Giriş
Regresyon analizi yöntemlerinden biri olan poisson regresyon analiz yöntemi, bağımlı değişkenin ya da cevap değişkeninin
nicel kesikli ve pozitif (sayma sayıları) olduğu bağımlı değişkenler (dependent variables) ile bağımsız değişken veya değişkenler (independent variables) arasındaki ilişkiyi ortaya koyan regresyon analiz yöntemidir.
Genel olarak bağımlı değişkenin veri tipi yapılacak analiz yöntemlerinde belirleyici rol oynamaktadır. Dolayısıyla veri tiplerinin anlaşılması burada önemlidir. Veri tipleri kendi içerisinde Şekil 1’de görüleceği üzere 4 farklı alt sınıfta ele alınabilir.
Şekil 1: Veri Tipleri
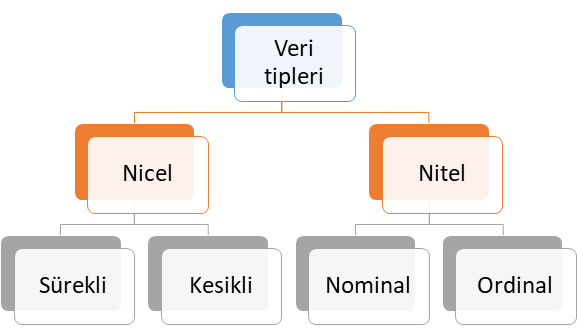
Nitel Veri (Qualitative Data)
Şekil 1’de verilen sunulan nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek vererek ele alalım.
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
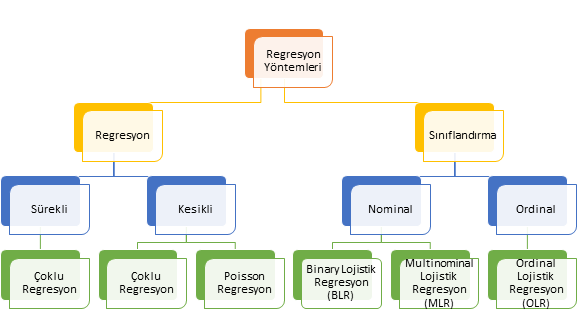
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek regresyon analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Eğer cevap değişkeni nitel ise aslında sınıflandırma problemini çözmek için analizi kullanıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisi tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemi de değiştirecektir. Bağımlı (dependent) değişkenin tipine göre kullanılan regresyon analiz yöntemleri Şekil 2’de genel hatlarıyla verilmiştir.
Şekil 2: Cevap Değişkeninin Veri Tipine Göre Regresyon Analiz Yöntemleri
Modeller oluşturulurken temel amaç, bias ve varyans dengesinin kurulmasıdır. Bu uyumu sağlarsak iyi model uyumu (good-fit) elde etmiş oluruz. Makine öğrenme ve derin öğrenme problemlerinin çözümünde modelleme hatalarına bağlı olarak varyans ve bias değişiklik göstermektedir. Bu iki durum şöyle ele alınabilir:
- Eksik model uyumu (under-fitting): Kurulan modelde elde edilen tahmin değerleri gözlem verisine yeterince uyum göstermediğinde ortaya çıkar. Bu durumda varyans düşükken bias yüksektir. Buradan şunu anlamak gerekir: gözlem verisi ile tahmin edilen veri arasındaki fark büyükse, diğer bir deyişle kurulan modelle bağımlı değişken iyi tahmin edilemiyorsa bu durumda under-fitting oluşur. Under-fitting sonraki kısımlarında anlatılan sınıflandırma ve regresyon hata metrikleri ile kolaylıkla ortaya konulabilir.
- Aşrı model uyumu (over-fitting): Kurulan modelde eğitilen veri seti (training data set)’yle gözlem verisine aşırı uyum gösterdiğinde ortaya çıkar. Bu durumda varyans yüksekken bias düşüktür.
Bahsedilen bu iki durumu kafamızda daha da canlı tutmak için bias ve varyans ilişkisi Şekil 2’de verilmiştir. Şekil’de biz modeli kurgularken olması gereken durumu gösteren Düşük Varyans-Düşük Bias uyumunu, diğer bir ifadeyle yüksek kesinlik (precision)-yüksek doğruluk (accuracy) hedefliyoruz. Diğer bir deyişle kurguladığımız model (Şekil 2 1 nolu model) ile gözlem değerlerini olabildiğince en yüksek doğruluk oranı ile tahmin ederken aynı zamanda varyansı düşük (yüksek kesinlik (precision)) tutmayı hedefliyoruz. Buna başardığımızda aslında iyi model uyumunu (good-fit) sağlamış ve iyi bir model kurmuş oluyoruz. Eksik model uyumu (under-fitting)’nda ise Şekil 2’de 3 nolu modelde görüleceği üzere elde edilen tahmin değerleri gözlem değerleri (kırmızı alan)’nden uzaklaşmakla birlikte hala tahmin değerleri ile gözlem değerleri arasında farklar, diğer bir deyişle varyans düşüktür. Aşırı model uyumu (over-fitting)’da ise Şekil 2’de 2 nolu modelde görüleceği üzere varyans yüksek iken bias düşüktür. 2 nolu modelde doğru değerler (gözlem değerleri)’i kurulan modelde yüksek doğrulukla (düşük bias=yüksek doğruluk (accuracy) tahmin edilse de gözlem değerleri ile tahmin değerleri arasındaki varyans yüksektir.
Şekil 2: Bias-Varyans İlişkisi

Veri Tipleri
Yükseltme algoritmaları ile sınıflandırma problemi çözüyorsak bağımlı değişkenin ya da cevap değişkeninin veri tipi nitel ve kategoriktir. Ancak, bu yöntem ile regresyon problemini çözüyorsak bağımlı değişkenin ya da cevap değişkeninin veri tipi niceldir. Veri tipleri kendi içerisinde 4 farklı alt sınıfta ele alınabilir. Bu veri tipleri alt sınıflarıyla birlikte Şekil 3’te verilmiştir.
Şekil 3: Veri Tipleri
Nicel Veri (Quantitative Data)
Şekil 3’te sunulan nicel veri tipi ölçülebilen veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek verelim.
- Sürekli veri (Continous data): Tam sayı ile ifade edilmeyen veri tipi olup, zaman, sıcaklık, beden kitle endeksi, boy ve ağırlık ölçümleri bu veri tipine örnek verilebilir.
- Kesikli veri (Discrete Data): Tam sayı ile ifade edilebilen veri tipi olup, bu veri tipine proje sayısı, popülasyon sayısı, öğrenci sayısı örnek verilebilir.
Nitel Veri (Qualitative Data)
Şekil 3’te verilen nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar şöyledir:
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisini tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemini de değiştirecektir.
Kullanılan analiz yöntemi ile kurulan modelde ya sınıflandırma problemini ya da regresyon problemini çözdüğümüzü ifade etmiştik. Ancak kurulan modellerde çözülen problemin sınıflandırma ya da regresyon oluşuna göre performans değerlendirmesi farklılaşmaktadır. Sınıflandırma problemlerinde kullanılan hata metrikleri ile regresyon hata metrikleri aynı değildir. Bu bağlamda ilk olarak sınıflandırma problemlerinin çözümünde kullanılan hata metriklerini ele alalım.
Sınıflandırma Problemlerinde Hata Metrikleri
Karışıklık matrisi (confusion matrix) olarak olarak adlandırılan bu matris sınıflandırma problemlerinin çözümünde hata metriklerini ortaya koyarak kurulan modelin veya modellerin hata oranını değerlendirmektedir. Hata matrisinin makine ve derin öğrenme metotlarının değerlendirilmesinde sıklıkla kullanıldığı görülmektedir. Tablo 1’de hata metriklerinin hesaplanmasına esas teşkil eden karışıklık matrisi (confisioun matrix) verilmiştir. Bu tabloyla sınıflandırma hataları hesaplanabilmektedir. Tabloda yer verilen Tip 1 hata (Type 1 error) istatistikte alfa hatasını göstermektedir. Tip 1 hata H0 hipotezi (null hpypothesis) doğru olduğu halde reddedilmesidir. Tabloda Tip 2 hata (Type II error) olarak adlandırılan hata ise istatistikte Beta hatası olarak da bilinmektedir. Tip 2 hata ise H0 hipotezi (null hpypothesis) yanlış olduğu halde kabul edilmesidir.
Tablo 1: Karışıklık Matrisi (Confusion Matrix)

