Lojistik regresyon analizi yöntemlerinden biri olan ordinal (sıralı) regresyon analiz yöntemi, bağımlı değişkenin ya da cevap değişkeninin
ordinal (sıralı) kategorik olduğu durumlarda bağımlı değişkenler (dependent variables) ile bağımsız değişken veya değişkenler (independent variables) arasındaki ilişkiyi ortaya koyan regresyon analiz yöntemidir. Burada bağımlı değişkenin ordinal olmasından kasıt kategorik değişkenin bir sıra veya derece belirtmesi anlaşılmalıdır. Ordinal değişken tipi ile nominal değişken tipi karıştılmamalıdır. Ordinal veriler sıra belirtirken nominal verilerde bu tür sıra düzeni bulunmamaktadır. Veri tipleri kendi içerisinde 4 farklı alt sınıfta ele alınabilir. Bu veri tipleri Şekil 1’de verilmiştir.
Şekil 1: Veri Tipleri
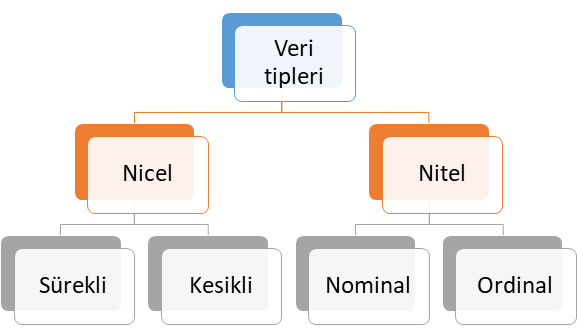
Nicel Veri (Quantitative Data)
Şekil 1’de verilen sunulan nicel veri tipi ölçülebilen veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek verelim.
- Sürekli veri:Tam sayı ile ifade edilmeyen veri tipi olup, zaman, sıcaklık, beden kitle endeksi, boy ve ağırlık ölçümleri bu veri tipine örnek verilebilir.
- Kesikli veri: Tam sayı ile ifade edilebilen veri tipi olup, bu veri tipine proje sayısı, popülasyon sayısı, öğrenci sayısı örnek verilebilir.
Nitel Veri (Qualitative Data)
Şekil 1’de verilen sunulan nitel veri tipi ölçülemeyen ve kategori belirten veri tipi olup, kendi içerisinde temel olarak ikiye ayrılmaktadır. Bu veri tipine alt sınıflandırmalar dikkate alınarak sırasıyla örnek vererek ele alalım.
- Nominal veri: İki veya daha fazla cevap kategorisi olan ve sıra düzen içermeyen veri tipi olup, bu veri tipine medeni durum (evli, bekar) ve sosyal güvenlik türü (Bağkur, SSK, Yeşil Kart, Özel Sigorta) örnek gösterilebilir.
- Ordinal veri: İki veya daha fazla kategorisi olan ancak sıra düzen belirten veri türüdür. Bu veri tipine örnek olarak eğitim düzeyleri (İlkokul, ortaokul, lise, üniversite ve yüksek lisans), yarışma dereceleri (1. , 2. ve 3.) ve illerin gelişmişlik düzeyleri (1. Bölge, 2. Bölge, 3. Bölge, 4. Bölge, 5. Bölge ve 6. Bölge) verilebilir.
Veri tiplerinden bahsedildikten sonra bu veri tiplerinin cevap değişkeni (bağımlı değişken) olduğu durumlarda seçilecek regresyon analiz yöntemini ele alalım. Temel olarak cevap değişkeni ölçülebilir numerik değişken ise regresyon, değilse sınıflandırma analizi yapıyoruz. Eğer cevap değişkeni nitel ise aslında sınıflandırma problemini çözmek için analizi kullanıyoruz. Cevap değişkeni, diğer bir deyişle bağımlı değişken numerik ise bağımsız değişken veya değişkenlerin çıktı (output) / bağımlı değişken (dependent variable) / hedef değişken (target variable) veya değişkenlerin üzerindeki etkisi tahmin etmeye çalışıyoruz. Buradaki temel felsefeyi anlamak son derece önemlidir. Çünkü bu durum sizin belirleyeceğiniz analiz yöntemi de değiştirecektir. Bağımlı değişkenin tipine göre kullanılan regresyon analiz yöntemleri Şekil 2’de genel hatlarıyla verilmiştir.
