Giriş
Genel olarak pozitif, negatif ve nötr dilin ölçümü anlamına gelen duygu analizi, fikir madenciliği (opinion mining) olarak da anılır. Nitel araştırmanın bir yönünü oluşturan bu analizle ürünlerden, reklamlardan, lokasyonlardan, reklamlardan ve hatta rakiplerden ortaya çıkan müşteri düşüncelerini açığa çıkarılabilmektedir. Müşterilerin hoşlandığı veya hoşlanmadığı ürünlerin tespitinde bu analiz önemli rol oynayarak ürün gamı ve ürünün kalitesi şekillendirilebilmektedir. Diğer bir deyişle, firmalar müşterilerin ne hissettiğini ve düşündüğünü bilerek müşteri beklentilerini daha iyi karşılayabilir. Sağlık sektöründe de benzer durum söz konusu olabilir. Hasta beklentileri, algıları ve yönetiminin analizleri ile sağlık krizlerinde fikirlerin analizinde duygu analizlerinin yoğun bir şekilde kullanıldığı literatürden yakinen bilinmektedir. Literatürde aynı zamanda duygu analizlerinden önce kelime bulutlarının oluşturulduğu da görülmektedir.
Veri madenciliğinin (data mining) bir kolunu oluşturan metin madenciliği (text mining) metotları içinde kelime bulutları (word clouds) metinlerde en sık kullanılan anahtar kelimeleri vurgulamamıza ve görselleştirmemize olanak tanır. Bu metotlarla metin verisinden metin bulutu veya etiket bulutu diyebileceğimiz kelime bulutu oluşturulabilir. Kelime bulutları metni hızlı analiz etmemize ve kelime bulutu olarak ortaya çıkan anahtar kelimeleri görselleştirmemize olanak tanır. Bahsedilenler ışığında metin verisini sunmada kelime bulutunu kullanmanız gerektiği durumlar şunlardır:
- Kelime bulutları sadelik ve yalınlık sağlar. En sık kullanılan anahtar kelimeler, kelime bulutu içinde daha iyi kendini gösterir.
- Kelime bulutları potansiyel iletişim araçlarıdır. Kelime bulutlarının anlaşılması, paylaşılması kolaydır ve kelime bulutları etkilidirler.
- Kelime bulutları bir tablo verisinden görsel olarak daha ilgi çekicidir.
Kelime bulutları, sektör ayrımı gözetilmeksizin bütün alanlarda kullanılabilmekle birlikte en sık kullanılan alanlarla en sık kullanılan meslek grupları şöyle özetlenebilir;
- Kalitatif (nitel) araştırma yapan araştırmacılar,
- Müşterilerin ihtiyaçlarının belirlenmesi noktasında pazarlamacılar,
- Temel konuları desteklemek için eğitimciler,
- Politikacı ve gazeteciler
- Kullanıcı görüşlerini toplayan, analiz eden ve paylaşan sosyal medya siteleri
Duygu analizi (sentiment analysis) ise kendisine bir çok farklı alanda uygulama alanı bulmakta olup başlıca kullanım alanları Şekil 1 üzerinde verilmiştir:
Şekil 1: Duygu Analizi Kullanım Alanları
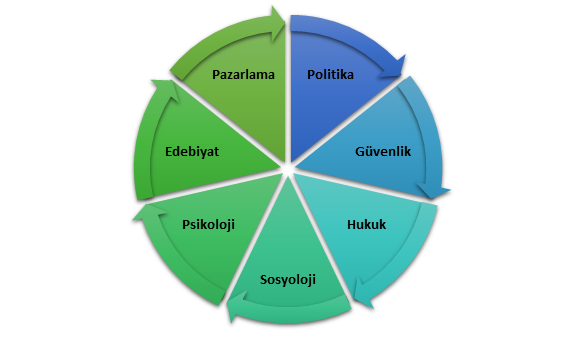
Duygu analizlerinde temel veri kaynaklarının sosyal medya platformları, bilim veri tabanları ve arama motorları verileri olduğu görülmektedir. Duygu analizi çalışmalarında duygu sözlükleri adı verilen “leksikon” lardan yaygın bir şekilde yararlandığı görülmektedir. Literatürde yer alan başlıca leksikonlar Şekil 2’de verilmiştir.
Şekil 2: Duygu Analizinde Kullanılan Duygu Sözlükleri