Tablo 1’de TP: Doğru Pozitifleri, FN: Yanlış Negatifleri, FP: Yanlış Pozitifleri ve TN: Doğru Negatifleri göstermektedir.
Şekil 3’te de yer verildiği üzere literatürde sınıflandırma modellerinin performansını değerlendirmede aşağıdaki hata metriklerinden yaygın bir şekilde yararlanıldığı görülmektedir. Sınıflandırma problemlerinin çözümüne yönelik Yükselme (Boosting: AdaBoost) algoritması kullanarak R’da yapmış olduğum çalışmanın linkini ilgilenenler için aşağıda veriyorum.
- Doğruluk (Accuracy): TP+TN / TP+TN+FP+FN eşitliği ile hesaplanır. Modelin genel performansını ortaya koyar. Bu sınıflandırma metriği ile aslında biz informal bir şekilde dile getirirsek doğru tahminlerin toplam tahminler içindeki oranını hesaplamış oluyoruz.
- Kesinlik (Precision): TP / TP+FP eşitliği ile hesaplanır. Doğru tahminlerin ne kadar kesin olduğunu gösterir.
- Geri çağırma (Recall): TP / TP+FN eşitliği ile hesaplanır. Gerçek pozitif örneklerin oranını verir.
- Özgünlük (Specificity): TN / TN+FP eşitliği ile hesaplanır. Gerçek negatif örneklerin oranını gösterir.
- F1 skoru : 2TP / 2TP+FP+FN eşitliği ile hesaplanır. Dengesiz sınıflar için yararlı hibrit bir metrik olup, kesinlik (precision) ve geri çağırma (recall) skorlarının ağırlıklı ortalamasını ifade etmektedir.
- ROC (Receiver operating characteristic): Yukarıda karışıklık matrisinde belirtilen parametrelerden yararlanılarak hesaplanır. ROC eğrisi olarak da adlandırılmaktadır. ROC eğrileri, herhangi bir tahmin modelinin doğru pozitifler (TP) ve negatifler (TN) arasında nasıl ayrım yapabileceğini görmenin güzel bir yoludur. Sınıflandırma modellerin perfomansını eşik değerler üzerinden hesaplar. ROC iki parametre üzerinden hesaplanır. Doğru Pozitiflerin Oranı (TPR) ve Yanlış Pozitiflerin Oranı (FPR) bu iki parametreyi ifade eder. Burada aslında biz TPR ile Geri Çağırma (Recall), FPR ile ise 1-Özgünlük (Specificity)‘ü belirtiyoruz.
- Cohen Kappa: Kategorik cevap seçenekleri arasındaki tutarlılığı ve uyumu gösterir. Cohen, Kappa sonucunun şu şekilde yorumlanmasını önermiştir: ≤ 0 değeri uyumun olmadığını, 0,01–0,20 çok az uyumu, 0,21-0,40 az uyumu, 0,41-0,60 orta, 0,61-0,80 iyi uyumu ve 0,81–1,00 çok iyi uyumu göstermektedir. 1 değeri ise mükemmel uyum anlamına gelmektedir.
Sınıflandırma hata metriklerini anlattıktan sonra daha kalıcı olması ve öğrenilmesi adına hazırladığım excel üzerinde bahsedilen bu metriklerin nasıl hesaplandığı gösterilmiştir. Excel dosyasını aşağıdaki linkten indirebilirsiniz.
Regresyon Problemlerinde Hata Metrikleri
Regresyon modellerinin performansını değerlendirmede literatürde aşağıdaki hata metriklerinden yaygın bir şekilde yararlanılmaktadır. Regresyon metrikleri eşitliklerinin verilmesi yerine sade bir anlatımla neyi ifade ettiği anlatılacaktır. Böylece formüllere boğulmamış olacaksınız.
- SSE (Sum of Square Error): Tahmin edilen değerler ile gözlem değerleri arasındaki farkların kareleri toplamını ifade eder.
- MSE (Mean Square Error): Ortalama kare hatası olarak adlandırılan bu hata tahmin edilen değerler ile gözlem değerleri arasındaki farkların karelerinin ortalamasını ifade eder.
- RMSE (Root Mean Square Error): Kök ortalama kare hatası olarak adlandırılan bu hata ortalama kare hatasının karekökünü ifade etmektedir.
- MAE (Mean Absolute Error): Ortalama mutlak hata olarak adlandırılan bu hata türü ise tahmin edilen değerler ile gözlem değerleri arasındaki farkların mutlak değerlerinin ortalamasını ifade etmektedir.
- MAPE (Mean Absolute Percentage Error): Ortalama mutlak yüzdesel hata olarak adlandırılan bu hata türünde ilk olarak tahmin edilen değerler ile gözlem değerleri arasındaki farkların mutlak değerleri hesaplanır. Daha sonra hesaplanan farkları mutlak değerleri mutlak değerleri alınan gözlem değerlerine bölünür. En son durumda ise elde edilen bu değerlerin ortalaması alınır.
- Bias: Tahmin edilen değerler ile gözlem değerleri arasındaki farkların ortalamasıdır. Bu yönüyle ortalama mutlak hata (MAE)’ya benzemektedir.
Regresyon hata metriklerini anlattıktan sonra daha kalıcı olması ve öğrenilmesi adına hazırladığım excel üzerinde bahsedilen bu metriklerin nasıl hesaplandığı gösterilmiştir. Excel dosyasını aşağıdaki linkten indirebilirsiniz.
Çalışma kapsamında R programlama dili içerisinde bulunan “warpbreaks” veri setinde bağımlı değişken olan breaks (mola sayısı) tahmin edilmiştir. Veri seti kullanılarak poisson ve negatif binom regresyon yöntemleriyle regresyon problemi çözülecektir.
Metodoloji ve Uygulama Sonuçları
Poisson Regresyon Yöntemi
Poisson regresyon, lojistik regresyonlar modellerinin genelleştirilmiş şeklidir. Fakat lojistik regresyonda bağımlı değişkenler kategorilerden oluşan belirli cevap seçenekleri ile sınırlıdır.
Regresyon modellerinden poisson ve negatif binom regresyon modelleri regresyon modellerinin özel bir türü olup, bağımlı değişkenin nicel pozitif ve aynı zamanda kesikli olduğu durumlarda kullanılır. Yapılan Covid-19 testlerinin sayısı, vaka sayısı, ölüm sayısı gibi değişken istatistikleri bu modellerde kullanılabilecek değişkenlere örnek verilebilir. Bu modellerde amaç nicel kesikli ve pozitif bağımlı değişkenin bağımsız değişkenlerle tahmin edilmesidir.
Poisson regresyon analizi, bağımlı değişkenin Poisson dağılımı gösterdiğinden hareket etmektedir. Poisson dağılımı Fransız matematikçi Siméon Denis Poisson tarafından geliştirilmiştir. Poisson dağılımı, bir olayın belirli bir zaman veya mekan aralığında kaç kez meydana geldiğini modellemek için kullanılmaktadır.
Poisson dağılımı sağa çarpık (right skew) bir görünüm sergilemekte olup, olasılık dağılım fonksiyonu aşağıdaki eşitlikte verilmiştir. Bu dağılım sürekli dağılımlardan biri olan normal dağılımın aksine kesikli dağılım türlerinden biridir.

Eşitlikte e= Euler’in sabitini ifade etmektedir. Bu katsayı yaklaşık 2,71828’e eşittir. Eşitlikte yer verilen lambda (λ) belirli zaman aralığında meydana gelen vakaların ortalama sayısını göstermektedir. x ise eşitlikte hedeflenen vaka sayısını belirtmektedir. x = 0, 1, 2, …, n > 0 ve 0 < p ≤ 1. Varsayımsal bir örnek vererek konuyu biraz somutlaştıralım.
Örnek: Bir organize sanayi bölgesinde gıda sektöründe üretim yapan firmanın deposunda stoklanan ürünlerin 0,04’nin bozuk olduğu bilinmektedir. Bu depodan tesadüfi seçilen 80 birimden en az 5 tanesinin bozuk olma olasılığını Poisson dağılımından yararlanarak hesaplayalım.
Burada,
- p= 0,04
- Lambda (λ) = 80*0,04=3,2
Yukarıda belirtilen Poisson kütle olasılık eşitliğinde verilenleri yerine koyarsak

