all()
#veri setindeki 8,9 ve 10. değişkenlerin görselleştirilmesi
veri[,8:10] %>% explore_all()
#veri setindeki ilk 10 gözlem
formattable(head(veri,10))
#Eksik gözlemler çıkarıldıktan sonra Pearson korelasyon matrisi
tamveri<-na.omit(veri)
cor.plot(tamveri[,-10], main="Korelasyon Matrisi")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki ilk 3 değişkenin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki 4,5,6 ve 7. değişkenlerin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere sadece Bare.nuclei değişkende 16 eksik gözlem (missing data: NA) bulunmaktadır.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki 8,9 ve 10. değişkenlerin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra meme kanseri veri setindeki ilk 10 gözlem aşağıdaki tabloda verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra meme kanseri veri setindeki eksik gözlemlerin olduğu 16 satır çıkarılmış, ardından nicel ve kesikli değişkenlere ait Pearson korelasyon matrisi aşağıdaki şekilde verilmiştir. Bağımlı değişken dışındaki değişken çiftleri nicel (sürekli ve kesikli) olduğu için Pearson korelasyon katsayısını hesapladık.

Bağımlı değişken olan tümörün tipi (Class)’ne görer değişkenler arasındaki ilişki
tamveri %>% ggplot(aes(x = Cl.thickness, y = Cell.size, color = Class))+
geom_point(position = position_dodge(0.9)) +
facet_grid( ~Class)
tamveri %>% ggplot(aes(x = Cell.shape, y = Marg.adhesion, color = Class))+
geom_point(position = position_dodge(0.9)) +
facet_grid( ~Class)
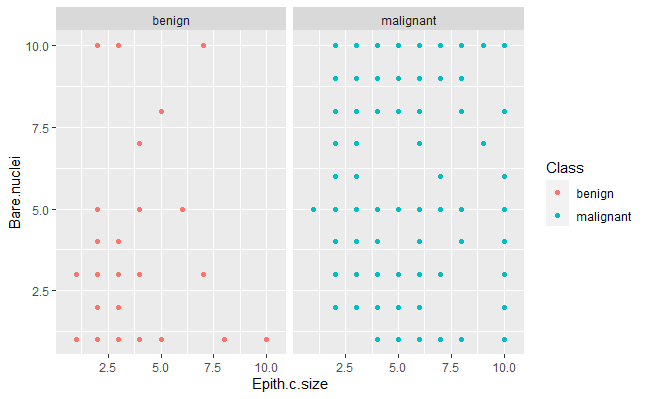
tamveri %>% ggplot(aes(x = Epith.c.size, y = Bare.nuclei, color = Class))+
geom_point(position = position_dodge(0.9)) +
facet_grid( ~Class)
tamveri %>% ggplot(aes(x = Bl.cromatin, y = Normal.nucleoli, color = Class))+
geom_point(position = position_dodge(0.9)) +
facet_wrap(Mitoses~Class )
Yukarıdaki R kod bloğunun çalıştırılmasından sonra ilk iki değişkenin tümörün tipine göre kendi aralarındaki ilişki aşağıdaki grafikte verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra 3. ve 4. değişkenin tümörün tipine göre kendi aralarındaki ilişki aşağıdaki grafikte verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra 5. ve 6. değişkenin tümörün tipine göre kendi aralarındaki ilişki aşağıdaki grafikte verilmiştir.
Yukarıdaki R kod bloğunun çalıştırılmasından sonra 7, 8 ve 9. değişkenlerin tümörün tipine göre kendi aralarındaki ilişki aşağıdaki grafikte verilmiştir.