Şimdi sırayla Şekil 2’de verdiğimiz leksikonlardan kısaca bahsedelim.
Polarite Testi
En basit duygu sözlüğünü oluşturan bu testte skorlar -1 ile 1 arasında değerler almaktadır. Kelime ve cümle bazında yapılan sınıflandırmalarda negatif ve pozitif olmak iki kategori bulunmaktadır.
NRC Leksikonu
Analizde kullanılan metin NRC lexiconu açısından analiz edilmiştir. NRC lexiconu hesaplamalı dil bilimci Saif Mohammad tarafından geliştirilmiş olup bu leksikon sözlüğünde 10 duygu bulunmaktadır. Bu hisler şöyledir;
- positive
- negative
- Anger
- Anticipation
- Disgust
- Fear
- Joy
- Sadness
- Surprise
- Trust
Afinn Leksikonu
Afinn dil sözlüğü, 2009 ve 2011 yılları arasında Finn Årup Nielsen tarafından geliştirilmiş olup dil sözlüğünde skorlar -5 (negatif) ve +5 (pozitif) arasında tamsayı değerleri almaktadır.
Bing Leksikonu
Bing leksikonunda ise duygular basit bir şekilde negatif ve pozitif olarak sınıflandırılarak skorlanır.
Syuzhet Leksikonu
Syuzhet, Nebraska Dil Bilim Laboratuarında (Nebraska Literary Lab) geliştirilmiş bir duygu sözlüğüdür. “Syuzhet” adı, metni “fabula” ve “syuzhet” olmak üzere iki bileşene ayıran Rus formalist Victor Shklovsky ve Vladimir Propp’tan gelmektedir.
Loughran Leksikonu
Finansal belgelerde kullanılmak üzere geliştirilmiş duygu sözlüğüdür. Bu sözlük, kelimeleri finansal bağlamlarında ele almakta olup altı duygu kategorisinden oluşmaktadır: “olumsuz”, “pozitif”, “ihtilaflı”, “belirsizlik”, “kısıtlayıcı” veya “gereksiz” (“negative”, “positive”, “litigious”, “uncertainty”, “constraining”, or “superfluous”).
Esasında bu platform üzerinde R programlama dili kullanarak duygu analizleri üzerine 2018 yılında, kelime bulutları üzerine ise farklı tarihlerde örnek uygulamalar yapmıştım. Ancak R kodları açık kaynak olarak paylaşmamıştım. Bu çalışma kapsamında yapılan örnek uygulama ile ilk olarak metnin kelime bulutları oluşturulmuş, ardından ise dil sözlükleri kullanılarak eş zamanlı olarak duygu analizleri yapılmıştır. Aşağıda göreceğiniz üzere en ince ayrıntısına kadar bütün R kodları paylaşılmıştır. Yapacağınız tek şey minor değişikliklerle kendi çalışmalarınıza uyarlamanızdır. Ancak temel R programlama bilginizin olması tavsiye edilir.
Metodoloji ve Uygulama Sonuçları
Örnek uygulama kapsamında ilk metin verisi 30.01.2021 tarihinde ücretsiz e-kitapların çeşitli formatlarda yayınlandığı “https://www.gutenberg.org/ebooks/50540“ adresinden alınmıştır. Metin verisi olarak alınan eserin adı Zeyneb Hanoum tarafından kaleme alınan Bir Türk Kadınının Avrupa İzlenimleri (A Turkish Woman’s European Impressions)‘dir. Eser 23 Kasım 2015 tarihinde https://www.gutenberg.org sitesinde yayınlanmıştır. Bu metin verisi ile yukarıda linki verilen web uygulaması üzerinden kelime bulutları oluşturulacaktır. Örnek uygulama metnini word (docx) formatında aşağıdaki linkten indirebilirsiniz.
Bir Türk Kadınının Avrupa İzlenimleri
Örnek uygulama kapsamında ikinci metin pdf formatında olup, Dünya Bankası tarafından 5 Ocak 2021 tarihinde 234 sayfalık Küresel Ekonomik Beklentiler (Global Economic Prospects) raporudur. Rapor https://openknowledge.worldbank.org/bitstream/handle/10986/34710/9781464816123.pdf?sequence=15&isAllowed=y url adresinde yayınlanmıştır. Bu raporla ilgili 22 Şubat 2021 tarihinde blog sitemde, 23 Şubat 2021 tarihinde ise Sanayi Gazetesi’nde “Küresel Ekonomik Beklentiler 2021 Ocak Dönemi Raporu” adlı yazım yayımlanmıştır. Raporu incelediğim için acaba bu raporun kelime bulutu ve duygu analizini de yapsam nasıl olur diye kendime sordum 🙂 . Neticede denemesi bedava 🙂 . Bu soru beni bu raporun kelime bulutlarını oluşturmaya ve duygu analizlerini yapmaya itmiştir. Bu çalışma kaynağından okunarak hem kelime bulutları çıkarılmış, ardından duygu analizleri yapılmıştır. İlk örnek uygulamanın aksine bu çalışma pdf formatında olan metinlerin analizini içerdiğinden bu yönüyle farklılık göstermektedir. Bu kısımdaki analiz 3. PDF dokümanların kelime bulutlarının çıkarılması ve duygu analizlerinin yapılması başlığı altında ele alınmıştır.
Örnek uygulama kapsamında 3. çalışma sentetik veriler üretilip kelime bulutlarının oluşturulmasıdır. 3. çalışma kapsamında sentetik olarak üretilen kelimelerin büyük bir çoğunluğu İstiklal Marşımızdan alınmıştır. Burada sentetik verilerin üretilmesinde tekrarlı örnekleme tekniği kullanılmış ve 10.000 gözlem üretilmiştir. Bu gözlemler üzerinde kelime bulutları oluşturulmuştur. Bu bölümdeki analiz ise 4. Sentetik veriler üzerinden kelime bulutlarının oluşturulması başlığı altında irdelenmiştir.
Çalışma kapsamında ilk olarak metnin kelime bulutları oluşturulmuş, ardından ise dil sözlükleri kullanılarak duygu sözlüklerine göre duygu analizleri yapılmıştır. İlk olarak analizde kullanılacak R kütüphanelerini vererek işe başlayalım. Aşağıda gerekenden fazla kütüphane verdiğimi biliyorum. Ancak daha çok esneklik ve estetik tasarım tanıdığı için genellikle olması gerekenden fazla kütüphane ile çalışıyorum. Kelime bulutlarının oluşturulması ve duygu analizlerinde kullanılan temel paketler “sentimentr”,”webshot”,”stringr”, “wordcloud”, “wordcloud2″,”RColorBrewer”, “htmlwidgets”,”syuzhet” paketleridir. Analizlerde R programlama dili kullanılmıştır. Bulguların çalışma kitaplarına yazdırılmasında ise xlsx uzantılı Microsoft Excel çalışma kitapları kullanılmıştır.
Yüklenecek Kütüphaneler
#Kütüphaneler
kütüphane<-c("dplyr","tibble","tidyr","ggplot2","ggthemes","readr","readxl","ggpubr","formattable", "ggstance", "pastecs","writexl", "psych", "GGally","pander", "rstatix", "stringr", "sentimentr","webshot","stringr","wordcloud", "wordcloud2","RColorBrewer", "htmlwidgets","syuzhet", "tidytext", "tm")
yükle<-sapply(kütüphane, require, character.only = TRUE)
# Kütüphane yüklenme durumunu gösteren tablo
tablo=suppressWarnings(yükle, classes = "warning")
isim=names(tablo)
deger=as_tibble(tablo)
data.frame(sira=1:length(isim), kutuphane=isim, yuklenme_durumu=deger$value) %>% mutate(yuklenme_durumu=if_else(yuklenme_durumu==TRUE, "Yuklendi", "Paket Kurulumu Gerekli")) %>% pander(caption="Kütüphane Yüklenme Bilgisi")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra yukarıdaki kütüphanelerin yüklenip yüklenmediğine dair aşağıdaki gibi mantıksal vektör sonuçları gelecektir. Eğer mantıksal vektör sonuçlarının hepsi TRUE ise kütüphanelerin hepsini yüklenmiştir demektir. Kolaylık sağlaması açısından yukarıda kütüphanelerin yüklenmesini gösterir tabloyu da elde etmek ve daha kolay okumanız için yukarıdaki kod bloğu içerisinden kısa bir kod yazdım. Bu kod çalıştırıldığında aşağıdaki tabloda görüleceği üzere bütün kütüphaneler yüklenmiştir. Eğer ilgili kütüphane yüklenmemiş olursa “Paket Kurulumu Gerekli” ifadesi satırda yazacaktır. Satırda yazan bu uyarı metnine göre paketi ya kurar yada yüklersiniz. Bir paketin kurulması ile yüklenmesinin aynı şey olmadığını burada ifade etmek gerekir konuyu yabancı olanlar için. Paket kurulumu ilk defa yapılan bir işlem iken, paketin yüklenmesi zaten kurulan bir paketin yüklenmesi yani çalışır duruma getirilmesidir. İlk defa bir paket kurulumu gerçekleştiriliyorsa install.packages() fonksiyonunu, zaten bir paket kurulumu gerçekleştirilmiş ise ilgili paketin veya kütüphanenin yüklenmesi veya okunması için library() veya require() fonksiyonlarını kullanıyoruz. Fonksiyonlardaki parantez () içerisine yüklenecek paket veya kütüphane adını yazıyoruz.
---------------------------------------
sira kutuphane yuklenme_durumu
------ -------------- -----------------
1 dplyr Yuklendi
2 tibble Yuklendi
3 tidyr Yuklendi
4 ggplot2 Yuklendi
5 ggthemes Yuklendi
6 readr Yuklendi
7 readxl Yuklendi
8 ggpubr Yuklendi
9 formattable Yuklendi
10 ggstance Yuklendi
11 pastecs Yuklendi
12 writexl Yuklendi
13 psych Yuklendi
14 GGally Yuklendi
15 pander Yuklendi
16 rstatix Yuklendi
17 stringr Yuklendi
18 sentimentr Yuklendi
19 webshot Yuklendi
20 stringr Yuklendi
21 wordcloud Yuklendi
22 wordcloud2 Yuklendi
23 RColorBrewer Yuklendi
24 htmlwidgets Yuklendi
25 syuzhet Yuklendi
26 tidytext Yuklendi
27 tm Yuklendi
---------------------------------------
Table: Kütüphane Yüklenme Bilgisi
1. Kelime bulutlarının oluşturulması
Bu kısımda bahse konu metin üzerinden adım adım kelime bulutları oluşturulacaktır. Kelime bulutlarının oluşturulması frekanslara göre oluşturulduğundan metnin dili çok belirleyici olmamaktadır. Ancak duygu analizinde durum biraz farklıdır. Yani duygu analizi yapıyorsanız metnin bulunduğu dili destekleyen bir R kütüphanesi ile çalışmak zorundasınız. Bunu da yeri gelmişken burada ifade etmekte yarar olduğunu düşünüyorum.
Veri setinin okunması
bs1 <- read.delim("metin.txt", col.names = "cumle")
bs1
Veri setindeki ilk 10 satırı tablo formatında aşağıda yazılan kod bloğu ile verebiliriz.
bs1 %>% head(10) %>% formattable()
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen ilk 10 satır aşağıdaki tabloda verilmiştir.