Yapılan işlemi aşağıdaki R kod bloğunda da verelim adım adım hesaplama adımlarını görebilmek açısından.
e<-2.71828 #Euler'in sabiti
sıfır<-(e^-3.2*(3.2)^0)/factorial(0)
bir<-(e^-3.2*(3.2)^1)/factorial(1)
iki<-(e^-3.2*(3.2)^2)/factorial(2)
uc<-(e^-3.2*(3.2)^3)/factorial(3)
dort<-(e^-3.2*(3.2)^4)/factorial(4)
poissonfonksiyon<-sum(sıfır, bir,iki,uc,dort)#f(x): Poisson olasılık dağılım fonksiyonu
round(1-poissonfonksiyon,5)
#Sonuç=0.21939
Lambda (λ) Poisson dağılımı , R’da dpois, ppois ve qpois fonksiyonları ile temsil edilir. dpois yoğunluğu, ppois dağılım fonksiyonunu, qpois çeyreklik fonksiyonu, rpois ise tesadüfi ve tekrarsız atanan sayıları gösterir. İlk olarak rpois fonksiyonunu kullanarak poisson dağılımına uygun lambda değeri 1, popülasyon büyüklüğü (N) 10000 olan gözlem üretelim. Daha sonra poisson regresyon ve dağılımı varsayımlarından biri olan gözlemlerin varyansının gözlemlerin ortalamasına eşit veya yakın olması varsayımını aşağıda yazılan R kod bloğu ile test edip histogramını çizelim.
poisorneklem<-rpois(n=10000, lambda=1)#poisson dağılımına uygun örneklem çekmek
hist(poisorneklem, xlab="", main="Poisson Dağılımı", col="red")
mean(poisorneklem);var(poisorneklem)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen Poisson dağılımına ilişkin histogram aşağıdaki grafikte verilmiştir.
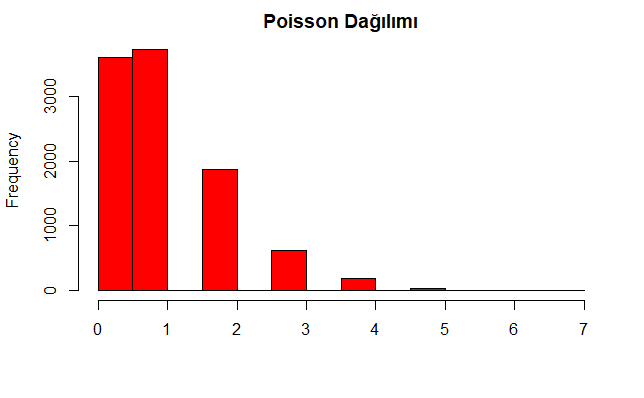
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen Poisson dağılımına ilişkin ortalama 1.0175, varyans ise 1.012895 olup, görüleceği üzere birbirine çok yakındır.
Şimdi de poisson dağılımına uygun olarak aynı popülasyon büyüklüğüne sahip ancak farklı lambda değerleriyle karşılaştırmalı olarak poisson dağılıma grafik üzerinde bakalım. Aşağıda yazılan R kod bloğu ile popülasyon büyüklüğü (N) 1000, lambda düzeyleri ise sırasıyla 1, 1,5, 2, 2,5, 3 ve 3,5 olan poisson eğrileri verilmiştir.
set.seed(61)#Sonuçları sabitlemek için
orneklem<-1000#(N=n)
nd1<-density(rpois(orneklem, lambda=1))
nd2<-density(rpois(orneklem, lambda=1.5))
nd3<-density(rpois(orneklem, lambda=2))
nd4<-density(rpois(orneklem, lambda=2.5))
nd5<-density(rpois(orneklem, lambda=3))
nd6<-density(rpois(orneklem, lambda=3.5))
par(oma = c(0.1, 0.1, 0.1, 0.1))#legendin tablodaki yerini düzenlemek için.
plot(nd1,
xlim = c(0,8),
ylim = c(0,0.8),
cex=0.8,
lwd = 2,
main = "Poisson Dağılımı")
lines(nd2, col = "orange", lwd = 2)
lines(nd3, col = "grey", lwd = 2)
lines(nd4, col = "brown", lwd = 2)
lines(nd5, col = "green", lwd = 2)
lines(nd6, col = "red", lwd = 2)
legend("topright",
legend = c("λ= 1",
"λ= 1.5",
"λ= 2",
"λ= 2.5",
"λ= 3",
"λ= 3.5"),
col = c("black", "orange", "grey", "brown","green","red" ),
lty = 1)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen farklı lambda değerlerine sahip poisson dağılım eğrileri aşağıdaki grafikte verilmiştir. Genel olarak grafikten düşük lambda değerlerine sahip eğrilerin poisson dağılımının da bir özelliği olarak sağa çarpık (right skew) bir görünüm çizdiği görülmektedir. Ancak lambda değerleri artıkça eğriler normal dağılım eğrisine evrilmektedir.

Poisson eğrilerine daha yakından bakacak olursak eğrilerin izlediği seyri daha da iyi anlayabiliriz. Yazılan R kod bloğu ile Poisson eğrilerine ilişkin grafikler ayrı ayrı verilmiştir.
set.seed(6)
orneklem<-1000
l1<-ggdensity(rpois(orneklem, lambda=1),main="λ=1")
l2<-ggdensity(rpois(orneklem, lambda=1.5),main="λ=1.5", col="orange")
l3<-ggdensity(rpois(orneklem, lambda=2),main="λ=2", col="grey")
l4<-ggdensity(rpois(orneklem, lambda=2.5),main="λ=2.5", col="brown")
l5<-ggdensity(rpois(orneklem, lambda=3),main="λ=3", col="green")
l6<-ggdensity(rpois(orneklem, lambda=3.5),main="λ=3.5", col="red")
ggarrange(l1,l2,l3,l4,l5,l6)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen grafikler aşağıda verilmiştir.

Adı geçmişken normal dağılımdan biraz bahsedebilir. Normal dağılım sürekli olasılık dağılımlardan biri olup, eğrisi can eğrisine benzemektedir. Birazdan R’da rnorm fonksiyonu kullanılarak ilk olarak ortalaması 0, standart sapması 1 olan standart normal dağılım eğrisi çizilecektir. Daha sonra rnorm içerisinde yer alan parametreler değiştirilerek normal dağılım eğrilerindeki farklılaşmalar gösterilecektir. Aşağıdaki yazılan R kod bloğu ile ortalaması 0, standart sapması 1 olan normal dağılım eğrisi çizilmiştir.
set.seed(2)
ggdensity(rnorm(orneklem, mean=0, sd=1), main="Standart Normal Dağılım (Ortalama=0 ve Standart Sapma=1)", col="red")+
theme_pander()
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen standart normal dağılım eğrisi aşağıdaki grafikte verilmiştir. Büyük sayı yasası (Law of large numbers)’na göre popülasyondan çekilen örneklem büyüklüğü artıkça örneklem ortalamaları popülasyon ortalamasına yaklaşır. Sözgelimi yaşları bilinen yaklaşık 83 milyonluk ülke nüfusundan çekilen 10 milyonluk örneklemin ortalama değeri, çekilen 2 milyonluk örneklemin ortalama değerinden popülasyon ortalamasına daha yakındır ve bu aslında bir anlamda 10 milyonluk örneklem 2 milyonluk örnekleme göre popülasyonu daha iyi temsil ediyor demektir.

Şimdi de aşağıda yazılan R kod bloğu ile farklı ortalama (Ort) ve standart sapma (SS) değerlerine sahip normal dağılıma uygun eğriler çizerek normal dağılım dağılım eğrilerindeki farklılaşmaları görelim.
set.seed(61)
orneklem<-1000
nd1<-density(rnorm(orneklem, mean=0, sd=1))
nd2<-density(rnorm(orneklem, mean=1, sd=1))
nd3<-density(rnorm(orneklem, mean=2, sd=3))
nd4<-density(rnorm(orneklem, mean=3, sd=4))
nd5<-density(rnorm(orneklem, mean=4, sd=5))
nd6<-density(rnorm(orneklem, mean=5, sd=6))
plot(nd1,
xlim = c(- 10, 10),
main = "Normal Dağılım", lwd = 2)
lines(nd2, col = "orange", lwd = 2)
lines(nd3, col = "grey", lwd = 2)
lines(nd4, col = "brown", lwd = 2)
lines(nd5, col = "green", lwd = 2)
lines(nd6, col = "red", lwd = 2)
legend("topleft",
legend = c("Ort = 0; SS = 1",
"Ort = 1; SS = 1",
"Ort = 2; SS = 3",
"Ort = 3; SS = 4",
"Ort = 4; SS = 5",
"Ort = 5; SS = 6"),
col = c("black", "orange", "grey", "brown","green","red" ),
lty = 2)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra farklı ortalama ve standart sapma değerlerine sahip normal dağılım eğrileri aşağıdaki grafikte verilmiştir. Şekilde siyah eğri standart normal dağılım eğrisini göstermektedir. Burada özellikle standart sapma artıkça eğrilerin normal dağılımdan uzaklaştığını görmekteyiz. Bu duruma şöyle bir yorum da getirilebilir, standart sapmanın artması varyansı ve dolayısıyla hatayı da artıracağından eğri sağa ve sola yayılım gösterir. Eğrinin altındaki alanın toplamı her durumda 1’e eşittir.
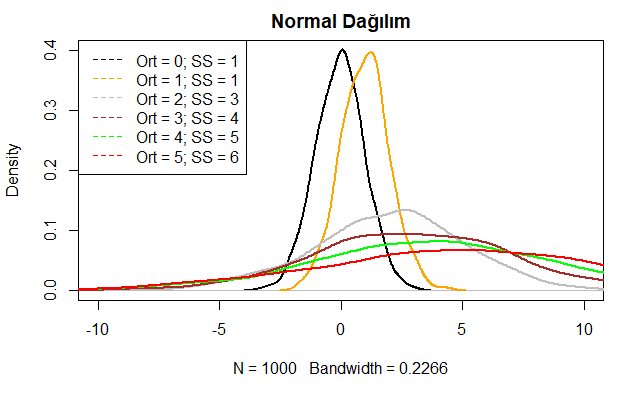
Normal dağılım eğrilerine daha yakından bakacak olursak eğrilerin izlediği seyri daha da iyi anlayabiliriz. Yazılan R kod bloğu ile normal dağılım eğrilerine ilişkin grafikler ayrı ayrı verilmiştir.
set.seed(16)
orneklem<-1000
l1<-ggdensity(rnorm(orneklem, mean=0, sd=1),main="Ort=0, SS=1")
l2<-ggdensity(rnorm(orneklem, mean=1, sd=1),main="Ort=1, SS=1", col="orange")
l3<-ggdensity(rnorm(orneklem, mean=2, sd=3),main="Ort=2, SS=3", col="grey")
l4<-ggdensity(rnorm(orneklem, mean=3, sd=4),main="Ort=3, SS=4", col="brown")
l5<-ggdensity(rnorm(orneklem, mean=4, sd=5),main="Ort=4, SS=5", col="green")
l6<-ggdensity(rnorm(orneklem, mean=5, sd=6),main="Ort=5, SS=6", col="red")
ggarrange(l1,l2,l3,l4,l5,l6)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen normal dağılım grafikleri aşağıda verilmiştir. İlk grafik standart normal dağılım grafiğidir.