Veri setinin eğitilecek veri setine ve test veri setine ayrılması
Bu kısımda aşağıdaki R kod bloğunda basit tekrarsız tesadüfi örnekleme (SRS without replacement) yöntemi kullanılarak veri setindeki gözlemlerin % 70’i eğitilecek veri setine, % 30 ise test edilecek veri setine atanmıştır. Veri setinin eğitilecek veri seti ve test veri setine ayrılmasında genel olarak 70:30 kuralı uygulansa da bu kuralın mutlak olmadığı unutulmamalıdır. Veri setindeki gözlem sayısına göre 70:30 kuralı değişiklik gösterebilmektedir. Veri setindeki gözlem sayısı çok azsa 60:40, veri setindeki gözlem sayısı çok fazla ise 80:20 ve hatta 90:10 olabilmektedir. Şimdi soru burada şu olabilir; neden biz 80:20 veya 90:10 olarak belirliyoruz? Genel olarak buna verilebileceğim cevap şu: Eğer çok yüksek gözlem sayıları ile çalışıyorsanız bilgisayar işlemcisine bağlı olarak bu işlemin çok uzun sürmesi kuvvetle muhtemeldir ki bu durumda test veri setinin oranını düşürmek analizinizi hızlandırır ve daha çabuk sonuç alırsınız.
set.seed(1461)
orneklem<- sample(1:NROW(tamveri), NROW(tamveri)*0.7)
train <- tamveri[orneklem, ]
test <- tamveri[-orneklem, ]
Gradyan Yükseltme (Gradient Boosting) modelinin kurulması
model <- gbm(Class ~., data=train, shrinkage=0.01, distribution="multinomial", cv.folds=3, n.trees=5000)
print(model)
Değişkenlerin önem düzeyleri
onem0<-summary(model)
onemduzey0<-tibble("Değişken"=onem0$var,"Önem Düzeyi"=as.numeric(round(onem0$rel.inf,2)))
formattable(onemduzey0,
list(formatter(
"span", style = ~ style(color = "grey",font.weight = "bold")),
`Önem Düzeyi` = color_bar("#00FF00")
))
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen modeldeki değişkenlerin nispi önem düzeyleri (%) değerleriyle birlikte büyükten küçüğe doğru aşağıdaki tabloda verilmiştir.

Tahmin edilen değerler ile test veri setindeki gözlem değerlerinin karşılaştırılması
#en iyi parametre değerine göre tahmin sonuçlarını elde etme
(eniyi <- gbm.perf(model, plot.it=FALSE, method="cv"))
tahmin<-predict(model, test, n.trees=eniyi, type="response")[,,1]
tahmin<-as.factor(colnames(tahmin)[max.col(tahmin)])
karsilastirmatest<-tibble("Gözlem"=test$Class, Tahmin=tahmin)
#ilk ve son 10 tahmin değerini gerçek değerle karşılaştırma
ilk10<-head(karsilastirmatest, 10) %>% rename(Gozlemİlk_10=Gözlem, Tahminİlk_10=Tahmin)
son10<-tail(karsilastirmatest, 10) %>% rename(GozlemSon_10=Gözlem, TahminSon_10=Tahmin)
formattable(cbind("Sıra"=seq(1,10),ilk10, son10))
#sonuçların xlsx dokümanına yazdırılması
karsilatirmasonuctest<-tibble("Gözlem"=test$Class, Tahmin=tahmin)
write_xlsx(karsilatirmasonuctest, "karsilatirmasonuctest.xlsx.")
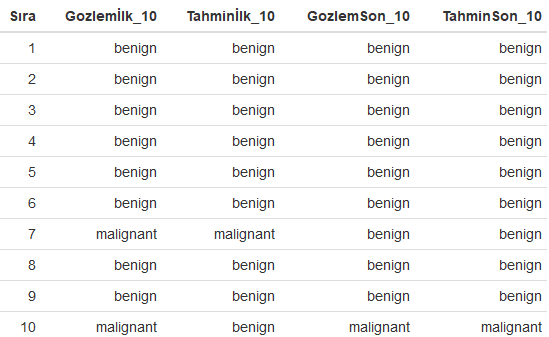
Yukarıdaki R kod bloğunun çalıştırılmasından sonra gradyan yükseltme modelinden elde edilen ilk ve son 10 tahmin sınıflandırma değerleri gözlem sınıflandırma değerleri ile birlikte aşağıdaki tabloda karşılaştırmalı olarak verilmiştir.