Veri setinin yapısının incelenmesi
Aşağıda yazılan kod bloğu ile veri setindeki değişken tipi ve gözlem sayısı ortaya konulmuştur.
glimpse(bs1)
#alternatif
str(bs1)
Yukarıdaki kod bloğu çalıştırıldığında aşağıda verildiği üzere veri setinin 3,264 gözlemden yani cümleden oluştuğu, değişken tipinin ise karakter yani nominal olduğu görülmektedir. Veri setinin 1 değişkenden oluştuğu ve değişkenin “cumle” olduğu da görülmektedir.
Rows: 3,264
Columns: 1
$ cumle <chr> "This eBook is for the use of anyone anywhere at no cost and with", "almost no restrictions w...
Metin verisinin kelime bulutu oluşturulmadan önce temizlenmesi ve çıkarılacak kelimelerin belirlenmesi
Bu kısımda ilk olarak aşağıda yazılan kelimeler metinden çıkarılacaktır. Bu kısımda ister Türkçe isterse diğer dillerde çıkarılacak kelimeleri belirleyebilirsiniz.
rmv1<-c("may", "can","years","age","mean","diet", "qol","based","dog","two","per","model","will","is","aarc","results","label","among","are","level","cancer", "used","many", "nlm", "data", "study", "p", "n", "net", "biochar", "aloe", "ses", "systems","avs", "acid","rate","aha","year","time","since","stroke", "however", "p lt", "ssris", "score", "index","hia", "largest", "current", "ncds", "found", "labelobjective", "It","yet","models", "vera","total", "also", "ptsd", "lt", "sroi", "icdm", "scores", "new", "arm", "china", "sample", "semen", "survey", "labelconclusions","within","labelbacground","range","followed","tagsnps","mbovis","labeldesign","increased","published", "likely", "nlmcategorymethods", "acids", "fatty", "employersponsored","labelmethods", "using", "conclusions","setting", "whether","findings","crosssectional", "one", "three","review","associated", "analysis", "studies", "nlmcategory", "background", "nlmcategorymethods", "in", "of", "and", "as", "19", "the","have","were","an", "was", "during", "to", "for","a", "cth","or","hcs", "this", "u","ci", "t", "la", "043d", "064a","043b", "062a", "trastuzumab","ewars","research", "either", "ipps73","ippss","87,017", "ofips", "15,000", "eshre","tdabc","thaihealth", "0.157", "and", "analyzed", "methods", "terms", "subjects", "being", "there", "compared", "while", "when", "their","these","between", "his","her", "which", "that","who", "after","related","higher","group", "other","each","those","lower", "number","rates","first", "about", "groups","through","including", "across", "should", "must", "have","months","adjusted", "analyses", "estimated", "could", "would", "without", "further", "versus", "cross", "method", "follow", "general", "under", "below", "estimate","following", "received", "available", "before", "aimed", "collected", "often", "often","include","relevant","having","therefore","because","thus", "gutenberg","almost", "license", "ebook", "anyone", "anywhere", "title", "author", "enough", "nothing", "cannot", "really", "never", "again", "wwwgutenbergorg", "whatsoever", "editor", "chapter","perhaps", "shall", "every","where", "been", "more", "than", "even", "with", "what", "who", "when", "only", "your", "into", "in", "on", "always", "online", "copy", "away", "back", "myself", "still")
Bu kısımda aşağıda yazılan kod bloğundaki satırlarda sırasıyla;
- Metindeki harflerin tamamı küçük harfe dönüştürülmüştür.
- Metindeki noktalama işaretleri kaldırılmıştır.
- Metinle iç içe geçmiş (kızgın325 gibi) rakam ve sayılar metinden ayıklanmıştır.
- Metinden rakam ve sayılar çıkarılmıştır.
- Yukarıdaki belirtilen kelimeler metinden çıkarılmıştır. Burada dikkat edilirse çıkarılan kelimeler daha çok zamir, sıfat, edat ve bağlaçlardır. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
- Karakter sayısı 3’ten büyük kelimeler filtrelenmiştir. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
- Metin istenmeyen formatta kelimeler varsa ve bu kelimeleri çıkarmanız analize zarar verecekse yerine kelimeler atayabilirsiniz.
- Metnin değişiklikler sonrası “tibble” tablo düzenine dönüştürülmüştür.
tr<-bs1 %>% mutate(word=str_to_lower(cumle))%>% unnest_tokens(word, cumle) # Metindeki harflerin tamamı küçük harfe dönüştürülmüştür.
tr<-tr %>% mutate(word=removePunctuation(word)) # Metindeki noktalama işaretleri kaldırılmıştır.
tr<-tr %>% mutate(word=str_squish(word)) # Metinle iç içe geçmiş (kalem325) rakam ve sayılar metinden ayıklanmıştır.
tr<-tr %>% mutate(word=removeNumbers(word)) # Metinden rakam ve sayılar çıkarılmıştır.
tr<-tr %>% filter(!word %in% rmv1) # Yukarıdaki belirtilen kelimeler metinden çıkarılmıştır. Burada dikkat edilirse çıkarılan kelimeler daha çok zamir, sıfat, edat ve bağlaçlardır. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
tr<-tr %>% filter(str_length(word)>3) # Karakter sayısı 3'ten büyük kelimeler filtrelenmiştir. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
tr<-str_replace(tr$word, "[ı]", "i") # Metin istenmeyen formatta kelimeler varsa ve bu kelimeleri çıkarmanız analize zarar verecekse yerine kelimeler atayabilirsiniz.
tr<-tr %>% as_tibble()%>%rename(word=value) # Metnin değişiklikler sonra tibble tablo düzenine dönüştürülmüştür.
tr
Kelime sıklıklarının ortaya konulması
Aşağıda yazılan kod bloğunda metindeki kelimelerin sıklıkları bulunmuş, ardından ise frekansı en yüksek ilk 50 kelime verilmiştir. En sonda ise kelimeler ve frekansları xlsx uzantılı Microsoft Excel çalışma kitabına yazdırılmıştır.
# Kelime sıklıklarının elde edilmesi
sayi<-tr %>% group_by(word) %>% count() %>% arrange(desc(n))
sayi<-sayi %>% add_column(id=1:NROW(sayi),.before = "word")
sayi
#Frekansı en yüksek ilk 50 kelime
sayi %>% head(50) %>% pander(caption="Frekansı En Yüksek İlk 50 Kelime")
#xlsx uzantılı çalışma kitabına sıklıklarına göre kelimelerin yazdırılması
write_xlsx(sayi, "kelimeler.xlsx")
Yukarıdaki kod bloğunda ikinci alt blok çalıştırıldığında elde edilen frekansı en yüksek ilk 50 kelime aşağıda verilmiştir.
---------------------------
id word n
---- ---------------- -----
1 they 250
2 turkish 154
3 from 138
4 women 130
5 life 97
6 little 84
7 them 82
8 woman 79
9 country 66
10 know 66
11 people 64
12 same 55
13 come 54
14 like 54
15 zeyneb 54
16 turkey 52
17 here 50
18 much 50
19 very 50
20 said 47
21 some 47
22 think 46
23 most 44
24 such 43
25 then 43
26 harem 42
27 find 40
28 great 40
29 long 38
30 west 38
31 western 38
32 friend 37
33 ever 36
34 over 35
35 seen 35
36 asked 34
37 came 34
38 understand 34
39 house 32
40 paris 32
41 went 32
42 made 31
43 read 31
44 told 31
45 left 30
46 thought 30
47 constantinople 29
48 seemed 29
49 tell 29
50 another 28
---------------------------
Table: Frekansı En Yüksek İlk 50 Kelime
Yukarıdaki kod bloğunda üçüncü alt blok çalıştırıldığında elde edilen kelimeler ve frekansları xlsx uzantılı Microsoft Excel çalışma kitabına yazdırılmış olup aşağıda linkten indirebilirsiniz.
Kelime bulutlarının oluşturulması
Bu kısımda aynı metinden birden fazla kelime bulutu oluşturulacaktır. İlk kelime bulutunu wordcloud kütüphanesini kullanarak aşağıdaki kod bloğunda verelim. Aşağıda yazılan kod bloğunda kelime frekansımız minimum 20, maksimum 200 olacak şekilde düzenledik. Dilerseniz wordcloud fonksiyonu içerisindeki parametreleri değiştirerek farklı alternatifler deneyebilirsiniz.
set.seed(1923) # Aynı sonuçları almak için sabitlenmiştir.
wordcloud(words = sayi$word, freq = sayi$n, min.freq = 20,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde ettiğimiz kelime bulutu aşağıda verilmiştir. Aşağıdaki kelime bulutunda dikkat edeceğiniz üzere metinde hala temizlenmeyi bekleyen “they”, “whom”, “till”, “does”, “over”, “from”, “just”, “here”, “some” gibi zamir, yardımcı fiiller ve yer zarfları bulunmaktadır. Literatürde yapılan çalışmalarda bu hususa çok dikkat edildiği söylenemez ama siz dikkat etmelisiniz iyi bir araştırma ortaya koymak açısından. Metin verisinin kelime bulutu oluşturulmadan önce temizlenmesi ve çıkarılacak kelimelerin belirlenmesi başlığı altında yer alan kod bloğundaki vektör içerisine bahsettiğim bu kelimeleri girerek kelime bulutundan bu kelimeleri çıkarabilirsiniz.

Şimdi de diğer kütüphanemiz olan wordcloud2‘yi kullanarak kelime bulutları oluşturalım. Burada aynı zamanda oluşturulan kelime bulutu png ve html uzantılı olarak da kaydedilmektedir. Aşağıda yazılan kod bloğunda en yüksek frekansa sahip ilk 250 satırdaki kelimelerin frekansı ele alınmıştır.
#kelime bulutunun oluşturulması
hw1=wordcloud2(head(sayi[,2:3], 250), size=1, minSize = 10, shape = "circle", color = "random-light",backgroundColor = "black")
#html ve png olarak kaydedilmesi
saveWidget(hw1,"26.html",selfcontained = F)
webshot::webshot("26.html","hw1.png",vwidth = 1800, vheight = 1000, delay =10)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde ettiğimiz kelime bulutu aşağıda verilmiştir.

Farklı düzenlerde kelime bulutunu elde etmek mümkündür. Yıldız şeklinde eğer kelime bulutu elde etmek istersek yazacağımız kod bloğunda yapacağımız tek şey shape parametresinde “star” şeklinde değişiklik yapmaktır.
#kelime bulutunun oluşturulması
hw1=wordcloud2(head(sayi[,2:3], 250), size=1, minSize = 10, shape = "star", color = "random-light",backgroundColor = "black")
#html ve png olarak kaydedilmesi
saveWidget(hw2,"27.html",selfcontained = F)
webshot::webshot("27.html","hw1.png",vwidth = 1800, vheight = 1000, delay =10)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde ettiğimiz kelime bulutu aşağıda verilmiştir.