Şimdi çizilen bu normal dağılım grafiklerin aşağıda yazılan R kod bloğu ile gerçekten normal dağılıma uyum uymadığını q-q grafikleri ve shapiro wilk testleri ile konrol edelim.
#q-q grafikler
set.seed(16)
q1<-ggqqplot(rnorm(orneklem, mean=0, sd=1), main="Ort=0, SS=1")
q2<-ggqqplot(rnorm(orneklem, mean=1, sd=1), main="Ort=1, SS=1", col="orange")
q3<-ggqqplot(rnorm(orneklem, mean=2, sd=3), main="Ort=2, SS=3", col="grey")
q4<-ggqqplot(rnorm(orneklem, mean=3, sd=4), main="Ort=3, SS=4", col="brown")
q5<-ggqqplot(rnorm(orneklem, mean=4, sd=5), main="Ort=4, SS=5", col="green")
q6<-ggqqplot(rnorm(orneklem, mean=5, sd=6), main="Ort=5, SS=6", col="red")
ggarrange(q1,q2,q3,q4,q5,q6)
#Shapiro Wilk Normalite testleri
s1<-rnorm(orneklem, mean=0, sd=1)
s2<-rnorm(orneklem, mean=1, sd=1)
s3<-rnorm(orneklem, mean=2, sd=3)
s4<-rnorm(orneklem, mean=3, sd=4)
s5<-rnorm(orneklem, mean=4, sd=5)
s6<-rnorm(orneklem, mean=5, sd=6)
st<-tibble(s1,s2,s3,s4,s5,s6)
istatistik<-apply(st, 2, function(x) shapiro.test(x)$statistic)
pdegeri<-apply(st, 2, function(x) shapiro.test(x)$p.value)
round(rbind(istatistik,pdegeri),3)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen q-q grafikleri aşağıda verilmiştir. q-q grafiklere bakıldığında örneklem dağılımının teorik normal dağılımın eğrisi boyunca ilerlediği ve bu eğriden sapma göstermediği görülmektedir.
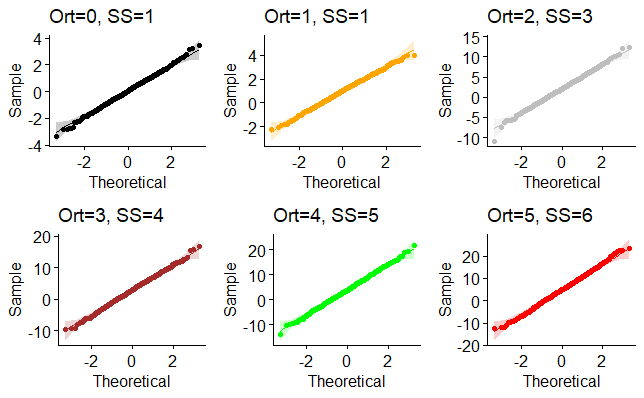
Yukarıdaki R kod bloğunda Shapiro Wilk testlerine ilişkin R kod bloğu çalıştırılmasıyla elde edilen sonuçlar aşağıda verilmiştir. Elde sonuçlara göre bütün dağılım veri setlerinde p >0,05 olduğu için verinin istatistiksel olarak normal dağılım gösterdiğini rahatlıkla söyleyebiliriz. Yukarıdaki q-q grafikleri de bunu doğrular niteliktedir.
s1 s2 s3 s4 s5 s6
istatistik 0.998 0.998 0.998 0.999 0.999 0.999
pdegeri 0.246 0.418 0.162 0.878 0.900 0.799
Negatif binom regresyon yöntemi
Negatif bir binom dağılımı, Poisson dağılımlarının özel bir türüdür. Poisson olasılık dağılımı gibi kesikli bir olasılık dağılımıdır. Negatif binom dağılımı kitle fonksiyonu aşağıdaki denklemle ifade edilebilir. İkili sonuçları olan Bernoulli deneylerinde geçerli olan varsayımlar negatif binom dağılımı için de geçerlidir. Bağımsız Bernoulli deneylerinde ilk başarı önemliyken, negatif binom dağılımında r tane başarı elde durumu söz konusudur. Negatif binom dağılımı geometrik dağılımının genelleştirilmiş bir şeklidir.

x = 0, 1, 2, …, n > 0 ve 0 < p ≤ 1. Eşitlikte p başarı olasılığını göstermektedir. Varsayımsal bir örnek vererek konuyu biraz somutlaştıralım.
Örnek: Covid-19 hastalığına maruz kalan sigara kullanan 65 yaşındaki bireyin bu hastalığa yakalanma olasılığı 0,70 ise bu hastalığa maruz kalan aynı yaşta 20. bireyin bu hastalığa yakalanan 8. birey olma olasılığı nedir?
Burada,
- p=0,70 (hastalığa maruz kalma olasılığı)
- x=20 (hastalığa maruz kalan 20. birey)
- r=8 (hastalığa yakalanan 8. birey)
Yukarıda belirtilen negatif binom eşitliğinde verilenleri yerine koyarsak

