Teknolojiyle çok daha iç içe yaşadığımız günümüzde veri ve bu verinin geçerliliği ve güvenirliği konusu çok daha fazla önem kazanmıştır. Ancak bu verilerin büyük bir çoğunluğunun işlenmesi sorunu ortaya çıkmaktadır.
Nispeten diğer formatlardaki verilere göre pdf formatındaki veriler daha güvenilir ve geçerli sonuçlar ortaya koymaktadır. Çünkü bu formattaki dokümanlar genellikle kurum, kuruluş, araştırmacılar ve bilim insanlarınca ortaya konulmaktadır.
Paylaşılan dokümanlarının formatlarının büyük bir çoğunluğunun pdf formatlı dokümanlar olması bu alanda vaka çalışması niteliğinde örnek bir uygulama yapmamda itici bir etken olmuştur. Bu amaçla, pdf dokümanlarının keşifsel veri analizi (exploratory data analysis) özelinde özgün bir vaka çalışması yapılacaktır. Bu itibarla, Birleşmiş Milletler Çocuklara Yardım Fonu (UNICEF)‘nun sitesindeki “Eğitimde Kaliteyi Tanımlamak” ingilizce karşılığı “Defining Quality in Education” adlı 44 sayfalık pdf formatındaki makalenin 05/08/2018 tarihinde keşifsel veri analizi yapılmıştır. Pdf dokümanının yer aldığı web adresi “https://www.unicef.org/education/files/QualityEducation.PDF” dir.
Anılan makalenin keşifsel analizi yapılırken, ilk olarak kelime bulutu oluşturulacak, ardından hiyerarşik küme analizine geçilecektir.
Kelime bulutu kod bloğu (code block of word cloud)
#Yüklenecek paketler
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
library("rvest")
Data <- readPDF(control=list(text="-layout"))(elem=list(uri="https://www.unicef.org/education/files/QualityEducation.PDF"), language="en")
text_raw <- Data$content
text_raw <- text_raw[-c(1:5)]
text_raw <- text_raw[-c(2:17)]
text_raw <- text_raw[-11]
text_raw <- text_raw[1:211]
text_corpus <- Corpus(VectorSource(text_raw))
corpus_clean <- tm_map(text_corpus, stripWhitespace)
corpus_clean <- tm_map(corpus_clean, removeNumbers)
corpus_clean <- tm_map(corpus_clean, content_transformer(tolower))
print(stopwords("en"))
corpus_clean <- tm_map(corpus_clean, removeWords, stopwords("english"))
ad_stopwords <- c("are","will", "has", "is")
m<-corpus_clean <- tm_map(corpus_clean, removeWords, ad_stopwords)
n<- tm_map(m, removePunctuation)
f <- TermDocumentMatrix(n)
k <- as.matrix(f)
l <- sort(rowSums(k),decreasing=TRUE)
t <- data.frame(word = names(l),freq=l)
set.seed(1234)
wordcloud(words = t$word, freq = t$freq, min.freq = 4,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
Yukarıdaki kod bloğunun run edilmesiyle elde edilen kelime bulutu aşağıdaki gibidir.

Kelime bulutu elde edildikten sonra sıklıkların tamamını excel (xlsx) formatında elde etmek için kullanılan kod bloğu aşağıdaki gibidir.
library(xlsx) write.xlsx(x = t, file = "kelimesikliktablosu.excelfile.xlsx", sheetName = "siklik", row.names = FALSE)
Yukarıdaki kod bloğu run edildikten sonra ortaya çıkan en sık 50 kelime frekanslarıyla birlikte aşağıdaki tabloda sunulmuştur.
Kelime Frekans Tablosu
| Kelimeler | Frekanslar |
| teachers | 97 |
| schools | 74 |
| education | 67 |
| students | 61 |
| school | 56 |
| learning | 52 |
| parents | 51 |
| quality | 50 |
| development | 36 |
| countries | 33 |
| primary | 31 |
| children | 30 |
| achievement | 26 |
| teaching | 26 |
| international | 25 |
| local | 21 |
| paper | 20 |
| new | 19 |
| guinea | 19 |
| educational | 18 |
| student | 18 |
| questionnaires | 18 |
| tests | 18 |
| teacher | 17 |
| training | 17 |
| interviews | 17 |
| community | 16 |
| early | 16 |
| india | 16 |
| programme | 15 |
| skills | 15 |
| classroom | 14 |
| mexico | 14 |
| outcomes | 13 |
| unicef | 13 |
| carron | 13 |
| chau | 13 |
| china | 13 |
| higher | 12 |
| research | 12 |
| curriculum | 12 |
| officials | 12 |
| health | 11 |
| many | 11 |
| scores | 11 |
| studies | 11 |
| test | 11 |
| least | 11 |
| materials | 11 |
| washington | 11 |
| madhya | 11 |
Kelime sıklık tablosundan elde edilen en sık 10 kelime ise aşağıdaki grafikte gösterilmiştir.
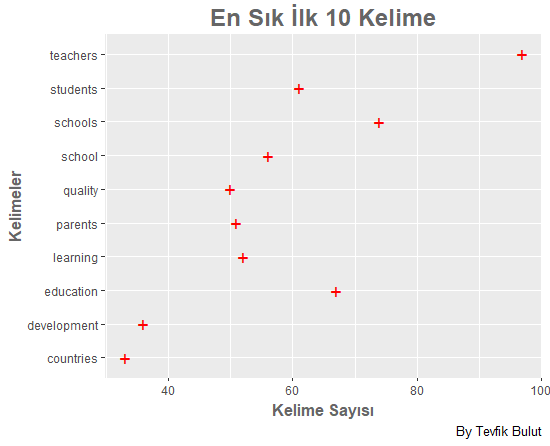
Kelime sıklık tablosu oluşturulduktan sonra tablo sıklıkları gösterilen ilk 20 kelimenin şimdi de hiyerarşik küme analizi analizini yapalım. Elde edilen sonuçlar, bu yöntemde küme dendogramı (cluster dendgram) aracılığıyla sunulur. Gözlemleri ağaçın dallarına benzer bir şekilde sunmaya yarayan dendrogram kelime grupları arasındaki ilişkiyi gösterir. Burada kümeler arasındaki uzaklıkların hesaplanmasında öklidyen uzaklık yöntemi kullanılmıştır. Hiyerarşik küme analizinde kullanılan kod bloğu aşağıda sunulmuştur.
k<-head(t,20) m <- as.matrix(k) distMatrix <- dist(m, method="euclidean") library(cluster) hc <- hclust(distMatrix, method="complete") hc plot(hc, hang=-1)
Kod bloğunun çalıştırılmasından sonra elde edilen dendrogram aşağıdaki gibidir.
Küme Dendrogramı

Yapılan bu çalışmaların, özellikle keşifsel veri analizi (exploratory data analysis) ve nitel araştırma alanına giren içerik analizi (content analysis) noktasında önemli bir katkı sunacağı inancındayım.
Faydalı olması dileğiyle…
Not: Emeğe saygı adına, yapılan çalışmanın başka bir mecrada ya da ortamda paylaşılması halinde alındığı yer adının belirtilmesini rica ederim.
Saygılarımla.