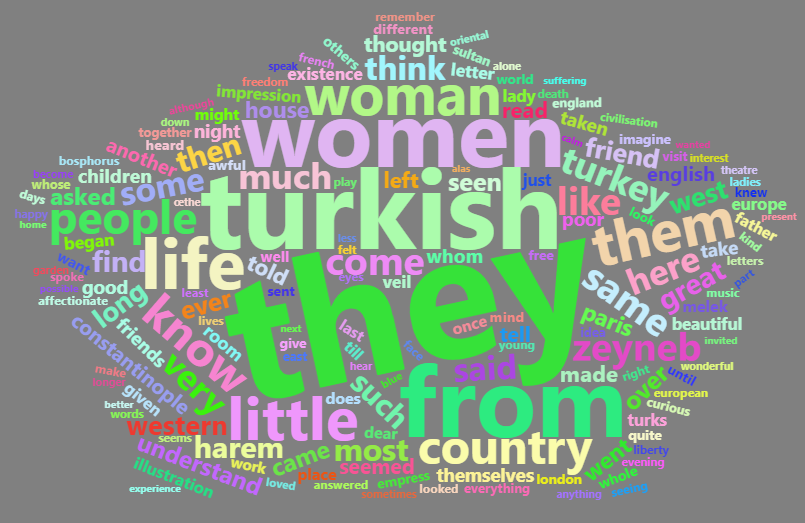
Şimdide aşağıda yazılan kod bloğunda beşgen (pentagon) düzeninde ve gri arka planında başka bir kelime bulutu oluşturalım. Aynı zamanda veri setinde frekansı en yüksek ilk 350 kelimeyi baz alalım.
#kelime bulutunun oluşturulması
hw1=wordcloud2(head(sayi[,2:3], 350), size=1, minSize = 10, shape = "pentagon", color = "random-light",backgroundColor = "grey")
#html ve png olarak kaydedilmesi
saveWidget(hw2,"27.html",selfcontained = F)
webshot::webshot("27.html","hw1.png",vwidth = 1800, vheight = 1000, delay =10)
Yukarıda yazılan kod bloğunun çalıştırılmasından sonra elde edilen beşgen (pentagon) düzeninde ve gri arka planında kelime bulutu aşağıda verilmiştir.
2. Duygu analizlerinin yapılması
Bu kısımda yukarıda giriş kısmında bahsedilen dil sözlükleri kullanılarak duygu analizleri yapılacaktır.
Polarite testi
Bu kısımda aşağıda yazılan kod bloğu ile kelime bazlı polarite testi yapılmıştır. Cümle bazlı polarite testi yapılabileceğini hatırlatmakta fayda vardır.
polarite<-sentiment(tr$word)
tablo<-cbind(tr$word, polarite[,c(3,4)])
ggplot(tablo, aes(word_count, sentiment))+
geom_point(color="blue")+
geom_hline(yintercept = mean(tablo$sentiment), color="red", size=1)+
labs(y = "Skor", x = "Kelimelerin Frekansı") +
theme_igray()+
labs(caption = "Veri Kaynağı: A Turkish Woman’s European Impressions adlı eserden Tevfik Bulut tarafından analiz edilmiştir.") +
theme(plot.caption = element_text(hjust = 0, face = "italic"))
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen polarite skorları aşağıdaki grafikte verilmiştir. Daha önce polarite skorlarının -1 ile +1 arasında değiştiğini ifade etmiştik. Elde edilen bulgular eserde hakim olan duygunun nötr (0)’e yakın olduğunu göstermektedir.

Polarite test sonuçlarına ilişkin tanımlayıcı istatistikler ise aşağıda yazılan kod bloğu ile elde edilmiştir.
stat.desc(polarite$sentiment, basic=T) %>% pander()
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Polarite testi tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Elde edilen ortalama (0,02947) polarite test değeri nötr (0)’e yakın bir görünüm sergilemektedir.
----------------------------------------------------------------------------
nbr.val nbr.null nbr.na min max range sum median mean
--------- ---------- -------- ----- ----- ------- ------- -------- ---------
14754 10936 0 -1 1 2 434.8 0 0.02947
----------------------------------------------------------------------------
Table: Table continues below
-------------------------------------------------------
SE.mean CI.mean.0.95 var std.dev coef.var
---------- -------------- -------- --------- ----------
0.002724 0.00534 0.1095 0.3309 11.23
-------------------------------------------------------
Bing leksikonu
Aşağıda yazılan kod bloğu ile Bing leksikonu duygu grupları (pozitif ve negatif) elde edilmiştir.
d6<-sayi[,-1] %>% inner_join(get_sentiments("bing"),by="word")
d6[,c(1,3,2)]%>% group_by(sentiment) %>% arrange(desc(n)) %>%
top_n(10) %>%
ggplot(aes(x=reorder(word,n), y=n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(
y = "Kelime",
x = "Sıklık"
) +
coord_flip()+
theme_hc()+
labs(caption = "A Turkish Woman’s European Impressions adlı eserden Tevfik Bulut tarafından analiz edilmiştir.")+
theme(plot.caption = element_text(hjust = 0, face = "italic"))
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Bing leksikonu sonuçları kelime frekansı en yüksek olan ilk 10 kelimeye göre aşağıdaki grafikte verilmiştir. Elde edilen bulgular metinde baskın olan duygunun olumlu (pozitif) olduğunu göstermektedir.

Bing leksikonuna ilişkin tanımlayıcı istatistikler ise aşağıda yazılan kod bloğunda verilmiştir.
d6<-sayi[,-1] %>% inner_join(get_sentiments("bing"),by="word")
#duygu grubuna göre frekanslar
d6[,c(1,3,2)]%>% group_by(sentiment) %>% summarise(toplam=sum(n)) %>% mutate(oran=round(toplam/sum(toplam)*100,2)) %>% arrange(desc(oran)) %>% formattable()
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Bing leksikonu tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Aşağıda verilen bulgudan şu bilgi çıkarılmalıdır: Metinde pozitif kelimelerin frekansı ve frekansların oranı (n=1119, frekansların toplam içindeki oranı = %52,09) negatif olanlardan daha yüksek olduğundan metinde pozitif duygu daha ağır basmaktadır.

Afinn leksikonu
Afinn dil sözlüğünde skorlar -5 (negatif) ve +5 (pozitif) arasında tamsayı değerleri almaktadır. Afinn leksikonu bulguları aşağıda yazılan kod bloğu ile elde edilmiştir.
#Afinn leksikon değerlerinin elde edilmesi
d6<-tr %>% inner_join(get_sentiments("afinn"),by="word")
#Tanımlayıcı istatistikler
stat.desc(d6$value, basic=T) %>% pander()
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Afinn leksikonu tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Aşağıda verilen bulgudan şu bilgi çıkarılmalıdır: Afinn leksikon sonuçlarına bakıldığında merkezi dağılım ölçülerinden biri olan ortalama 0,3821 olduğu için metinde nötr (0)’ün biraz üstünde ve pozitife yakın duyguların daha ağırlıkta olduğu söylenebilir.
-------------------------------------------------------------------------
nbr.val nbr.null nbr.na min max range sum median mean
--------- ---------- -------- ----- ----- ------- ----- -------- --------
1879 0 0 -4 4 8 718 1 0.3821
-------------------------------------------------------------------------
Table: Table continues below
-----------------------------------------------------
SE.mean CI.mean.0.95 var std.dev coef.var
--------- -------------- ------- --------- ----------
0.04935 0.0968 4.577 2.139 5.599
-----------------------------------------------------
Loughran leksikonu
Loughran leksikonunda kelimeler altı duygu kategorisinde ele alınır: “olumsuz”, “pozitif”, “ihtilaflı”, “belirsizlik”, “kısıtlayıcı” veya “gereksiz” (“negative”, “positive”, “litigious”, “uncertainty”, “constraining”, or “superfluous”). Loughran leksikonu bulguları aşağıda yazılan kod bloğu ile elde edilmiştir.
#Loughran leksikon değerlerinin elde edilmesi
l1<-tr %>% inner_join(get_sentiments("loughran"),by="word")
#Duygu grubuna göre frekanslar
l1 %>% group_by(sentiment) %>% summarise(toplam=n()) %>% mutate(oran=round(toplam/sum(toplam)*100,2)) %>% arrange(desc(oran)) %>% formattable()
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Loughran leksikonu tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Aşağıda verilen bulgudan şu sonuç çıkarılmalıdır: %45,53 ile negatif duygunun metnin genelinde baskın olduğu görülmektedir. Metinde negatif duyguyu pozitif ve belirsizlik duyguları izlemiştir.

Loughran leksikonu sonuçları aşağıda yazılan kod bloğu ile grafik üzerinde de verebiliriz.
l1 %>%
group_by(sentiment) %>% summarise(n=n())%>%
ggplot(aes(reorder(sentiment, n), n, fill=sentiment)) +
geom_bar(stat="identity", show.legend = FALSE)+
labs(y = "Frekans", x = "Duygu")+
theme_igray()+
labs(caption = "Veri Kaynağı: A Turkish Woman’s European Impressions adlı eserden Tevfik Bulut tarafından analiz edilmiştir.")+
theme(plot.caption = element_text(hjust = 0, face = "italic"))
Yukarıdaki kod bloğu çalıştırıldığında Loughran leksikonuna göre metinden elde edilen duygular aşağıdaki grafikte verilmiştir.