Yapılan işlemi aşağıdaki R kod bloğunda da verelim kullanılan fonksiyonun görülebilmesi açısından.
options(scipen=999)#Sonuçların bilimsel gösterimden eşitliği kurtarmak için
round(choose(19,7)*(1-0.7)^(20-8)*(0.7)^8,5)#burada choose () fonksiyonu kombinasyon hesaplamasında kullanılmıştır.
#Sonuç:0.00154
R’da rnbinom fonksiyonu ile belirtilen negatif binom dağılıma göre rastgele seçilen 1 veya daha fazla sayı üretilmektedir. rnbinom(n, size, prob, mu) fonksiyonu negatif binom dağılımına göre tekrarsız seçilen örneklem büyüklüğünü göstermektedir. Fonksiyondaki size parametresi, diğer bir ifadeyle shape parametresi hedeflenen başarılı denemelerin sayısını, mu ise ortalamasını göstermektedir. İlk olarak rnbinom fonksiyonunu kullanarak negatif binom dağılımına uygun gözlem sayısı 10000, hedeflenen başarılı denemelerin sayısı 20, ortalamanın ise 5 olduğu varsayımından hareketle aşağıda yazılan R kod bloğu ile histogramı çizilmiştir.
nbd<-tibble(Sayi=rnbinom(n=10000, size=20, mu=5))
ggplot(nbd, aes(x=Sayi)) +
geom_histogram(aes(y=..density..),bins=100,binwidth=.3, fill="red")+
geom_density(alpha=.3, fill="blue")+
xlab("")+
ylab("Yoğunluk")+
ggtitle("Negatif Binom Dağılımı Yoğunluk ve Histogram")
#Alternatif olarak sadece yoğunluk grafiği verecek olursak
ggdensity(rnbinom(n=10000, size=20, mu=5), xlab="",ylab="Yoğunluk", main="Negatif Binom Dağılımı Yoğunluk Grafiği", col="red")+
theme_economist()
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen Negatif binom dağılımına ilişkin histogram ve yoğunluk aşağıdaki grafik üzerinde verilmiştir.
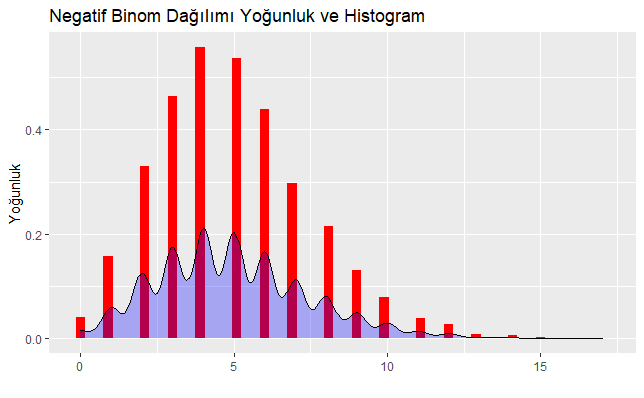
Alternatif olarak daha net görebilmek adına sadece yoğunluk grafiği verecek olursak R kod bloğundaki ilgili alan çalıştırıldığında aşağıdaki grafik elde edilmiş olacaktır. Burada amaç biraz da grafiği farklı bir temayla sunmak :).
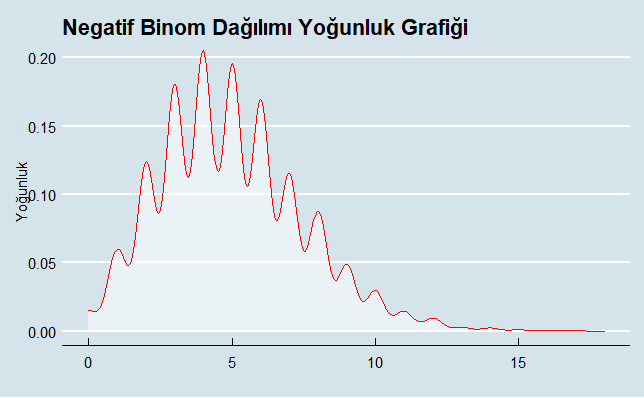
Şimdi de Negatif Binom dağılımına uygun olarak aynı popülasyon büyüklüğü (N) sahip ancak farklı size ve ortalama (mu) değerleriyle karşılaştırmalı olarak negatif binom dağılıma grafik üzerinde bakalım. Aşağıda yazılan R kod bloğu ile popülasyon büyüklüğü (N) 1000 olan
- mu = 4, size = 10
- mu = 8, size = 20
- mu = 12, size = 30
- mu = 16, size = 40
- mu = 20, size = 50
- mu = 24, size = 60
değerlerine sahip negatif binom eğrileri çizilmiştir.
set.seed(61)
orneklem<-1000
nb1<-density(rnbinom(orneklem, mu = 4, size = 10))
nb2<-density(rnbinom(orneklem, mu = 8, size = 20))
nb3<-density(rnbinom(orneklem, mu = 12, size = 30))
nb4<-density(rnbinom(orneklem, mu = 16, size = 40))
nb5<-density(rnbinom(orneklem, mu = 20, size = 50))
nb6<-density(rnbinom(orneklem, mu = 24, size = 60))
par(oma = c(1, 0.1, 0.1, 0.1))
plot(nb1,
xlim = c(0,20),
ylim = c(0,0.25),
main = "Negatif Binom Dağılımı")
lines(nb2, col = "orange", lwd = 2)
lines(nb3, col = "grey", lwd = 2)
lines(nb4, col = "brown", lwd = 2)
lines(nb5, col = "green", lwd = 2)
lines(nb6, col = "red", lwd = 2)
legend("topright",
legend = c("Size= 10",
"Size= 20",
"Size= 30",
"Size= 40",
"Size= 50",
"Size= 60"),
col = c("black", "orange", "grey", "brown","green","red"),
lty = 1)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra farklı mu ve size sapma değerlerine sahip negatif binom olasılık dağılım eğrileri aşağıdaki grafikte verilmiştir.

Negatif binom olasılık dağılım eğrilerine daha yakın plandan bakacak olursak eğrilerin izlediği seyri daha da iyi anlayabiliriz. Yazılan R kod bloğu ile Negatif Binom dağılım eğrilerine ilişkin grafikler ayrı ayrı verilmiştir.
set.seed(26)
orneklem<-1000
nby1<-ggdensity(rnbinom(orneklem, mu = 4, size = 10),main="m = 4, s = 10", col="orange")
nby2<-ggdensity(rnbinom(orneklem, mu = 8, size = 20),main="m = 8, s = 20",col="orange")
nby3<-ggdensity(rnbinom(orneklem, mu = 12, size = 30),main="m = 12, s = 30", col="grey")
nby4<-ggdensity(rnbinom(orneklem, mu = 16, size = 40),main="m = 16, s = 40", col="brown")
nby5<-ggdensity(rnbinom(orneklem, mu = 20, size = 50),main="m = 20, s = 50",col="green")
nby6<-ggdensity(rnbinom(orneklem, mu = 24, size = 60),main="m = 24, s = 60", col="red")
ggarrange(nby1,nby2,nby3,nby4,nby5,nby6)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen grafikler aşağıda verilmiştir. Elde edilen bulgular mu ve size değerleri yükseldikçe dağılım normal dağılıma evrildiğini göstermektedir.

Poisson regresyon modeli aşağıdaki eşitlikteki gibi ifa edilebilir. Yöntemde regresyon katsayıları maksimum olasılık ya da maksimum olabilirlik yöntemi (MLE) kullanılarak hesaplanır.

Negatif binom regresyon modeli ise aşağıdaki eşitlikteki gibi gösterilebilir. Bu modelde Poisson regresyon yöntemine benzer olarak regresyon katsayıları maksimum olasılık (maksimum likehood) yöntemi kullanılarak tahmin edilir.

Kurulan regresyon analiz modellerinde güvenilir bir regresyon modeli kurmak için örneklem büyüklüğünün asgari şartları karşılaması gerekmektedir. Buna göre;
- Kurulan regresyon modelinin tamamını değerlerdirmek için önerilen minimum örneklem büyüklüğü 50 + 8k‘tır. k burada bağımsız değişkenlerin sayısını göstermektedir. Örneğin bağımsız değişkenlerin sayısı 10 ise minimum örneklem büyüklüğü 50 + 8 X 10 eşitliğinden 130’dur.
- Eğer bireysel olarak bağımsız değişkenler değerlendirilecek ise minimum örneklem büyüklüğü 104 + k‘tır. Örneğin bağımsız değişkenlerin sayısı 10 ise minimum örneklem büyüklüğü 104 + 8 eşitliğinden 112’dir.
- Diğer taraftan örneklem büyüklüğü ve bağımsız değişkenin sayısına göre Cohen’in kriterini kullanarak etki büyüklüğünü hesaplayabiliriz. Cohen’in etki büyüklüğü örneklem büyüklüğü ve bağımsız değişken sayısı artıkça etki büyüklüğü azalış göstermektedir. Bu durum istenen bir durumdur. Cohen’in etki büyüklüğü R= k / (N-1) formülü ile hesaplanmaktadır. k burada bağımsız değişken sayısını, N ise örneklem / popülasyon büyüklüğünü / gözlem sayısını göstermektedir. Yukarıdaki veriler kullanılarak örnek vermek gerekirse 8 / ( 112-1) =0,07‘dir. R katsayısının 0 olması etki olmadığı anlamına gelmektedir ki, bu durumda örneklem büyüklüğünün ve değişken sayısının kurulan regresyon modelinde optimal noktaya ulaştığı anlamına gelir.
Veri seti
“warpbreaks” veri setinde bağımlı değişken olan breaks (mola sayısı) tahmin edilmiştir. Diğer bir ifadeyle, bu çalışmada regresyon problemi çözmüş olacağız. Veri setindeki toplam gözlem sayısı 54, değişken sayısı ise 3’tür. Bu veri setine R programlama yazılımında “warpbreaks” olarak yer verilmiştir. Veri setindeki gözlem sayısı yukarıda verilen asgari örneklem sayılarını karşılamasa da literatürde parametrik testler için önerilen örneklem büyüklüğü ya da gözlem sayısı 30 ve üzeri olduğu için burada kullanılmıştır. Veri setinde değişkenlerin adları anlaşılması adına Türkçe olarak düzenlenmiştir. Veri setinde yer alan değişkenler ve değişkenlerin veri tipleri şöyledir:
- molasayisi (breaks): Veri tipi nicel ve kesikli sayma sayılarından oluşmaktadır.
- yuntipi (wool): Veri tipi nitel ve kategorik olup, A ve B kategorilerinden oluşmaktadır.
- gerginlik (tension): Veri tipi nitel ve kategorik olup, Düşük, Orta ve Yüksek kategorilerinden oluşmaktadır.
Bu kapsamda cevap değişkeni (bağımlı değişken) olan “molasayisi” geri kalan 2 bağımsız değişken kullanılarak tahmin edilecektir. Analizde kullanılan veri setini aşağıdaki linkten indirebilirsiniz.
Şimdi veri setini tanıdıktan sonra adım adım (step by step) analize başlayabiliriz. Analizde R programlama dili kullanarak analiz adımları R kod bloklarında verilmiştir.
Yüklenecek R kütüphaneleri
rm(list=ls())
kütüphaneler = c("dplyr","tibble","tidyr","ggplot2","formattable","readr","readxl","xlsx", "pastecs","fpc", "DescTools","e1071", "DMwR","caret", "viridis","GGally","ggpurr","effect","psych","writexl","ggfortify","explore","MASS")
sapply(kütüphaneler, require, character.only = TRUE)
Ver setinin okunması ve değişkenlerin Türkçe olarak revize edilmesi
veri<-warpbreaks %>% as_tibble() %>% rename(molasayisi=breaks, yuntipi=wool, gerginlik=tension)%>% mutate(gerginlik=recode_factor(gerginlik, L="Dusuk", M="Orta", H="Yuksek"))
Ver setinin xlsx dosyasına yazdırılması
write_xlsx(veri, "veriseti.xlsx")#xlsx dosyası için
Veri setinin görselleştirilmesi ve tanımlayıcı istatistikler
#veri setindeki değişkenlerin görselleştirilmesi
veri %>% explore_all()
#veri setindeki ilk 10 gözlem
formattable(head(veri,10))
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki değişkenlerin grafiği aşağıda verilmiştir. Grafikte görüleceği üzere eksik gözlem (missing data: NA) bulunmamaktadır.
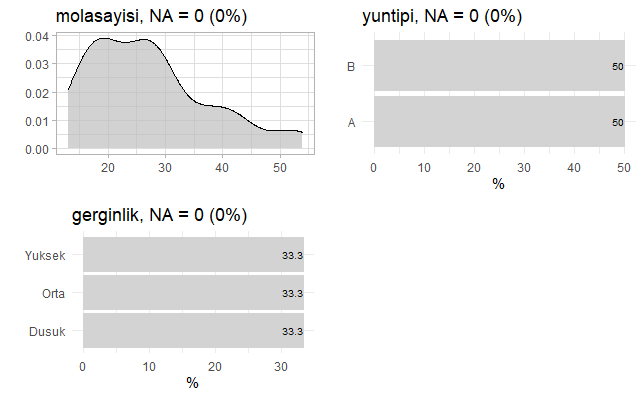
Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki ilk 10 gözlem aşağıdaki tabloda verilmiştir.
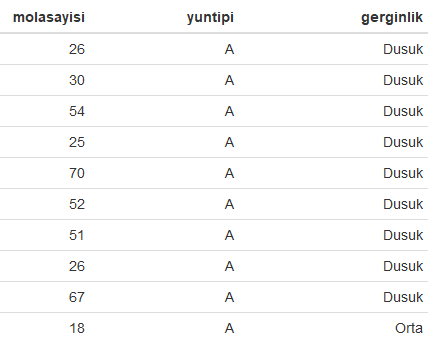
Kategorik değişkenlere göre mola sayılarının dağılımı
ggplot(veri)+
geom_col(aes(x = molasayisi, y = yuntipi, fill = gerginlik))+
facet_wrap(~gerginlik)+
theme(axis.text.x = element_text(angle = 90))
Cevap değişkeni Yukarıdaki R kod bloğunun çalıştırılmasından sonra veri setindeki kategorik değişkenlere göre mola sayısının dağılımı aşağıdaki grafikte verilmiştir. Aşağıdaki grafik değişkenlere bir bütün olarak yaklaşmanıza katkı sağlamış olacaktır.