Yukarıdaki R kod bloğundaki son kod satırının çalıştırılması ile kurulan modelden elde edilen elde edilen sınıflandırma tahmin sonuçları ile test veri setindeki sınıflandırma sonuçları karşılaştırmalı olarak xlsx dokümanında verilmiş olup, aşağıdaki linkten indirebilirsiniz.
Karışıklık matrisi (confusion matrix)’nin oluşturulması
(eniyi <- gbm.perf(model, plot.it=FALSE, method="cv"))
tahmin<-predict(model, test, n.trees=eniyi, type="response")[,,1]
tahmin<-as.factor(colnames(tahmin)[max.col(tahmin)])
(cm <- table(tahmin, test$Class))
#Doğruluk (Acccuracy) oranı (%)
paste("Doğruluk Oranı: %", round(100*(sum(diag(cm))/sum(cm)),1))
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen karışıklık matrisi aşağıda verilmiştir.
tahmin benign malignant
benign 139 7
malignant 0 59
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen doğruluk oranı % 96,6 olup aşağıda verilmiştir. Burada model test verisi ile karşılaştırılmış olup elde edilen sonuçlar test verisine ilişkin sonuçlardır.
"Doğruluk Oranı: % 96.6"
Sınıflandırma Hata parametreleri
Kurulan modele ait hata parametrelerinin elde edilmesine yönelik yazılan R kod bloğu aşağıda verilmiştir.
cm0<-confusionMatrix(tahmin, test$Class)
cm0
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen hata metrikleri bir bütün olarak aşağıda verilmiştir. Gradyan yükseltme algoritmasıyla kurulan model meme kanseri türlerini yaklaşık % 97 doğruluk (accuracy) oranı ile tahmin etmektedir. Hata oranı ise 100-97 eşitliğinden yola çıkarak % 3 buluruz. Uyumu gösteren Kappa katsayısı ise bu modelde yaklaşık % 92 (0,92) olup, tahmin edilen tümör türleri ile gözlemlenen tümör türleri arasında mükemmele yakın bir uyum olduğu görülmektedir. Bu bulgu aynı zamanda doğruluk oranını da destekler niteliktedir.
Confusion Matrix and Statistics
Reference
Prediction benign malignant
benign 139 7
malignant 0 59
Accuracy : 0.9659
95% CI : (0.9309, 0.9862)
No Information Rate : 0.678
P-Value [Acc > NIR] : < 2e-16
Kappa : 0.9195
Mcnemar's Test P-Value : 0.02334
Sensitivity : 1.0000
Specificity : 0.8939
Pos Pred Value : 0.9521
Neg Pred Value : 1.0000
Prevalence : 0.6780
Detection Rate : 0.6780
Detection Prevalence : 0.7122
Balanced Accuracy : 0.9470
'Positive' Class : benign
Çapraz performans testi (Cross validation test)
Burada modelin performansı çapraz performans testi yapılarak tüm veri seti üzerinde test edilir ve doğruluk oranı verilir. Bu işleme ilişkin yazılan R kod bloğu aşağıda verilmiştir. Bu kısım Bilgisayar işlemcisine bağlı olarak biraz uzun sürebilmektedir. Bu yüzden sabırlı olmakta fayda var 🙂 . Çapraz performans testinde aşağıdaki fonksiyonda görüleceği üzere v=10 yerine v=3 olarak alınmasının nedeni performans testinin kısa sürmesinin sağlanmak istenmesinden kaynaklanmaktadır. Yukarıda karışıklık matrisine göre verilen metrikler test verisine göre elde edilen hata metrikleridir. Yani yukarıda eğitim verisine göre kurulan model test verisi ile karşılaştırılmıştır. Buradaki ayrımı iyi yapmak gerekir.