Dil sözlükleri içerisinde duygu kategorisine filtreleme yapmak oldukça kolaydır. Örnek teşkil teşkil etmesi adına Loughran leksikonunda pozitif olarak etiketlenen kelimelerden ilk 50’sini aşağıda yazılan kod bloğu ile verelim. Dilersek pozitif olarak etiketlenen kelimelerin tamamı elde edebilir ve xlsx uzantılı çalışma kitaplarına yazdırabiliriz. Benzer işlemleri diğer dil sözlüklerinde de yapabiliriz.
l1 %>% filter(sentiment=='positive') %>% head(50) %>% pander(caption="Pozitif olarak etiketlenen ilk 50 kelime")
Yukarıdaki kod bloğunun çalıştırılmasından sonra metinde pozitif olarak etiketlenen ilk 50 kelime aşağıdaki tabloda verilmiştir.
-------------------------
word sentiment
------------- -----------
good positive
dream positive
great positive
easy positive
better positive
great positive
greatest positive
diligently positive
progress positive
exclusively positive
great positive
great positive
happiness positive
pleasure positive
great positive
great positive
highest positive
beautiful positive
pleased positive
strength positive
better positive
pleasure positive
perfect positive
delighted positive
impress positive
great positive
best positive
stronger positive
beautiful positive
beautiful positive
winner positive
great positive
satisfied positive
great positive
great positive
beautiful positive
happy positive
greatest positive
easy positive
great positive
great positive
pleasure positive
able positive
stronger positive
invent positive
great positive
better positive
leading positive
compliment positive
great positive
-------------------------
Table: Pozitif olarak etiketlenen ilk 50 kelime
Şimdide Loughran leksikonunda duygulara göre etiketlenmiş kelimelerin tamamını aşağıda yazılan kod bloğu ile verelim.
l1<-tr %>% inner_join(get_sentiments("loughran"),by="word")
write_xlsx(l1, "loughranleksikonu.xlsx")
Yukarıdaki kod bloğunun çalıştırılmasından sonra Loughran leksikonundaki duygu kategorilerine göre etiketlenmiş metindeki bütün kelimeler xlsx uzantılı Microsoft Excel çalışma kitabına yazdırılmış olup aşağıdaki linkten indirebilirsiniz.
Loughran leksikonundaki duygu kategorilerine göre etiketlenmiş 50 kelimeyi olasılıklı örnekleme yöntemlerden biri olan ve önyargı (bias) içermeyen tekrarsız basit tesadüfi örnekleme yöntemi kullanarak seçmek için aşağıdaki gibi basit bir kod satırı yazalım.
set.seed(1985) # Örneklemde aynı gözlem birimlerinin elde edilmesi için sabitlenmiştir.
tr %>% inner_join(get_sentiments("loughran"),by="word") %>% sample_n(50) %>% pander(caption="Basit Tekrarsız Örnekleme Yöntemi İle Seçilen Kelimeler ve Duygu Etiketleri")
Loughran leksikonundaki duygu kategorilerine göre etiketlenmiş 50 kelime tekrarsız basit tesadüfi örnekleme yöntemi kullanarak belirlenmiş ve aşağıdaki tabloda verilmiştir.
-----------------------------
word sentiment
-------------- --------------
exceptional positive
neglected negative
poor negative
doubt uncertainty
unjust negative
delighted positive
strict constraining
hurt negative
possible uncertainty
pleased positive
risk uncertainty
great positive
disastrously negative
error negative
slowly negative
good positive
late negative
probably uncertainty
believed uncertainty
risked uncertainty
good positive
great positive
exposed negative
permissible constraining
force negative
perfect positive
great positive
great positive
ceased negative
might uncertainty
unknowingly negative
lost negative
against negative
strong positive
court litigious
great positive
pleasure positive
suddenly uncertainty
satisfied positive
exaggerate negative
vague uncertainty
believed uncertainty
excitement positive
best positive
great positive
criticism negative
harmful negative
disappointed negative
pleasure positive
suffering negative
-----------------------------
Table: Basit Tekrarsız Örnekleme Yöntemi İle Seçilen Kelimeler ve Duygu Etiketleri
Nrc leksikonu
NRC dil sözlüğünde 10 duygu bulunmaktadır. Bu duygular şöyledir:
- positive
- negative
- Anger
- Anticipation
- Disgust
- Fear
- Joy
- Sadness
- Surprise
- Trust
Aşağıda yazılan kod bloğu ile Nrc leksikonuna göre metindeki duygular ortaya konulmuştur.
#Nrc leksikon değerlerinin elde edilmesi
nrc<-tr %>% inner_join(get_sentiments("nrc"),by="word")
#Duygu grubuna göre frekanslar
nrc %>% group_by(sentiment) %>% summarise(toplam=n()) %>% mutate(oran=round(toplam/sum(toplam)*100,2)) %>% arrange(desc(oran)) %>% formattable()
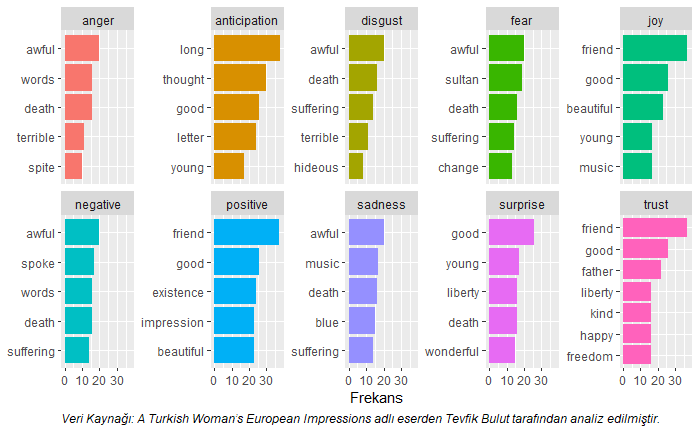
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Nrc leksikonu tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Aşağıda verilen bulgudan şu sonuç çıkarılmalıdır: %22,12 ile pozitif duygunun metnin genelinde baskın olduğu görülmektedir. Metinde pozitif duyguyu negatif ve güven (trust) duyguları izlemiştir.