Şekil 2: Cevap Değişkeninin Veri Tipine Göre Regresyon Analiz Yöntemleri

Bu kapsamda cevap değişkeni (bağımlı değişken) üzerinden uygulamalı olarak ordinal lojistik regresyon analizi yapılacaktır. Analizde R programlama dili kullanarak analiz adımları R kod bloklarında verilmiştir.
Veri seti Oklahoma Üniversitesinden Mike Crowson’ın kişisel web sitesinden indirilmiştir. Analizde kullanılan veri setini aşağıdaki linkten indirebilirsiniz.
Veri setindeki değişkenlerle öğrenci ilgisinin tahmincileri bulunmaya çalışılmıştır. Ancak bu veri seti senaryo niteliği taşımaktadır. 200 öğrencinin cevaplarından oluşmaktadır. Veri setinde değişkenler şöyledir:
- pass: öğrencinin konu testini geçip geçmediğini göstermektedir. Cevap kategorileri iki cevap seçeneğinden oluşmakta olup, öğrenci başarılı ise 1, başarısız ise 0 olarak kodlanmıştır.
- masteryg: Değişken sürekli veri tipine sahip olup, öğrencinin yüksek puanlar alması master hedeflerine daha yakın olduğunu göstermektedir.
- fearfail: Değişken sürekli veri tipine sahip olup, öğrencinin kaybetme korkusunu göstermektedir. Öğrencinin yüksek puanlar alması kaybetme korkusunu daha da artırmaktadır.
- genderid: cinsiyet değişkeni olup dikotomik nominal veri tipine sahiptir. Erkek 0, kadın 1 olarak kodlanmıştır.
- interestlev: cevap değişkeni (bağımlı değişken) olan bu değişken ordinal veri tipindedir. interestlev öğrencilerin derse ilgi düzeylerini göstermektedir. Cevap kategorilerinde 1 = düşük ilgi, 2 = orta ilgi, 3 = yüksek ilgi düzeyi olarak kodlanmıştır.
Yüklenecek R kütüphaneleri
gereklipaketler=c("dplyr","tibble","tidyr","ggplot2","readr","readxl","xlsx","officer","aod", "DescTools", "reshape2","MASS", "effects","caret","stargazer", "car")
sapply(gereklipaketler, require, character.only = TRUE)
Ver setinin okunması
Bu kısımda ilk olarak spss uzantılı (vav) veri seti okunmuştur. Ardından cevap değişkeni olan “interestlev” değişkeni ordinal veri türüne dönüştürülmüştür. Veri setinde nitel olması gereken bağımsız değişkenler nominal veri türüne dönüştürülmüştür.
df<- read_csv("olrexample.csv") %>% as_tibble()
df<-df[, 1:5] %>% mutate(pass=as.factor(pass),masteryg=as.numeric(masteryg), fearfail=as.numeric(fearfail), genderid=as.factor(genderid),interestlev=as.ordered(interestlev))
df
Veri setinin yapısı
Aşağıdaki kod bloğu ile veri setinin yapısı gözden geçirilmiştir.
str (df)#alternatif
glimpse(df)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen veri setinin yapısına ilişkin istatistikler aşağıda verilmiştir. Görüleceği üzere veri 200 gözlem ve 5 değişkenden oluşmaktadır. Modelde bağımlı değişken olarak yer alan değişken “interestlev” olup, kalan değişkenler bağımsız (predictor) değişkenlerdir.
Observations: 200
Variables: 5
$ pass <fct> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
$ masteryg <dbl> 79.23879, 91.04159, 113.28733, 67.03985, 90.32525, 8...
$ fearfail <dbl> 105.00000, 85.76007, 94.69049, 82.00000, 100.01866, ...
$ genderid <fct> 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0...