Nicel değişkenlerin normal dağılıma uyup uymadığının kontrol edilmesi
Bu kısımda normalitenin testinde her ne kadar Shapiro-Wilk testi kullanılsa da Kolmogorow-Smirnov testinin de kullanılabileceğini ifade etmede fayda bulunmaktadır. Ayrıca verinin normal dağılıma uyup uymadığı kutu diyagramlarda uç değerlere bakılarak ve Cook’un mesafesine bakılarak da görülebilir. Diğer taraftan çarpıklık ve basıklık değerleri de verinin normal dağılıma uyup uymadığı noktasında bizlere önemli ipuçları verebilir, bunları hatırlatmakta fayda var.
#Q-Q plot ile molasayisi değişkeninin normal dağılıma uyumu incelenmiştir.
ggqqplot(veri$molasayisi, ylab = "Mola Sayısı", color="red")
#Normalite testi
shapiro.test(veri$molasayisi)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra molasayisi değişkeninin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafiği aşağıda verilmiştir.
Yukarıdaki R kod bloğunun çalıştırılmasından sonra bağımlı değişkenin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafiği aşağıda verilmiştir.

Normalitenin testi için kullanılan Shapiro-Wilk testi sonuçları ise aşağıda verilmiştir. Elde edilen bulgular, p değeri 0,05’ten küçük olduğu için molasayisi değişkeni normal dağılım göstermemektedir.
Shapiro-Wilk normality test
data: veri$molasayisi
W = 0.89251, p-value = 0.0001581
Poisson olasılık dağılımına göre değişkenin ortalaması ve varyansı birbirine eşit veya çok yakın olmalıdır. Aşağıda yazılan R kod bloğunda bağımlı değişken olan mola sayısının ortalama ve varyansların eşit veya birbirine yakın olup olmadığına bakalım. Elde edilen bulgulardan şu anki durumda varyans (174.2041) değerinin ortalama (28.14815) değerinin çok üzerinde olduğunu göstermektedir. Bu durum kurulacak modelde aşırı yayılım (overdispersion) endişesini artırmakla birlikte bağımlı değişkenin poisson dağılımda varyansın ortalamaya eşit veya ona yakın olması kuralını ihlal edilmesi anlamına da gelmektedir.
mean(veri$molasayisi);var(veri$molasayisi)#Ortalama ve Varyans Sırasıyla: 28.14815, 174.2041
Aşağıda yazılan R kod bloğu ile bağımlı değişkenin Poisson ve negatif binom dağılımına uyup uymadığına bakmak için hem histogramını çizelim hem de uyum iyiliği (goodness of fit) testlerini yapalım.
#Bağımlı değişkenin histogramı
ggplot(veri, aes(x=molasayisi))+geom_bar(bins=100,binwidth=.5, fill="red")+
xlab("")+
ylab("Sıklık")+
ggtitle("Mola Sayısı Değişkeni Histogramı")+
theme_replace()
#uyum iyiliği testleri
library(vcd)
#poisson dağılımı uyum iyiliği testi
ozet<-table(veri$molasayisi)
uyum <- goodfit(ozet, type = "poisson", method = "MinChisq")
summary(uyum)
#negatif binom dağılımı uyum iyiliği testi
ozet<-table(veri$molasayisi)
uyum <- goodfit(ozet, type = "nbinomial", method = "MinChisq")
summary(uyum)
Yukarıdaki R kod bloğunun ilgili satırı çalıştırıldığında bağımlı değişken olan mola sayısının histogramı aşağıda verilmiştir. Elde edilen grafik mola sayısının poisson dağılımına çok da uyum göstermemiş görünüyor.
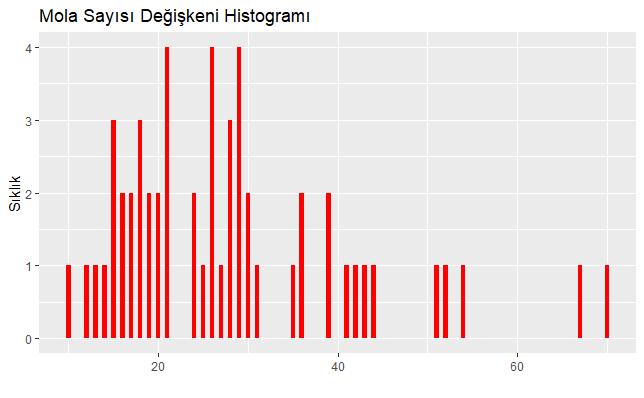
Histogram bize net bilgi vermediği için R kod bloğundaki ilgili satırlarda sırasıyla ilk olarak Poisson dağılımı uyum iyiliği test sonuçları aşağıda verilmiştir. Elde edilen sonuçlar istatistiksel olarak anlamlı olduğu için mola sayısı değişkeni Poisson dağılımına uygun değildir (p<0,05).
Goodness-of-fit test for poisson distribution
X^2 df P(> X^2)
Pearson 167868 69 0
Değişkenimizin Poisson dağılıma uyum sağlamadığını biliyoruz. Bu yüzden R kod bloğunda ilgili satırı çalıştırarak değişkenin negatif binom dağılımına uygun olup olmadığını test edelim.Elde edilen bulgular istatistiksel olarak anlamlı olmadığı için mola sayısı değişkeni negatif binom dağılımına uygundur (p>0,05).
Goodness-of-fit test for nbinomial distribution
X^2 df P(> X^2)
Pearson 50.92181 68 0.9394755
Poisson regresyon modelinin kurulması
Kurulan Poisson regresyon modelinde bağımlı değişken molasayisi, diğer değişkenler ise bağımsız olup, regresyon modeline ilişkin R kod bloğu aşağıda verilmiştir.
model1 <-glm(molasayisi ~., data = veri, family = poisson)
summ(model1)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen regresyon model özeti aşağıda verilmiştir. Çıktıda yer verilen AIC (Akaike information criterion) parametresi kurulan tek bir modelin değerlendirilmesinde çok fazla anlam ifade etmemekle birlikte BIC (Akaike information criterion) parametresinde olduğu gibi ne kadar düşük olursa kurulan modelin o kadar gözlem verisine uyum sağladığını göstermektedir. Bu açıdan bakıldığında aslında bu iki parametrenin kurulan birden fazla modelin performansının değerlendirilmesinde kullanılması daha uygundur.
Call: glm(formula = molasayisi ~ ., family = poisson, data = veri)
Coefficients:
(Intercept) yuntipiB gerginlikOrta gerginlikYuksek
3.6920 -0.2060 -0.3213 -0.5185
Degrees of Freedom: 53 Total (i.e. Null); 50 Residual
Null Deviance: 297.4
Residual Deviance: 210.4 AIC: 493.1
[1] 1
MODEL INFO:
Observations: 54
Dependent Variable: molasayisi
Type: Generalized linear model
Family: poisson
Link function: log
MODEL FIT:
χ²(3) = 86.98, p = 0.00
Pseudo-R² (Cragg-Uhler) = 0.80
Pseudo-R² (McFadden) = 0.15
AIC = 493.06, BIC = 501.01
Standard errors: MLE
----------------------------------------------------
Est. S.E. z val. p
--------------------- ------- ------ -------- ------
(Intercept) 3.69 0.05 81.30 0.00
yuntipiB -0.21 0.05 -3.99 0.00
gerginlikOrta -0.32 0.06 -5.33 0.00
gerginlikYuksek -0.52 0.06 -8.11 0.00
----------------------------------------------------
Aşağıda yazılan R kod bloğunda kurulan 1 nolu modelde yayılım (dispersion) olup olmadığına bakalım.
formattable(tibble(Artik_Sapma = deviance(model1),
Artik_Serbestlik_Derecesi = df.residual(model1),
Yayilim_Degeri=deviance(model1)/df.residual(model1),
Kikare_p_Degeri = pchisq(deviance(model1), df.residual(model1), lower = F)))
#alternatif adım adım
deger<-deviance(model1)#210.39
sd<-model1$df.residual#artıkların serbestlik derecesi
asiriyayilim<-deger/sd# artıkların serbestlik derecesine bölünmesi sonucu elde edilen değer 1'den büyükse kurulan model veriye uymadığını göstermekte ve aşırı yayılım (overdispersion) olduğunu göstermektedir.
asiriyayilim #4.207838 yani Pearson X2/50 = 4.207838
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen yayılım (dispersion) değeri aşağıda verilmiştir. Literatürde artıkların serbestlik derecesine bölünmesi sonucu elde edilen değer 1’den büyükse kurulan model veriye uymadığını göstermekte ve aşırı yayılım (overdispersion) olduğunu göstermektedir. Elde edilen bulgulara göre yayılım değeri 1’in çok üzerinde olduğu ve istatistiksel olarak anlamlı olduğu için burada aşırı yayılımın olduğunu söyleyebiliriz (Pearson X2/50 = 4.207838, p<0,05). Bu durumda eğer aşırı yayılım varsa negatif binom regresyon yönteminin denenmesi gerekmektedir.