per<-gbm(Class ~., data=tamveri, shrinkage=0.01, distribution="multinomial", cv.folds=3, n.trees=5000)
bestiter<-gbm.perf(per, method = "cv")
tamveritahmin<-predict(model, tamveri, n.trees=bestiter, type="response")[,,1]
tamveritahmin<-as.factor(colnames(tamveritahmin)[max.col(tamveritahmin)])
tamverikarsilastirma<-tibble("Sıra"=seq(1, NROW(tamveri)), "Gözlem"=tamveri$Class,Tahmin=tamveritahmin)
tamverikarsilastirma
confusionMatrix(tamverikarsilastirma$Gözlem, tamverikarsilastirma$Tahmin)
##tüm veri seti tahminlerini gözlem değerleriyle birlikte xlsx dokümanına yazdırılması
write_xlsx(tamverikarsilastirma, "tumverisetikarsilatirma.xlsx")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra model tüm veri seti üzerinde test edilmiş ve performans parametre değerleri karışıklık matrisi ile birlikte aşağıda verilmiştir. Bulgular, gradyan yükseltme algoritmasının tüm veri seti üzerinde test edildiğinde meme kanseri türlerini % 96,2 doğruluk oranı ve % 3,8 hata oranı ile tahmin ettiğini göstermektedir. Uyumu gösteren Kappa katsayı ise yaklaşık % 92 olup, mükemmele yakın bir uyum elde edildiğini göstermektedir.
Confusion Matrix and Statistics
Reference
Prediction benign malignant
benign 434 10
malignant 16 223
Accuracy : 0.9619
95% CI : (0.9447, 0.975)
No Information Rate : 0.6589
P-Value [Acc > NIR] : <2e-16
Kappa : 0.9158
Mcnemar's Test P-Value : 0.3268
Sensitivity : 0.9644
Specificity : 0.9571
Pos Pred Value : 0.9775
Neg Pred Value : 0.9331
Prevalence : 0.6589
Detection Rate : 0.6354
Detection Prevalence : 0.6501
Balanced Accuracy : 0.9608
'Positive' Class : benign
Yukarıdaki R kod bloğunun son satırı çalıştırılmasından sonra tüm veri seti tahminlerini gözlem değerleriyle birlikte xlsx dokümanına yazdırılmıştır. Gözlem ve tahmin sınıflandırma değerlerine karşılaştırmalı olarak aşağıdaki xlsx dokümanını indirerek ulaşabilirsiniz.
Sonuç
Bu çalışmada sınıflandırma (classification) probleminin çözümüne yönelik topluluk öğrenme algoritmalarından biri olan gradyan yükseltme (gradient boosting) algoritması kullanılarak ayrıntılı deneysel bir çalışma yapılmıştır. Ortaya konulan bulgular, sınıflandırma probleminin gradyan yükseltme (gradient boosting) algoritması tarafından çok başarılı bir şekilde, diğer bir ifadeyle çok yüksek bir doğruluk (accuracy) oranıyla çözüme kavuşturulduğu görülmektedir.
Gradyan yükseltme algoritması test verisi üzerinde test edildiğinde meme kanseri türlerini yaklaşık % 96,6 doğruluk (accuracy) oranı ile tahmin etmektedir. Diğer taraftan tüm veri seti üzerinde test edildiğinde ise meme kanseri türlerini yaklaşık % 96,2 doğruluk (accuracy) oranı ile tahmin etmektedir. Hata oranı (error rate) 1-Doğruluk Oranı eşitliğinden tüm verisi setinde % 3,8’dir . Bu hata sınıflandırma hatası (classification error) olarak da nitelendirilebilir.
Yapılan bu çalışmanın özellikle veri bilimi (data science) ile ilgilenen akademi ve saha çalışanlarına önemli bir katkı sunacağı düşünülmektedir.
Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
- https://web.stanford.edu/~hastie/TALKS/boost.pdf
- https://iq.opengenus.org/types-of-boosting-algorithms/
- https://tevfikbulut.com/2020/05/21/r-programlama-diliyle-regresyon-problemlerinin-cozumunde-rastgele-orman-algoritmasi-uzerine-bir-vaka-calismasi-a-case-study-on-random-forest-rf-algorithm-in-solving-regression-problems-with-r-progr/
- https://www.stat.berkeley.edu/~breiman/Using_random_forests_V3.1.pdf
- https://www.stat.berkeley.edu/~breiman/RandomForests/
- https://stats.idre.ucla.edu/r/library/r-library-introduction-to-bootstrapping/
- https://stanford.edu/~shervine/l/tr/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks
- http://uzalcbs.org/wp-content/uploads/2016/11/2012_082.pdf
- http://www.ub.edu/stat/docencia/EADB/bagging.html
- https://people.cs.pitt.edu/~milos/courses/cs2750-Spring04/lectures/class23.pdf
- https://www.google.com/search?q=underfitting+and+overfitting&source=lnms&tbm=isch&sa=X&ved=2ahUKEwiI1onvyNvpAhVSQMAKHfYyC28Q_AUoAXoECBAQAw&biw=1366&bih=604#imgrc=m5WcPcAqdpCwEM
- Webb G.I. (2011) Overfitting. In: Sammut C., Webb G.I. (eds) Encyclopedia of Machine Learning. Springer, Boston, MA
- https://www.memorial.com.tr/saglik-rehberleri/biyopsi-nedir-ve-nasil-yapilir/
- https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
- Andriyas, S. and McKee, M. (2013). Recursive partitioning techniques for modeling irrigation behavior. Environmental Modelling & Software, 47, 207–217.
- Chan, J. C. W. and Paelinckx, D. (2008). Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sensing of Environment, 112(6), 2999–3011.
- Chrzanowska, M., Alfaro, E., and Witkowska, D. (2009). The individual borrowers recognition:Single and ensemble trees. Expert Systems with Applications, 36(2), 6409–6414.
- De Bock, K. W., Coussement, K., and Van den Poel, D. (2010). Ensemble classification based on generalized additive models. Computational Statistics & Data Analysis, 54(6), 1535–1546.
- De Bock, K. W. and Van den Poel, D. (2011). An empirical evaluation of rotation-based ensemble classifiers for customer churn prediction. Expert Systems with Applications, 38(10), 12293–12301.
- Fan, Y., Murphy, T.B., William, R. and Watson G. (2009). digeR: GUI tool for analyzing 2D DIGE data. R package version 1.2.
- Garcia-Perez-de-Lema, D., Alfaro-Cortes, E., Manzaneque-Lizano, M. and Banegas-Ochovo, R. (2012). Strategy, competitive factors and performance in small and medium enterprise (SMEs).
- African Journal of Business Management, 6(26), 7714–7726.
- Gonzalez-Rufino, E., Carrion, P., Cernadas, E., Fernandez-Delgado, M. and Dominguez-Petit, R.(2013). Exhaustive comparison of colour texture features and classification methods to discriminate cells categories in histological images of fish ovary. Pattern Recognition, 46, 2391–2407.
- Krempl, G. and Hofer, V. (2008). Partitioner trees: combining boosting and arbitrating. In: Okun, O., Valentini, G. (eds.) Proc. 2nd Workshop Supervised and Unsupervised Ensemble Methods and Their Applications, Patras, Greece, 61–66.
- Torgo, Luis, Data Mining With R. Second Edition.
- https://www.akira.ai/glossary/gradient-boosting/
- http://www.ccs.neu.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf
- Breiman, L. (June 1997). “Arcing The Edge” (PDF). Technical Report 486. Statistics Department, University of California, Berkeley.
- https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/