$ interestlev <ord> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
Kategorik değişkenlerin sıklıkları (n)
freq<-df %>% as_tibble() %>% group_by(genderid, pass, interestlev) %>%
summarise(n = n()) %>% spread(key = interestlev, value = n)
formattable(freq)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra kategorik değişkenlere ait elde edilen sıklıklar aşağıdaki tabloda verilmiştir. Tablodaki son 3 sütun ilgi düzeyi (interestlev) düzeyi kategorilerini göstermektedir.
| genderid | pass | 1 | 2 | 3 |
| 0 | 0 | 25 | 31 | 16 |
| 0 | 1 | 8 | 14 | 19 |
| 1 | 0 | 11 | 9 | 10 |
| 1 | 1 | 7 | 19 | 31 |
Veri setinin görselleştirilmesi
Şimdi de veri setindeki değişkenlerin tamamını kategorik veri etiketleriyle birlikte aşağıdaki kod bloğuyla grafiğe yansıtalım.
#veri setindeki kategorik değişkenlerin cevap seçeneklerine etiket ataması yapılması
df1<-df %>% mutate(genderid= ifelse(genderid == 0, "Male", "Female"), pass= ifelse(pass == 0, "Failed", "Passed"),interestlev=ifelse(interestlev==1,"Low", ifelse(interestlev==2,"Medium","High")))
df1
#veri setinin görselleştirlmesi
df1 %>% ggplot(aes(x = fearfail, y = masteryg, color = interestlev))+
geom_point(position = position_dodge(0.9)) +
facet_grid(genderid + pass ~ interestlev)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen grafik aşağıda verilmiştir.

Değişkenler arasındaki korelasyonun hesaplanması
Bu kısımda veri setindeki değişkenler arasındaki ilişkiler (korelasyon) ortaya konulmuştur. Ardından çizilen Q-Q grafikleriyle verinin normal dağılıma uyup uymadığı kontrol edilmiştir.
chisq.test(df$pass, df$interestlev)#iki kategorik değişken arasındaki ilişki
chisq.test(df$pass, df$genderid)#iki kategorik değişken arasındaki ilişki
chisq.test(df$interestlev, df$genderid)#iki kategorik değişken arasındaki ilişki
SpearmanRho(df$masteryg, df$interestlev)#çıktı değişkeni ordinal kategorik olduğu için
SpearmanRho(df$fearfail, df$interestlev)#çıktı değişkeni ordinal kategorik olduğu için
#sürekli değişken için pearson korelasyon katsayısı hesaplanması
cor.test(df$masteryg, df$fearfail, method="pearson")
#ilişkinin grafik üzerinde gösterimi
ggscatter(df, x = "masteryg", y = "fearfail",
add = "reg.line", conf.int = TRUE,
cor.coef = TRUE, cor.method = "pearson",
xlab = "masteryg", ylab = "fearfail")
#Q-Q plot ile verinin normal dağılıma uyumu incelenmiştir.
#verinin normal dağılıma uyup uymadığının sürekli veri değişkenler üzerinden gösterilmesi
m<-ggqqplot(df$masteryg, ylab = "masteryg")
f<-ggqqplot(df$fearfail, ylab = "fearfail")
ggarrange(m, f)
Ortaya konulan korelasyon test sonuçları aşağıda verilmiş olup, katsayılar oldukça düşüktür. Bu durum model için istenen bir durumdur.
Pearson's Chi-squared test
data: df$pass and df$interestlev
X-squared = 16.824, df = 2, p-value = 0.0002222
Pearson's Chi-squared test with Yates' continuity correction
data: df$pass and df$genderid
X-squared = 15.661, df = 1, p-value = 7.577e-05
Pearson's Chi-squared test
data: df$interestlev and df$genderid
X-squared = 5.5583, df = 2, p-value = 0.06209
[1] 0.2433652
[1] -0.2154034
Pearson's product-moment correlation
data: df$masteryg and df$fearfail
t = -2.4893, df = 198, p-value = 0.01362
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.30555780 -0.03633905
sample estimates:
cor
-0.1742018
Sürekli değişkenler arasındaki korelasyonun grafiği ise aşağıda verilmiştir.