Nrc leksikonu sonuçlarına frekansı en yüksek ilk 5 kelime duygu kategorilerine göre aşağıda yazılan kod bloğu ile grafik üzerinde de verilmiştir.
nrc %>%
group_by(sentiment) %>%
count(word, sort=T) %>%
top_n(5) %>%
ggplot(aes(reorder(word, n), n, fill=sentiment)) +
geom_bar(stat="identity", show.legend = FALSE) +
facet_wrap(~sentiment, scales="free_y", ncol=5) +
labs(y = "Frekans", x = NULL) +
coord_flip()+
labs(caption = "Veri Kaynağı: A Turkish Woman’s European Impressions adlı eserden Tevfik Bulut tarafından analiz edilmiştir.")+
theme(plot.caption = element_text(hjust = 0, face = "italic"))
Yukarıdaki kod bloğu çalıştırıldığında Nrc leksikonuna göre metinden elde edilen duygular aşağıdaki grafikte verilmiştir.
Syuzhet leksikonu
Syuzhet leksikonu -1 +1 değeri arasında değer almaktadır. Bu leksikona dair bulgular aşağıda yazılan kod bloğu ile elde edilmiştir.
#Syuzhet leksikon değerlerinin elde edilmesi
sskor=get_sentiment(as.vector(tr$word), method="syuzhet")
syuzhet=tibble(kelime=tr$word, skor=sskor)
#Tanımlayıcı istatistikler
stat.desc(syuzhet$skor, basic=T) %>% pander()
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Syuzhet leksikonu tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Aşağıda verilen bulgudan şu bilgi çıkarılmalıdır: Syuzhet leksikon sonuçlarına bakıldığında merkezi dağılım ölçülerinden biri olan ortalama 0,02742 olduğu için metinde nötr (0)’ün biraz üstünde ve pozitife yakın duyguların daha ağırlıkta olduğu söylenebilir. Syuzhet testinde elde edilen ortalama değer ile polarite (negatif ve pozitif duygular) testi sonucu elde edilen ortalama (0,02947) değer birbirine oldukça yakındır.
----------------------------------------------------------------------------
nbr.val nbr.null nbr.na min max range sum median mean
--------- ---------- -------- ----- ----- ------- ------- -------- ---------
14754 11031 0 -1 1 2 404.5 0 0.02742
----------------------------------------------------------------------------
Table: Table continues below
-------------------------------------------------------
SE.mean CI.mean.0.95 var std.dev coef.var
---------- -------------- -------- --------- ----------
0.002631 0.005157 0.1021 0.3196 11.66
-------------------------------------------------------
3. PDF dokümanların kelime bulutlarının çıkarılması ve duygu analizlerinin yapılması
Bu kısımda bahse konu metin üzerinden adım adım kelime bulutları oluşturulacaktır. Kelime bulutlarının oluşturulması frekanslara göre oluşturulduğundan metnin dili çok belirleyici olmamaktadır.
Veri setinin kaynağından okunması
#Raporun bulunduğu URL adresi
url="https://openknowledge.worldbank.org/bitstream/handle/10986/34710/9781464816123.pdf?sequence=15&isAllowed=y"
# Pdf fonksiyonu içerisinde URL adresinin tanımlanması ve dilin ingilizce olarak belirlenmesi doküman ingilizce olduğu için
rapor<- readPDF(control=list(text="-layout"))(elem=list(uri=url), language="en")
rapor <- rapor$content
#Rapor içeriğinin tibble tablo formatına dönüştürülmesi
rp=as_tibble(rapor) %>% rename(cumle=value)
rp
Veri setinin yapısının incelenmesi
Aşağıda yazılan kod bloğu ile veri setindeki değişken tipi ve gözlem sayısı ortaya konulmuştur.
glimpse(rp)
#alternatif
str(rp)
Yukarıdaki kod bloğu çalıştırıldığında aşağıda verildiği üzere veri setinin 234 gözlemden yani cümleden oluştuğu, değişken tipinin ise karakter yani nominal olduğu görülmektedir. Veri setinin 1 değişkenden oluştuğu ve değişkenin “cumle” olduğu da görülmektedir. Bu veri setinde her bir gözlem raporun bir sayfasını göstermektedir. Zira söz konusu rapor da 234 sayfadan oluşmaktadır.
Rows: 234
Columns: 1
$ cumle <chr> "A World Bank Group\r\nFlagship Report\r\n JANUARY 2021\r\n
Metin verisinin kelime bulutu oluşturulmadan önce temizlenmesi ve çıkarılacak kelimelerin belirlenmesi
Bu kısımda ilk olarak aşağıda yazılan kelimeler metinden çıkarılacaktır. Bu kısımda ister Türkçe isterse diğer dillerde çıkarılacak kelimeleri belirleyebilirsiniz.
rmv1<-c("may", "can","years","age","mean","diet", "qol","based","dog","two","per","model","will","is","aarc","results","label","among","are","level","cancer", "used","many", "nlm", "data", "study", "p", "n", "net", "biochar", "aloe", "ses", "systems","avs", "acid","rate","aha","year","time","since","stroke", "however", "p lt", "ssris", "score", "index","hia", "largest", "current", "ncds", "found", "labelobjective", "It","yet","models", "vera","total", "also", "ptsd", "lt", "sroi", "icdm", "scores", "new", "arm", "china", "sample", "semen", "survey", "labelconclusions","within","labelbacground","range","followed","tagsnps","mbovis","labeldesign","increased","published", "likely", "nlmcategorymethods", "acids", "fatty", "employersponsored","labelmethods", "using", "conclusions","setting", "whether","findings","crosssectional", "one", "three","review","associated", "analysis", "studies", "nlmcategory", "background", "nlmcategorymethods", "in", "of", "and", "as", "19", "the","have","were","an", "was", "during", "to", "for","a", "cth","or","hcs", "this", "u","ci", "t", "la", "043d", "064a","043b", "062a", "trastuzumab","ewars","research", "either", "ipps73","ippss","87,017", "ofips", "15,000", "eshre","tdabc","thaihealth", "0.157", "and", "analyzed", "methods", "terms", "subjects", "being", "there", "compared", "while", "when", "their","these","between", "his","her", "which", "that","who", "after","related","higher","group", "other","each","those","lower", "number","rates","first", "about", "groups","through","including", "across", "should", "must", "have","months","adjusted", "analyses", "estimated", "could", "would", "without", "further", "versus", "cross", "method", "follow", "general", "under", "below", "estimate","following", "received", "available", "before", "aimed", "collected", "often", "often","include","relevant","having","therefore","because","thus", "gutenberg","almost", "license", "ebook", "anyone", "anywhere", "title", "author", "enough", "nothing", "cannot", "really", "never", "again", "wwwgutenbergorg", "whatsoever", "editor", "chapter","perhaps", "shall", "every","where", "been", "more", "than", "even", "with", "what", "who", "when", "only", "your", "into", "in", "on", "always", "online", "copy", "away", "back", "myself", "still", "from", "figure", "over", "such")
Bu kısımda aşağıda yazılan kod bloğundaki satırlarda sırasıyla;
- Metindeki harflerin tamamı küçük harfe dönüştürülmüştür.
- Metindeki noktalama işaretleri kaldırılmıştır.
- Metinle iç içe geçmiş (kızgın325 gibi) rakam ve sayılar metinden ayıklanmıştır.
- Metinden rakam ve sayılar çıkarılmıştır.
- Yukarıdaki belirtilen kelimeler metinden çıkarılmıştır. Burada dikkat edilirse çıkarılan kelimeler daha çok zamir, sıfat, edat ve bağlaçlardır. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
- Karakter sayısı 3’ten büyük kelimeler filtrelenmiştir. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
- Metin istenmeyen formatta kelimeler varsa ve bu kelimeleri çıkarmanız analize zarar verecekse yerine kelimeler atayabilirsiniz.
- Metnin değişiklikler sonrası “tibble” tablo düzenine dönüştürülmüştür.
tr<-rp %>% mutate(word=str_to_lower(cumle))%>% unnest_tokens(word, cumle) # Metindeki harflerin tamamı küçük harfe dönüştürülmüştür.
tr<-tr %>% mutate(word=removePunctuation(word)) # Metindeki noktalama işaretleri kaldırılmıştır.
tr<-tr %>% mutate(word=str_squish(word)) # Metinle iç içe geçmiş (kalem325) rakam ve sayılar metinden ayıklanmıştır.
tr<-tr %>% mutate(word=removeNumbers(word)) # Metinden rakam ve sayılar çıkarılmıştır.
tr<-tr %>% filter(!word %in% rmv1) # Yukarıdaki belirtilen kelimeler metinden çıkarılmıştır. Burada dikkat edilirse çıkarılan kelimeler daha çok zamir, sıfat, edat ve bağlaçlardır. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
tr<-tr %>% filter(str_length(word)>3) # Karakter sayısı 3'ten büyük kelimeler filtrelenmiştir. İsteğe bağlı olarak burada değişiklikler yapabilirsiniz.
tr<-str_replace(tr$word, "[ı]", "i") # Metin istenmeyen formatta kelimeler varsa ve bu kelimeleri çıkarmanız analize zarar verecekse yerine kelimeler atayabilirsiniz.
tr<-str_replace(tr$word, "emdes", "emde") # Metin istenmeyen formatta kelimeler varsa ve bu kelimeleri çıkarmanız analize zarar verecekse yerine kelimeler atayabilirsiniz.
rpc<-tr %>% as_tibble() %>% rename(word=value) # Metnin değişiklikler sonrası tibble tablo düzenine dönüştürülmüştür.
rpc
Kelime sıklıklarının ortaya konulması
Aşağıda yazılan kod bloğunda metindeki kelimelerin sıklıkları bulunmuş, ardından ise frekansı en yüksek ilk 100 kelime verilmiştir. En sonda ise kelimeler ve frekansları xlsx uzantılı Microsoft Excel çalışma kitabına yazdırılmıştır. Veri setindeki yeni gözlem sayısı 68,142’dir. Yani xlsx uzantılı çalışma kitabında 68,142 satır bulunmaktadır. Bu yüzden çalışma kitabını açarken biraz beklemeniz gerekebilir.
sayi<-rpc %>% group_by(word) %>% count() %>% arrange(desc(n))
sayi<-sayi %>% add_column(id=1:NROW(sayi),.before = "word")
sayi
#Frekansı en yüksek ilk 100 kelime
sayi %>% head(100) %>% pander(caption="Frekansı En Yüksek İlk 100 Kelime")
#xlsx uzantılı çalışma kitabına sıklıklarına göre kelimelerin yazdırılması
write_xlsx(sayi, "kelimelerrapor.xlsx")
Yukarıdaki kod bloğunda ikinci alt blok çalıştırıldığında elde edilen frekansı en yüksek ilk 100 kelime aşağıda verilmiştir. Raporda frekansı en yüksek ilk 4 kelime sırasıyla “growth”, “emde”, “bank”, “pandemic” kelimeleridir. emde kelimesi gelişmekte olan ve gelişmiş ekonomilerin kısaltmasıdır.
----------------------------
id word n
----- --------------- ------
1 growth 1108
2 emde 922
3 bank 716
4 pandemic 704
5 global 628
6 world 626
7 percent 578
8 debt 570
9 economies 563
10 policy 523
11 economic 487
12 countries 426
13 covıd 407
14 financial 400
15 asset 381
16 investment 379
17 fiscal 372
18 market 326
19 term 324
20 monetary 281
21 advanced 276
22 long 276
23 output 275
24 expected 270
25 purchase 265
26 central 252
27 washington 231
28 government 225
29 ınternational 225
30 average 222
31 prices 222
32 programs 217
33 capital 216
34 forecasts 212
35 recovery 212
36 income 190
37 productivity 187
38 effects 185
39 economy 181
40 potential 177
41 emerging 173
42 reform 173
43 activity 172
44 support 169
45 january 167
46 some 167
47 prospects 166
48 country 158
49 developing 158
50 asia 156
51 measures 156
52 paper 154
53 risk 154
54 crisis 153
55 development 152
56 forecast 150
57 africa 148
58 purchases 147
59 working 147
60 reforms 146
61 bond 144
62 risks 143
63 labor 141
64 large 141
65 region 137
66 policies 136
67 last 134
68 capita 133
69 increase 133
70 outlook 133
71 public 133
72 markets 130
73 trade 125
74 decade 124
75 fund 120
76 announcements 118
77 crises 116
78 percentage 115
79 projected 113
80 exchange 112
81 here 112
82 inflation 112
83 yields 110
84 note 109
85 economics 108
86 health 108
87 impact 108
88 levels 107
89 south 107
90 lıcs 106
91 cases 105
92 losses 104
93 change 103
94 includes 103
95 sector 102
96 demand 100
97 education 100
98 episodes 100
99 private 100
100 remain 100
----------------------------
Table: Frekansı En Yüksek İlk 100 Kelime
Yukarıdaki kod bloğunda üçüncü alt blok çalıştırıldığında elde edilen kelimeler ve frekansları xlsx uzantılı Microsoft Excel çalışma kitabına yazdırılmış olup aşağıda linkten indirebilirsiniz.
Kelime bulutlarının oluşturulması
Bu kısımda wordcloud2 kütüphanesini kullanarak aşağıdaki kod bloğunda verelim. Burada aynı zamanda oluşturulan kelime bulutu png ve html uzantılı olarak da kaydedilmektedir. Aşağıda yazılan kod bloğunda en yüksek frekansa sahip ilk 350 satırdaki kelimelerin frekansı ele alınmıştır. Dilerseniz wordcloud2 fonksiyonu içerisindeki parametreleri değiştirerek farklı alternatifler deneyebilirsiniz.
sayi<-rpc %>% group_by(word) %>% count() %>% arrange(desc(n))
sayi<-sayi %>% add_column(id=1:NROW(sayi),.before = "word")
#kelime bulutunun oluştuurlması
rp <- wordcloud2(head(sayi[,2:3], 350), size=1, minSize = 10, color = "random-light",backgroundColor = "dark", shape = "circle")
#html ve png olarak kaydedilmesi
saveWidget(rp,"28.html",selfcontained = F)
webshot::webshot("28.html","rp.png",vwidth = 1800, vheight = 1000, delay =10)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde ettiğimiz kelime bulutu aşağıda verilmiştir.