Negatif binom regresyon modelinin kurulması
1 nolu modelde aşırı yayılım olduğu tespit edilmesinden dolayı yazılan aşağıdaki R kod bloğunda 2 nolu negatif binom regresyon modeli kurulmuştur.
model2 <-glm.nb(molasayisi ~., data = veri)
summary(model2)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen negatif binom regresyon model özeti aşağıda verilmiştir.
Call:
glm.nb(formula = molasayisi ~ ., data = veri, init.theta = 9.944385436,
link = log)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.0144 -0.9319 -0.2240 0.5828 1.8220
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.6734 0.0979 37.520 < 2e-16 ***
yuntipiB -0.1862 0.1010 -1.844 0.0651 .
gerginlikOrta -0.2992 0.1217 -2.458 0.0140 *
gerginlikYuksek -0.5114 0.1237 -4.133 3.58e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for Negative Binomial(9.9444) family taken to be 1)
Null deviance: 75.464 on 53 degrees of freedom
Residual deviance: 53.723 on 50 degrees of freedom
AIC: 408.76
Number of Fisher Scoring iterations: 1
Theta: 9.94
Std. Err.: 2.56
2 x log-likelihood: -398.764
Şimdi kurulan 2 nolu modelde aşırı yayılım olup olmadığını aşağıda yazılan R kod bloğu ile test edelim.
model2 <-glm.nb(molasayisi ~., data = veri)
formattable(tibble(Artik_Sapma = deviance(model2),
Artik_Serbestlik_Derecesi = df.residual(model2),
Yayilim_Degeri=deviance(model2)/df.residual(model2),
Kikare_p_Degeri = pchisq(deviance(model2), df.residual(model2), lower = F)))
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen yayılım (dispersion) değeri aşağıda verilmiştir. Elde edilen bulgulara göre yayılım değeri yaklaşık 1 ve istatistiksel olarak anlamlı olmadığı için burada aşırı yayılımın olmadığı, aksine eşit yayılım olduğunu söyleyebiliriz.