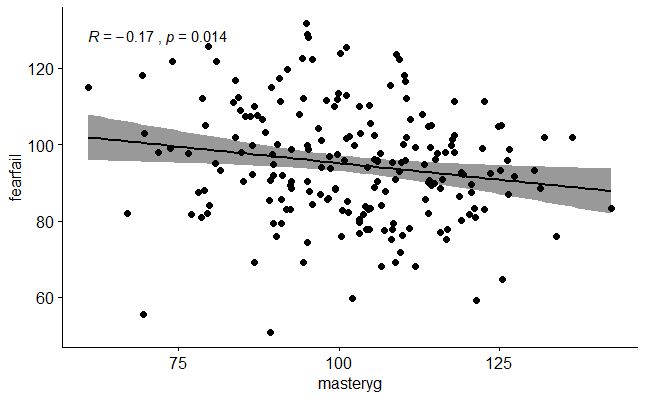
Sürekli değişkenlerin normal dağılıma uyup uymadığını ortaya koymak için çizilen Q-Q grafikleri ise karşılaştırma sağlanabilmesi adına değişkene göre yanyana verilmiştir.

Ordinal lojistik regresyon (OLR) modelinin oluşturulması
model <- polr(interestlev ~., data = df, Hess=TRUE)#çarpı işareti fonksiyon içerisinde varsa etkileşimleri göstermektedir.
summary(model)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde ordinal lojistik regresyon model çıktısına aşağıda yer verilmiştir.
Call:
polr(formula = interestlev ~ ., data = df, Hess = TRUE)
Coefficients:
Value Std. Error t value
pass1 0.81999 0.298159 2.750
masteryg 0.02627 0.009369 2.804
fearfail -0.01523 0.009708 -1.569
genderid1 0.23225 0.287085 0.809
Intercepts:
Value Std. Error t value
1|2 0.5216 1.4353 0.3634
2|3 2.2852 1.4439 1.5826
Residual Deviance: 403.3534
AIC: 415.3534
Elde edilen sonuçlara göre ordinal lojistik regresyon modeli şöyle yazılabilir.
logit(P(Y≤1))=0.52-0,82∗pass1-(0.03)∗ masteryg -(-0.02)∗ fearfail-(0,23)∗ genderid1
logit(P(Y≤2))=2,29-0,82∗pass1-(0.03)∗ masteryg -(-0.02)∗ fearfail-(0,23)∗ genderid1
Yukarıdaki sonuçlar aşağıdaki R kod bloğu ile raporlanmak istenirse katsayılar ve standart hatanın olduğu bir tablo edilmesi de mümkündür.
stargazer(model, type="text", out="models.txt")
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen model özet tablosu aşağıda verilmiştir.
========================================
Dependent variable:
---------------------------
interestlev
----------------------------------------
pass1 0.820***
(0.298)
masteryg 0.026***
(0.009)
fearfail -0.015
(0.010)
genderid1 0.232
(0.287)
----------------------------------------
Observations 200
========================================
Note: *p<0.1; **p<0.05; ***p<0.01
Modelin güven aralığı
Modeldeki bağımsız değişkenlerin olasılık katsayılarının güven aralığı alt ve üst limit değerlerinin hesaplanması ve bu güven aralığının grafikle çizilmesine yönelik yazılan kod bloğu aşağıdadır.
modelpr<- profile(model)
confint(modelpr)
plot(modelpr)
pairs(modelpr)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen modeldeki bağımsız değişkenlerin olasılık katsayıları (-2 Log Likehood) (-2LL)) güven düzeyleri ile birlikte aşağıda verilmiştir.
2.5 % 97.5 %
pass1 0.238680184 1.409736409
masteryg 0.008100699 0.044916876
fearfail -0.034434531 0.003705836
genderid1 -0.331557153 0.795942445
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen modeldeki bağımsız değişkenlerin olasılık katsayıları güven aralığı ile birlikte aşağıdaki şekilde verilmiştir.

Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen modeldeki bağımsız değişkenlerin olasılık katsayıları güven aralığı ile birlikte alternatif olarak aşağıdaki şekilde verilmiştir.

Tahmin edilen olasılık değerleri
model$fitted.values
#yada
model$probs
#yada
predict(model, df, type = "p")
Yukarıdaki kod bloğu çalıştırılmasından sonra elde edilen bağımlı değişken kategorilerine ait olasılık değerleri aşağıda verilmiştir.
1 2 3
1 0.50972229 0.3487315 0.14154618
2 0.31079693 0.4137674 0.27543564
3 0.22360103 0.4032683 0.37313062
4 0.44444877 0.3790867 0.17646452
5 0.41867790 0.3890649 0.19225719
6 0.50465968 0.3513150 0.14402527
7 0.35731264 0.4070171 0.23567028
8 0.19341534 0.3897166 0.41686803
9 0.27683277 0.4138655 0.30930171
10 0.48207029 0.3623987 0.15553097
11 0.43612937 0.3824463 0.18142437
12 0.27267736 0.4135482 0.31377446
13 0.48970620 0.3587356 0.15155820
14 0.44724076 0.3779310 0.17482827
15 0.26022956 0.4121213 0.32764913
16 0.35651741 0.4071877 0.23629494
17 0.50521330 0.3510342 0.14375246
18 0.34266510 0.4098689 0.24746604
19 0.47369771 0.3663128 0.15998947
20 0.47287768 0.3666903 0.16043205
21 0.39896596 0.3957903 0.20524372
22 0.58528083 0.3064074 0.10831174
23 0.50553599 0.3508704 0.14359363
24 0.23294279 0.4062458 0.36081138
25 0.35192189 0.4081385 0.23993958
26 0.44384967 0.3793329 0.17681746
27 0.49338423 0.3569402 0.14967553
28 0.31600903 0.4133630 0.27062797
29 0.62133002 0.2840778 0.09459223
30 0.50866005 0.3492765 0.14206344
31 0.15239343 0.3595198 0.48808682
32 0.49620528 0.3555498 0.14824487
33 0.44161394 0.3802458 0.17814030
34 0.21754850 0.4010497 0.38140177
35 0.19885748 0.3926407 0.40850180
36 0.36751008 0.4046765 0.22781342
37 0.14239406 0.3496232 0.50798273
38 0.16119885 0.3673396 0.47146160
39 0.17769277 0.3799386 0.44236859
40 0.11592388 0.3174751 0.56660101
41 0.13762508 0.3444965 0.51787841
42 0.13407445 0.3404998 0.52542578
43 0.28969928 0.4143734 0.29592730
44 0.24278818 0.4088299 0.34838194
45 0.11817038 0.3205742 0.56125540
46 0.15089677 0.3581093 0.49099397
47 0.08007606 0.2566985 0.66322546
48 0.20279576 0.3946182 0.40258609
49 0.12691553 0.3319532 0.54113128
50 0.15081222 0.3580288 0.49115894
51 0.10901680 0.3074704 0.58351283
52 0.44286158 0.3797375 0.17740097
53 0.27610273 0.4138153 0.31008193
54 0.27197607 0.4134870 0.31453697
55 0.34910085 0.4086924 0.24220674
56 0.35726375 0.4070276 0.23570863
57 0.29756926 0.4143478 0.28808294
58 0.60627061 0.2935538 0.10017556
59 0.15347118 0.3605205 0.48600832
60 0.27388158 0.4136481 0.31247032
61 0.50059145 0.3533654 0.14604314
62 0.23394931 0.4065355 0.35951520
63 0.47812287 0.3642577 0.15761944
64 0.38774826 0.3992332 0.21301852
65 0.34520858 0.4094186 0.24537285
66 0.38319173 0.4005473 0.21626100
67 0.22199855 0.4027037 0.37529779
68 0.39346020 0.3975164 0.20902337
69 0.37963491 0.4015380 0.21882709
70 0.45830055 0.3732178 0.16848163
71 0.60830302 0.2922870 0.09941000
72 0.42412252 0.3870643 0.18881319