Duygu analizlerinin yapılması
Bu kısımda Loughran dil sözlüğü kullanılarak duygu analizi yapılmıştır. Loughran leksikonunda kelimeler altı duygu kategorisinde ele alınır: “olumsuz”, “pozitif”, “ihtilaflı”, “belirsizlik”, “kısıtlayıcı” veya “gereksiz” (“negative”, “positive”, “litigious”, “uncertainty”, “constraining”, or “superfluous”). Loughran leksikonu bulguları aşağıda yazılan kod bloğu ile elde edilmiştir.
#Loughran leksikon değerlerinin elde edilmesi
l2<-rpc %>% inner_join(get_sentiments("loughran"),by="word")
#Duygu grubuna göre frekanslar
l2 %>% group_by(sentiment) %>% summarise(toplam=n()) %>% mutate(oran=round(toplam/sum(toplam)*100,2)) %>% arrange(desc(oran)) %>% formattable()
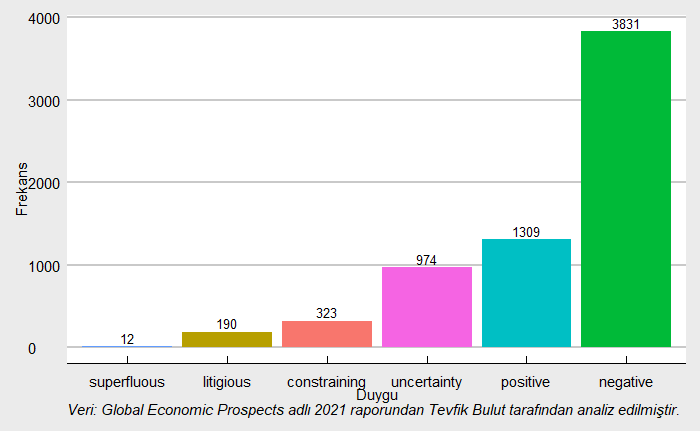
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Loughran leksikonu tanımlayıcı istatistikleri aşağıdaki tabloda verilmiştir. Aşağıda verilen bulgudan şu sonuç çıkarılmalıdır: %57,70 ile negatif duygunun 2021 Küresel Ekonomik Beklentiler (Global Economic Prospects) raporunun genelinde baskın olduğu görülmektedir. Metinde negatif duyguyu pozitif ve belirsizlik duyguları izlemiştir. Aslında duygu analizi bulguları, dünya ekonomisinde yaşanan durumu da ortaya koymaktadır.

Loughran leksikonu sonuçları aşağıda yazılan kod bloğu ile grafik üzerinde de verebiliriz.
l2 %>%
group_by(sentiment) %>% summarise(n=n())%>%
ggplot(aes(reorder(sentiment, n), n, fill=sentiment)) +
geom_bar(stat="identity", show.legend = FALSE)+
geom_text(aes(label=n), vjust=-0.3, size=3.5)+
labs(y = "Frekans", x = "Duygu")+
theme_economist_white()+
labs(caption = "Veri: Global Economic Prospects adlı 2021 raporundan Tevfik Bulut tarafından analiz edilmiştir.")+
theme(plot.caption = element_text(hjust = 0, face = "italic"))
Yukarıdaki kod bloğu çalıştırıldığında Loughran leksikonuna göre 2021 Küresel Ekonomik Beklentiler raporundan elde edilen duygular aşağıdaki grafikte verilmiştir.
Duygu sözlükleri içerisinde duygu kategorisine filtreleme yapmak oldukça kolaydır. Örnek teşkil teşkil etmesi adına Raporda Loughran leksikonuna göre negatif olarak etiketlenen kelimelerden ilk 50’sini aşağıda yazılan kod bloğu ile verelim. Dilersek pozitif olarak etiketlenen kelimelerin tamamı elde edebilir ve xlsx uzantılı çalışma kitaplarına yazdırabiliriz. Benzer işlemleri diğer dil sözlüklerinde de gerçekleştirebiliriz.
l2 %>% filter(sentiment=='negative') %>% head(50) %>% pander(caption="Negatif olarak etiketlenen ilk 50 kelime")
Yukarıdaki kod bloğunun çalıştırılmasından sonra metinde negatif olarak etiketlenen ilk 50 kelime aşağıdaki tabloda verilmiştir.
-----------------------------
word sentiment
----------------- -----------
errors negative
omissions negative
discrepancies negative
failure negative
limitation negative
disclaimer negative
error negative
disclaimer negative
infringe negative
claims negative
infringement negative
critical negative
dangerous negative
disappointments negative
lost negative
persistent negative
deficits negative
challenges negative
challenges negative
challenges negative
disappointments negative
weakness negative
weaknesses negative
downgraded negative
downgraded negative
downgrades negative
crisis negative
downgrades negative
adverse negative
dangerous negative
lost negative
persistent negative
deficits negative
challenges negative
inaction negative
challenges negative
delayed negative
crises negative
damage negative
adverse negative
errors negative
losses negative
setbacks negative
setbacks negative
persistence negative
setbacks negative
setbacks negative
setbacks negative
devastating negative
devastating negative
-----------------------------
Table: Negatif olarak etiketlenen ilk 50 kelime
Şimdide Loughran leksikonunda duygulara göre etiketlenmiş kelimelerin tamamını aşağıda yazılan kod bloğu ile verelim.
l2<-rpc %>% inner_join(get_sentiments("loughran"),by="word")
write_xlsx(l2, "rapor_loughranleksikonu.xlsx")
Yukarıdaki kod bloğunun çalıştırılmasından sonra Loughran leksikonundaki duygu kategorilerine göre etiketlenmiş metindeki bütün kelimeler xlsx uzantılı Microsoft Excel çalışma kitabına yazdırılmış olup aşağıdaki linkten indirebilirsiniz.
Loughran leksikonundaki duygu kategorilerine göre etiketlenmiş 50 kelimeyi olasılıklı örnekleme yöntemlerden biri olan ve önyargı (bias) içermeyen tekrarsız basit tesadüfi örnekleme yöntemi kullanarak seçmek için aşağıdaki gibi basit bir kod satırı yazalım.
set.seed(61)
rpc %>% inner_join(get_sentiments("loughran"),by="word") %>% sample_n(50) %>% pander(caption="Basit Tekrarsız Tesadüfi Örnekleme Yöntemi İle Seçilen Kelimeler ve Duygu Etiketleri")
Loughran leksikonundaki duygu kategorilerine göre etiketlenmiş 50 kelime tekrarsız basit tesadüfi örnekleme yöntemi kullanarak belirlenmiş ve aşağıdaki tabloda verilmiştir.
-----------------------------
word sentiment
-------------- --------------
exposed negative
crisis negative
despite positive
impaired constraining
forbearance litigious
friendly positive
improvement positive
deviation negative
recessions negative
greater positive
whereas litigious
crises negative
gains positive
success positive
risks uncertainty
crisis negative
challenges negative
risks uncertainty
better positive
effective positive
risks uncertainty
easing negative
negative negative
aggravate negative
risks uncertainty
poor negative
require constraining
discourage negative
regulatory litigious
advances positive
damage negative
aggravate negative
stronger positive
crises negative
uncertain uncertainty
crises negative
sudden uncertainty
excessive negative
transparency positive
forbearance litigious
boost positive
regulatory litigious
severe negative
probability uncertainty
gains positive
good positive
difficulties negative
despite positive
advances positive
adverse negative
-----------------------------
Table: Basit Tekrarsız Tesadüfi Örnekleme Yöntemi İle Seçilen Kelimeler ve Duygu Etiketleri
Dünya Bankasının raporu üzerinden sadece Loughran leksikonu kullanarak duygu analizi yapılmıştır. Burada 2. bölümde belirttiğim diğer duygu sözlükleri uygulama adımları kullanılarak diğer leksikonlara göre de duygu analizi yapılabilir.
4. Sentetik veriler üzerinden kelime bulutlarının oluşturulması
Örnek uygulama kapsamında son çalışma sentetik veriler üretilip kelime bulutlarının oluşturulmasıdır. Bu çalışma kapsamında sentetik olarak üretilen kelimelerin büyük bir çoğunluğu İstiklal Marşımızdan alınmıştır. Burada sentetik verilerin üretilmesinde tekrarlı örnekleme tekniği kullanılmış ve 10.000 gözlem üretilmiştir. Bu gözlemler üzerinde kelime bulutları oluşturulmuştur. Şimdi adım adım kelime havuzu oluşturup, ardından tekrarlı örnekleme tekniğini kullanarak 10000 gözlem üretelim. Ardından ise kelime bulutlarını oluşturalım. İlk olarak aşağıda yazılan kod bloğu ile vektör içerisinde kelime havuzumuzu oluşturalım.
#kelime havuzu oluşturma
havuz=c("anadolu", "türkiye", "vatan", "mehmetçik", "istanbul", "ankara", "başkent", "istiklal", "güvenlik","türk", "anıtkabir","fatih", "atatürk","ertuğrul", "diriliş", "lonca","kültür", "asker", "göktürk", "bağımsızlık", "zafer", "ulus","sancak","yurt","siper","hilal","hür", "toprak","millet","hürriyet","izmihlal", "ezan", "şüheda", "inklap","cumhuriyet", "bayrak", "şafak","iman", "medeniyet","ecdat","arş", "hür","hakk", "hüda","secde", "cüdâ", "şafak", "ay","yıldız", "bayrak")
Şimdi aşağıda yazılan kod bloğu ile tibble tablo düzeni içerisinde tekrarlı basit tesadüfi örnekleme yöntemiyle 10000 gözlemden oluşan bir tablo oluşturalım.
#tekrarlı örnekleme tekniği ile kelime tablosu oluşturma
set.seed(1299) # Aynı örneklem birimlerini almanız için sabitlenmiştir.
orneklem= tibble(kelime=sample(havuz, size=10000, replace = TRUE))
Kelime tablomuzu oluşturduğumuza göre aşağıda yazılan kod bloğu ile kelimelerin sıklıklarını (frekanslarını) hesaplayabiliriz.
deneme<-orneklem %>% group_by(kelime) %>% count() %>% arrange(desc(n))
deneme<-deneme %>% add_column(id=1:NROW(sayi),.before = "kelime")
deneme
Kelime sıklık tablosunu oluşturduk. Şimdi sıra aşağıda yazılan kod bloğu ile kelime bulutlarını oluşturmaya gelmiştir. Aşağıda kod bloğunda kelime bulutunu hem png hem html olarak kaydedebilirsiniz. Size bu noktada bir tavsiye vereyim böyle bir durumda yani farklı formatta dosyaları aynı dosyaya kaydetmesi için R çalışma sayfasını çalışmaya başlamadan önce oluşturduğunuz bir klasör içerisinde açınız.
#kelime bulutunun oluşturulması
bulut1<- wordcloud2(head(deneme[,-1],150), size=0.5, color = "random-light", backgroundColor = "grey")
#html ve png olarak kaydedilmesi
saveWidget(bulut1,"bulut1.html",selfcontained = F)
webshot::webshot("bulut1.html","bulut1.png",vwidth = 1800, vheight = 1000, delay =10)
Yukarıdaki kod bloğunun çalıştırılmasından sonra sentetik verilerden ürettiğimiz kelime bulutu daire (circle) düzeninde aşağıda verilmiştir.