Model karşılaştırmaları
Kurulan modelleri AIC ve BIC değerleri açısından karşılaştıralım. AIC ve BIC değerlerinin düşük olması tahmin edilen değerlerle gözlem verilerine uyum açısından istenen bir durum olduğu daha önce belirtilmişti. Elde edilen sonuçlar Model 2’nin AIC ve BIC değerleri daha düşük olduğundan Model 1’e göre daha iyi tahmin sonuçları ortaya koyduğu söylenebilir.
model1 <-glm(molasayisi ~., data = veri, family = poisson)
model2 <-glm.nb(molasayisi ~., data = veri)
stargazer(model1,model2, scale=F, type="text", digits=3)
#alternatif
export_summs(model1, model2, scale = F, results = 'asis')
Yukarıdaki R kod bloğu çalıştırıldıktan sonra kurulan modellere ilişkin karşılaştırmalı raporlar aşağıda tablolarda verilmiştir. Ortaya konulan bulgular AIC ve BIC parametrelerinde olduğu gibi 2 nolu model 1 nolu modele göre daha az hata üretmektedir. Dolayısıyla bu bulgulara bakarak 2 nolu modelin daha iyi olduğu ileri sürülebilir.
==============================================
Dependent variable:
----------------------------
molasayisi
Poisson negative
binomial
(1) (2)
----------------------------------------------
yuntipiB -0.206*** -0.186*
(0.052) (0.101)
gerginlikOrta -0.321*** -0.299**
(0.060) (0.122)
gerginlikYuksek -0.518*** -0.511***
(0.064) (0.124)
Constant 3.692*** 3.673***
(0.045) (0.098)
----------------------------------------------
Observations 54 54
Log Likelihood -242.528 -200.382
theta 9.944*** (2.561)
Akaike Inf. Crit. 493.056 408.764
==============================================
Note: *p<0.1; **p<0.05; ***p<0.01
Yukarıdaki R kod kod bloğunda ilgili alan çalıştırılınca BIC değerlerinin ve pseudo R^2 olduğu alternatif bir rapor da üretebiliriz. Bu tamamen karar vericiye bağlıdır.
─────────────────────────────────────────────────────
Model 1 Model 2
───────────────────────────────────
(Intercept) 3.69 *** 3.67 ***
(0.05) (0.10)
yuntipiB -0.21 *** -0.19
(0.05) (0.10)
gerginlikOrta -0.32 *** -0.30 *
(0.06) (0.12)
gerginlikYuksek -0.52 *** -0.51 ***
(0.06) (0.12)
───────────────────────────────────
N 54 54
AIC 493.06 408.76
BIC 501.01 418.71
Pseudo R2 0.80 0.29
─────────────────────────────────────────────────────
*** p < 0.001; ** p < 0.01; * p < 0.05.
Column names: names, Model 1, Model 2
Kurulan regresyon modellerine göre regresyon katsayıları
Aşağıda yazılan R kod bloğu ile regresyon katsayı büyüklükleri kurulan modellere göre karşılaştırmalı olarak verilmiştir.
#normalize edilmemiş katsayı büyüklükleri
plot_summs(model1, model2, scale = F, exp = TRUE)+
ggtitle("Modellere Göre Regresyon Katsayıları")
#normalize edilmiş katsayı büyüklükleri
plot_summs(model1, model2, scale = F, exp = TRUE) +
ggtitle("Modellere Göre Normalize Edilmiş Regresyon Katsayıları")
Yukarıdaki R kod bloğunun ilk satırının çalıştırılmasından sonra kurulan regresyon modellerine göre elde edilen regresyon katsayıları aşağıdaki grafikte verilmiştir. Burda Model 1 Poisson regresyon modeli, Model 2 ise negatif regresyon modeli olduğunu tekrar hatırlatmakta fayda var.
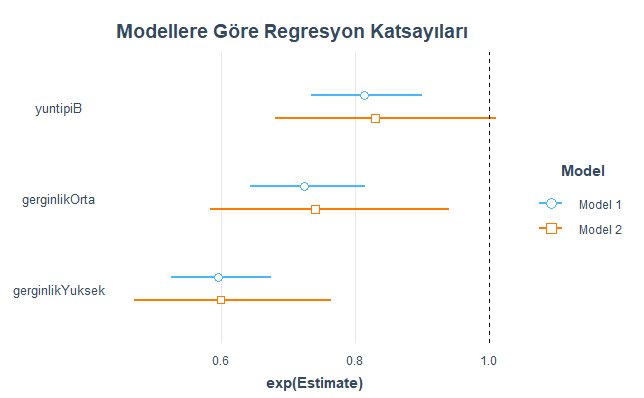
Yukarıdaki R kod bloğunun ikinci satırının çalıştırılmasından sonra kurulan regresyon modellerine göre elde edilen normalize edilmiş regresyon katsayıları aşağıdaki grafikte verilmiştir.
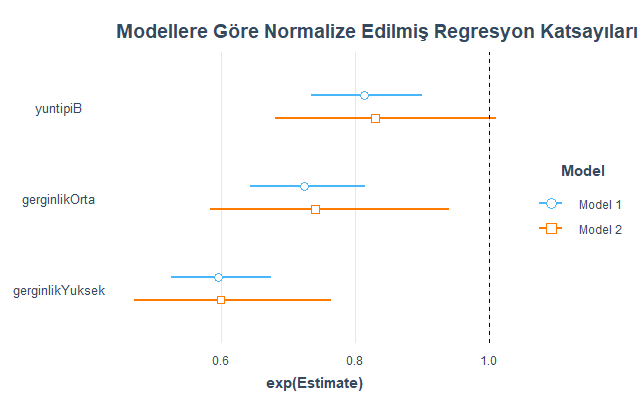
Bağımsız değişkenler ile bağımlı değişken arasındaki etkileşim düzeyleri
Kurulan 2 nolu model (negatif binom regresyon)’de bağımsız değişkenlerin her birinin bağımlı değişken üzerindeki etkisini ölçümlemeye yönelik aşağıda yazılan R kod bloğu ile karşılaştırmalı olarak verilmiştir.
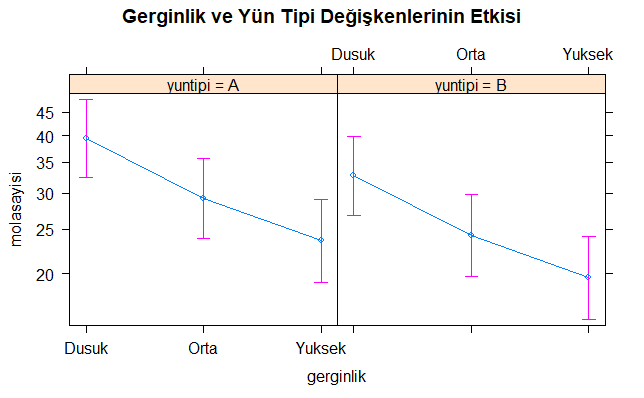
plot(Effect(focal.predictors = c("gerginlik", "yuntipi"),model2), main="Gerginlik ve Yün Tipi Değişkenlerinin Etkisi")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen değişkenlerin etki düzeyleri aşağıdaki grafikte verilmiştir. Burada, yün tipi A olduğu zaman mola sayısındaki artış B’ye göre daha yüksektir. Diğer taraftan, gerginlik seviyesi yükseldikçe mola sayısında düşüş olduğu görülmektedir. Her iki bağımsız değişken birlikte değerlendirildiğinde yün tipinin A ve gerginlik seviyesinin Düşük olduğu durumda mola sayısı en yüksek seviyesine ulaşmıştır.
Yapılan bu çalışma ile özellikle veri bilimi (data science) ile ilgilenen akademi ve saha çalışanlarına bir katkı sunulması amaçlanmıştır.
Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
- https://www.r-project.org/
- https://ncss-wpengine.netdna-ssl.com/wp-content/themes/ncss/pdf/Procedures/NCSS/Negative_Binomial_Regression.pdf
- https://tevfikbulut.com/2020/07/15/rda-coklu-dogrusal-regresyon-uzerine-bir-vaka-calismasi-a-case-study-on-multiple-linear-regression-mlr-in-r/
- Tippett, L. H. C. (1950) Technological Applications of Statistics. Wiley. Page 106.
- https://www.rdocumentation.org/packages/vcd/versions/1.4-7/topics/goodfit
- https://dergipark.org.tr/tr/download/article-file/548350
- https://statistics.laerd.com/spss-tutorials/poisson-regression-using-spss-statistics.php#:~:text=A%20Poisson%20distribution%20assumes%20a,added%20to%20the%20Poisson%20regression.
- https://web.stanford.edu/~hastie/TALKS/boost.pdf
- https://dergipark.org.tr/en/pub/ijeased/issue/50819/703566
- https://iq.opengenus.org/types-of-boosting-algorithms/
- https://tevfikbulut.com/2020/05/21/r-programlama-diliyle-regresyon-problemlerinin-cozumunde-rastgele-orman-algoritmasi-uzerine-bir-vaka-calismasi-a-case-study-on-random-forest-rf-algorithm-in-solving-regression-problems-with-r-progr/
- https://www.stat.berkeley.edu/~breiman/Using_random_forests_V3.1.pdf
- https://www.stat.berkeley.edu/~breiman/RandomForests/
- https://stats.idre.ucla.edu/r/library/r-library-introduction-to-bootstrapping/
- https://stanford.edu/~shervine/l/tr/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks
- http://uzalcbs.org/wp-content/uploads/2016/11/2012_082.pdf
- http://www.ub.edu/stat/docencia/EADB/bagging.html
- https://people.cs.pitt.edu/~milos/courses/cs2750-Spring04/lectures/class23.pdf
- https://www.google.com/search?q=underfitting+and+overfitting&source=lnms&tbm=isch&sa=X&ved=2ahUKEwiI1onvyNvpAhVSQMAKHfYyC28Q_AUoAXoECBAQAw&biw=1366&bih=604#imgrc=m5WcPcAqdpCwEM
- Webb G.I. (2011) Overfitting. In: Sammut C., Webb G.I. (eds) Encyclopedia of Machine Learning. Springer, Boston, MA
- https://www.memorial.com.tr/saglik-rehberleri/biyopsi-nedir-ve-nasil-yapilir/
- https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
- Andriyas, S. and McKee, M. (2013). Recursive partitioning techniques for modeling irrigation behavior. Environmental Modelling & Software, 47, 207–217.
- Chan, J. C. W. and Paelinckx, D. (2008). Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sensing of Environment, 112(6), 2999–3011.
- Chrzanowska, M., Alfaro, E., and Witkowska, D. (2009). The individual borrowers recognition:Single and ensemble trees. Expert Systems with Applications, 36(2), 6409–6414.
- De Bock, K. W., Coussement, K., and Van den Poel, D. (2010). Ensemble classification based on generalized additive models. Computational Statistics & Data Analysis, 54(6), 1535–1546.
- De Bock, K. W. and Van den Poel, D. (2011). An empirical evaluation of rotation-based ensemble classifiers for customer churn prediction. Expert Systems with Applications, 38(10), 12293–12301.
- Fan, Y., Murphy, T.B., William, R. and Watson G. (2009). digeR: GUI tool for analyzing 2D DIGE data. R package version 1.2.
- Garcia-Perez-de-Lema, D., Alfaro-Cortes, E., Manzaneque-Lizano, M. and Banegas-Ochovo, R. (2012). Strategy, competitive factors and performance in small and medium enterprise (SMEs).
- African Journal of Business Management, 6(26), 7714–7726.
- Gonzalez-Rufino, E., Carrion, P., Cernadas, E., Fernandez-Delgado, M. and Dominguez-Petit, R.(2013). Exhaustive comparison of colour texture features and classification methods to discriminate cells categories in histological images of fish ovary. Pattern Recognition, 46, 2391–2407.
- Krempl, G. and Hofer, V. (2008). Partitioner trees: combining boosting and arbitrating. In: Okun, O., Valentini, G. (eds.) Proc. 2nd Workshop Supervised and Unsupervised Ensemble Methods and Their Applications, Patras, Greece, 61–66.
- Torgo, Luis, Data Mining With R. Second Edition.
- https://www.akira.ai/glossary/gradient-boosting/
- http://www.ccs.neu.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf
- Breiman, L. (June 1997). “Arcing The Edge” (PDF). Technical Report 486. Statistics Department, University of California, Berkeley.
- http://acikerisim.ktu.edu.tr/jspui/handle/123456789/743
- https://dergipark.org.tr/tr/download/article-file/219865
- Discovering Statistics Using SPSS (2009), Field, A.
- https://www.jmp.com/en_ch/statistics-knowledge-portal/what-is-multiple-regression/fitting-multiple-regression-model.html
- https://marcfbellemare.com/
- https://www.statisticshowto.com/variance-inflation-factor/
- https://www.rdocumentation.org/packages/psych/versions/1.9.12.31/topics/cor.plot
- https://www.rdocumentation.org/packages/caret/versions/6.0-86/topics/findCorrelation
- https://tevfikbulut.com/2020/07/04/rda-binary-lojistik-regresyon-uzerine-bir-vaka-calismasi-a-case-study-on-binary-logistic-regression-in-r/
- https://cran.r-project.org/web/packages/relaimpo/relaimpo.pdf