73 0.46686921 0.3694230 0.16370777
74 0.44474393 0.3789652 0.17629088
75 0.17092354 0.3750752 0.45400125
76 0.35091902 0.4083381 0.24074291
77 0.17549425 0.3784043 0.44610150
78 0.23617420 0.4071549 0.35667094
79 0.26562913 0.4128300 0.32154084
80 0.35346811 0.4078253 0.23870662
81 0.21737225 0.4009816 0.38164615
82 0.30874803 0.4138998 0.27735218
83 0.43710905 0.3820573 0.18083366
84 0.36293521 0.4057613 0.23130345
85 0.29791149 0.4143411 0.28774737
86 0.42650258 0.3861711 0.18732628
87 0.52488044 0.3407910 0.13432855
88 0.34567056 0.4093347 0.24499473
89 0.46678588 0.3694605 0.16375361
90 0.27627616 0.4138275 0.30989636
91 0.20937450 0.3976717 0.39295378
92 0.19067206 0.3881558 0.42117212
93 0.16481591 0.3703235 0.46486058
94 0.22940193 0.4051793 0.36541873
95 0.23400555 0.4065515 0.35944295
96 0.13738008 0.3442257 0.51839420
97 0.08196176 0.2604931 0.65754513
98 0.09852379 0.2908078 0.61066843
99 0.11187433 0.3116983 0.57642735
100 0.18054652 0.3818672 0.43758632
101 0.26213323 0.4123872 0.32547954
102 0.10066200 0.2943535 0.60498448
103 0.08551857 0.2674511 0.64703029
104 0.12601898 0.3308353 0.54314576
105 0.11696879 0.3189258 0.56410540
106 0.13767072 0.3445469 0.51778240
107 0.12338391 0.3274862 0.54912987
108 0.12693904 0.3319824 0.54107861
109 0.15966628 0.3660359 0.47429778
110 0.27073769 0.4133734 0.31588891
111 0.16137752 0.3674900 0.47113249
112 0.14365971 0.3509386 0.50540170
113 0.18043963 0.3817962 0.43776418
114 0.09740092 0.2889138 0.61368532
115 0.32613454 0.4123086 0.26155688
116 0.18376245 0.3839567 0.43228087
117 0.12050627 0.3237189 0.55577488
118 0.15183564 0.3589969 0.48916746
119 0.18499825 0.3847365 0.43026529
120 0.11788356 0.3201827 0.56193377
121 0.15305816 0.3601385 0.48680338
122 0.11160775 0.3113093 0.57708297
123 0.19449331 0.3903138 0.41519284
124 0.19928034 0.3928585 0.40786112
125 0.30846876 0.4139167 0.27761459
126 0.37900678 0.4017097 0.21928349
127 0.29425401 0.4143886 0.29135737
128 0.26306333 0.4125108 0.32442591
129 0.47722674 0.3646763 0.15809691
130 0.16566452 0.3710050 0.46333046
131 0.31229799 0.4136609 0.27404116
132 0.46223170 0.3714920 0.16627629
133 0.25965835 0.4120381 0.32830357
134 0.31411673 0.4135210 0.27236232
135 0.39921239 0.3957115 0.20507615
136 0.37496982 0.4027899 0.22224030
137 0.28576046 0.4142921 0.29994741
138 0.20148857 0.3939745 0.40453697
139 0.48191790 0.3624710 0.15561115
140 0.14339543 0.3506655 0.50593911
141 0.20516239 0.3957521 0.39908554
142 0.25426127 0.4111715 0.33456721
143 0.31313222 0.4135981 0.27326964
144 0.24662451 0.4096906 0.34368484
145 0.26850206 0.4131506 0.31834738
146 0.16447957 0.3700515 0.46546896
147 0.34403763 0.4096283 0.24633410
148 0.21955507 0.4018113 0.37863366
149 0.28174457 0.4141425 0.30411290
150 0.20099398 0.3937277 0.40527837
151 0.15719034 0.3638794 0.47893022
152 0.12937876 0.3349693 0.53565190
153 0.09789945 0.2897574 0.61234315
154 0.22238914 0.4028428 0.37476807
155 0.17869453 0.3806237 0.44068179
