Veri madenciliği alanına giren kelime bulutu üzerine yapılan ilk uygulamada alınan metin (text) verisi üzerinde uygulama yapılmıştı. Şimdi online platformlarda yani web sitelerinde bulunan veri tabanları üzerinde yine özgün örnek bir uygulama yapalım. Örneği yapılacak çalışma, Uluslararası Kızıl Haç Komitesi (The International Committee Of The Red Cross) tarafından hazırlanan 1914-1917 arası yılları anlatan bir rapora dayanmaktadır. Raporun adı Mısırda Türk Mahkumları (Turkish Prisoners in Egypt ) olup, 2004 yılında 76 sayfa olarak yayınlanmıştır.
Uygulama adımları bir önceki örnekte açıklandığı için bu kısımda doğrudan uygulamaya geçilecektir.
İlk olarak raporun edinildiği web adresini de belirtelim. Web adresi, “http://www.gutenberg.org/cache/epub/10589/pg10589.txt” dir. Şimdide kullanılan kod bloklarını yazalım.
Kod Bloğu-1
filePath <- "http://www.gutenberg.org/cache/epub/10589/pg10589.txt"
text <- readLines(filePath)
docs <- Corpus(VectorSource(text))
inspect(docs
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- tm_map(docs, toSpace, "/")
docs <- tm_map(docs, toSpace, "@")
docs <- tm_map(docs, toSpace, "\\|")
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeNumbers)
docs <- tm_map(docs, removeWords, stopwords("english"))
docs <- tm_map(docs, removeWords, c("agr", "will", "one", "two","gutenberg", "english", "offic","hospit", "per"))
docs <- tm_map(docs, removePunctuation)
docs <- tm_map(docs, stripWhitespace)
docs <- tm_map(docs, stemDocument)
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
#En çok tekrarlanan 10 kelime
head(d, 10)
#Kelime bulutu kod bloğu (en az bir en fazla 200 kez tekrarlanan kelimeler alınmıştır)r)
set.seed(1234)
wordcloud(words = d$word, freq = d$freq, min.freq = 1,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
Yukarıdaki kod bloğundan sonra aşağıdaki kelime bulutu elde edilmiş olur.
Bu işlemden sonra sıklık terimlerine dayalı olarak sıklık grafiği oluşturulur. Bu işlemin kod bloğu aşağıda verilmiştir.
Kod Bloğu-2
###Grafik oluşturmak için library(ggplot2) str(d) y<-head(d, 10) y ggplot(y)+geom_point(aes(freq, word),col="red",size=5, shape="+")+ labs(subtitle=NULL, y="Kelimeler", x="Kelime Sayısı",title="En Sık 10 Kelime", caption = "Source:TBulut")+ xlim(42,187)+ theme(plot.title = element_text(family = "Trebuchet MS", color="#666666", face="bold", size=18, hjust=0.5)) + theme(axis.title = element_text(family = "Trebuchet MS", color="#666666", face="bold", size=12))
Kod bloğunun çalıştırılmasından sonra elde edilen kelime sıklık grafiği aşağıdaki gibidir.
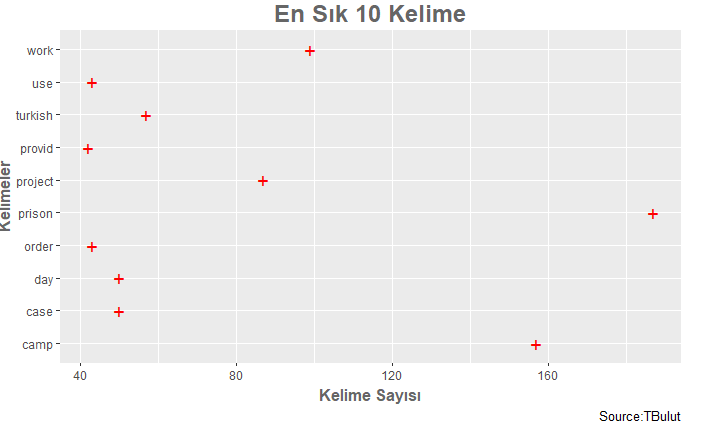
En sık 10 kelimeyi gösteren Grafik elde edildikten sonra veri setindeki grupları belirleyerek kümelemeye olanak tanıyan hiyerarşik küme analizi (Hierarchical Cluster Analysis) yapılmıştır. Elde edilen sonuçlar, bu yöntemde küme dendogramı (cluster dendgram) aracılığıyla sunulur. Gözlemleri ağaçın dallarına benzer bir şekilde sunmaya yarayan dendrogram kelime grupları arasındaki ilişkiyi gösterir. Burada kümeler arasındaki uzaklıkların hesaplanmasında öklidyen uzaklık yöntemi kullanılmıştır. Hiyerarşik küme analizinde kullanılan kod bloğu aşağıda sunulmuştur.
Kod Bloğu-3
k<-head(d,20) m <- as.matrix(k) distMatrix <- dist(m, method="euclidean") library(cluster) fit <- hclust(distMatrix, method="complete") fit plot(fit, hang=-1)
Kod bloğunun çalıştırılmasından sonra elde edilen dendrogram aşağıdaki gibidir.

Yapılan bu çalışmaların, özellikle keşifsel veri analizi (exploratory data analysis) ve nitel araştırma alanına giren içerik analizi (content analysis) noktasında önemli bir katkı sunacağı inancındayım.
Not: Emeğe saygı adına, yapılan çalışmanın başka bir mecrada ya da ortamda paylaşılması halinde alındığı yer adının belirtilmesini rica ederim.
Saygılarımla.