Son olarak aşağıda yazılan kod bloğu ile yıldız (star) düzeninde kelime bulutunu oluşturalım. Kelime bulutunda arka fonumuz kutsal bayrağımız rengi olan kırmızı, yıldızımız ise beyaz olsun.
#kelime bulutunun oluşturulması
bulut2<- wordcloud2(deneme[,-1], size=0.4, color = "white", backgroundColor = "red", shape="star", minRotation = -pi/6, maxRotation = -pi/6, rotateRatio = 1)
#html ve png olarak kaydedilmesi
saveWidget(bulut2,"bulut2.html",selfcontained = F)
webshot::webshot("bulut2.html","bulut2.png",vwidth = 1800, vheight = 1000, delay =10)
Yukarıdaki kod bloğunun çalıştırılmasından sonra sentetik verilerden ürettiğimiz kelime bulutu yıldız (star) düzeninde aşağıda verilmiştir.

“4. Sentetik veriler üzerinden kelime bulutlarının oluşturulması” başlığı altındaki bu çalışmayı yüce milletimize her koşulda hizmet eden şehit ve gazi kahraman Mehmetçiklerimize atfediyorum.
Yapılan bu özgün çalışmalar ile özellikle keşifsel veri analizi (exploratory data analysis), metin ve fikir madenciliği (text and opinion mining) alanlarına katkı sunulması amaçlanmıştır.
Veri bilimine gönül vermiş öğrenci, akademisyen ve saha çalışanlarına faydalı olması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Bu çalışmaya atıf yapmak için aşağıdaki örneği kullanabilirsiniz:
- Bulut, T. (2021). R’da Duygu Analizi Üzerine Vaka Çalışmaları: Case Studies on Sentiment Analysis in R. URL: https://tevfikbulut.net/rda-duygu-analizi-uzerine-vaka-calismalari-case-studies-on-sentiment-analysis-in-r/.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
- RStudio Cloud: https://login.rstudio.cloud/
- Microsoft Excel 2016, Microsoft
- The R Project for Statistical Computing. https://www.r-project.org/
- A Turkish Woman’s European Impressions. https://www.gutenberg.org/ebooks/50540
- Saif Mohammad and Peter Turney. “Emotions Evoked by Common Words and Phrases: Using Mechanical Turk to Create an Emotion Lexicon.” In Proceedings of the NAACL-HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, June 2010, LA, California. See: http://saifmohammad.com/WebPages/lexicons.html
- Christopher SG Khoo and Sathik Basha Johnkhan. (2017). Lexicon-based sentiment analysis: Comparative evaluation of six sentiment lexicons. Journal of Information Science, 44(4):491.https://doi.org/10.1177/0165551517703514.
- http://saifmohammad.com/WebPages/meetsaif.htm.
- http://www.saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm.
- https://www.lexalytics.com/technology/sentiment.
- https://sites.nd.edu/emorgan/2014/07/lexicons/.
- NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews, Svetlana Kiritchenko, Xiaodan Zhu, Colin Cherry, and Saif M. Mohammad. In Proceedings of the eighth international workshop on Semantic Evaluation Exercises (SemEval-2014), August 2014, Dublin, Ireland.
- NRC-Canada-2014: Recent Improvements in Sentiment Analysis of Tweets, Xiaodan Zhu, Svetlana Kiritchenko, and Saif M. Mohammad. In Proceedings of the eighth international workshop on Semantic Evaluation Exercises (SemEval-2014), August 2014, Dublin, Ireland.
- Proceeding COLING ’04 Proceedings of the 20th international conference on Computational Linguistics, Determining the sentiment of opinions, Geneva, Switzerland — August 23 – 27, 2004. Article No. 1367
- Marina Sokolova , Guy Lapalme, Verbs speak loud: verb categories in learning polarity and strength of opinions, Proceedings of the Canadian Society for computational studies of intelligence, 21st conference on Advances in artificial intelligence, p.320-331, May 28-30, 2008, Windsor, Canada
- Hu, M., & Liu, B. (2004). Mining opinion features in customer reviews. National Conference on Artificial Intelligence.
- http://hedonometer.org/papers.html Links to papers on hedonometrics.
- https://www.slideshare.net/jeffreybreen/r-by-example-mining-twitter-for.
- Finn Årup Nielsen A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. Proceedings of the ESWC2011 Workshop on ‘Making Sense of Microposts’: Big things come in small packages 718 in CEUR Workshop Proceedings 93-98. 2011 May. http://arxiv.org/abs/1103.2903.
- Minqing Hu and Bing Liu, “Mining and summarizing customer reviews.”, Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD-2004), Seattle, Washington, USA, Aug 22-25, 2004.
- https://www.rdocumentation.org/packages/syuzhet/versions/1.0.6
- Loughran, T. and McDonald, B. (2011), “When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks.” The Journal of Finance, 66: 35-65.
- https://rdrr.io/cran/textdata/man/lexicon_loughran.html
- https://sraf.nd.edu/textual-analysis/resources/
- Andriy Bodnaruk, Tim Loughran and Bill McDonald, 2015, Using 10-K Text to Gauge Financial Constraints, Journal of Financial and Quantitative Analysis, 50:4, 1-24. (Available at SSRN:http://ssrn.com/abstract=2331544.)
- Tim Loughran and Bill McDonald, 2016, Textual Analysis in Accounting and Finance: A Survey, Journal of Accounting Research, 54:4,1187-1230. (Available at SSRN: http://ssrn.com/abstract=2504147.)
- https://tevfikbulut.com/2021/01/30/metin-madenciligi-uzerine-vaka-calismalari-case-studies-on-text-mining/
- https://tevfikbulut.com/2020/10/08/rda-kelime-bulutu-uygulamasi-gelistirilmesi-uzerine-bir-vaka-calismasi-a-case-study-on-developing-a-word-cloud-application-in-r/
- Kelime Bulutu Uygulaması. https://buluttevfik.shinyapps.io/kelimebulutv3/
- https://tevfikbulut.com/2018/08/04/veri-madenciligi-data-mining-web-uzerinde-kelime-bulutu-word-cloudna-iliskin-ornek-bir-uygulama/
- https://tevfikbulut.com/2018/08/07/veri-madenciligi-duygu-analizi-sentiment-analysis-uzerine-bir-vaka-calismasi/
- https://tevfikbulut.com/2018/08/08/nitel-arastirmalarda-duygu-analizi-sentiment-analysis-uzerine-bir-vaka-calismasi-ii/
- World Bank. 2021. Global Economic Prospects, January 2021. Washington, DC: World Bank. DOI: 10.1596/978-1-4648-1612-3. License: Creative Commons Attribution CC BY 3.0 IGO.
- https://www.sanayigazetesi.com.tr/kuresel-ekonomik-beklentiler-2021-ocak-donemi-raporu-makale,1971.html