156 0.11498780 0.3161617 0.56885045
157 0.23672559 0.4073039 0.35597047
158 0.17865025 0.3805936 0.44075617
159 0.10253426 0.2973937 0.60007202
160 0.20620300 0.3962379 0.39755905
161 0.22944019 0.4051913 0.36536854
162 0.31156579 0.4137138 0.27472036
163 0.13501115 0.3415694 0.52341947
164 0.08807997 0.2723048 0.63961520
165 0.07001252 0.2351392 0.69484825
166 0.10231382 0.2970389 0.60064732
167 0.13066169 0.3365086 0.53282971
168 0.19804379 0.3922178 0.40973839
169 0.12369218 0.3278829 0.54842487
170 0.08880130 0.2736485 0.63755018
171 0.08322150 0.2629870 0.65379152
172 0.08988979 0.2756572 0.63445305
173 0.18103205 0.3821883 0.43677970
174 0.07925023 0.2550131 0.66573668
175 0.12174327 0.3253526 0.55290415
176 0.23581135 0.4070558 0.35713285
177 0.20721872 0.3967048 0.39607647
178 0.10130741 0.2954083 0.60328431
179 0.11893678 0.3216146 0.55944859
180 0.22252111 0.4028896 0.37458931
181 0.05880540 0.2083108 0.73288382
182 0.14895077 0.3562387 0.49481052
183 0.08433011 0.2651548 0.65051511
184 0.12627166 0.3311514 0.54257692
185 0.10421519 0.3000729 0.59571193
186 0.18287247 0.3833872 0.43374035
187 0.14144146 0.3486208 0.50993773
188 0.20252758 0.3944871 0.40298530
189 0.13932607 0.3463564 0.51431757
190 0.09545153 0.2855724 0.61897608
191 0.10741266 0.3050405 0.58754688
192 0.15219050 0.3593299 0.48847958
193 0.09469177 0.2842516 0.62105666
194 0.09152896 0.2786394 0.62983167
195 0.09584531 0.2862528 0.61790186
196 0.16977420 0.3742079 0.45601787
197 0.09490074 0.2846159 0.62048335
198 0.15432166 0.3613015 0.48437687
199 0.17850027 0.3804915 0.44100821
200 0.05269823 0.1923085 0.75499327
Model etki testi (Parametre Tahminleri)
Anova testi yardımıyla kurulan modelin etkisi test edilmiştir.
Anova(model)
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen Anova test sonuçları aşağıda verilmiştir.
Analysis of Deviance Table (Type II tests)
Response: interestlev
LR Chisq Df Pr(>Chisq)
pass 7.6594 1 0.005648 **
masteryg 8.0711 1 0.004498 **
fearfail 2.4831 1 0.115074
genderid 0.6540 1 0.418690
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Üstel Beta (Exponential Beta: Odds Ratio (OR)) Katsayıları
Ordinal lojistik regresyonun yorumlanmasında önemli bir yere sahip üstel Beta katsayı aşağıdaki kod bloğunda hesaplanmıştır.
ci <- confint(model) # default method gives profiled CIs
## OR and CI (Üstel Beta ve Güven Düzeyleri)
exp(cbind(OR = coef(model), ci))
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen üstel Beta katsayıları güven düzeyleri ile birlikte aşağıda verilmiştir. Yukarıdaki parametre tahmini ve aşağıdaki bulgular değerlendirildiğinde öne çıkan bulgular şöyledir:
- Öğrencilerin cinsiyetinin ve kaybetme korkusunun ilgi düzeyi üzerinde istatistiksel olarak anlamlı bir etkisi bulunmamaktadır (öğrenci cinsiyeti için p=0,418>0,05 ve kaybetme korkusu için p=0,115>0,05)
- Öğrencilerin dersten geçme durumu (pass)’nun ilgi düzeyi üzerinde istatistiksel olarak anlamlı bir etkisi bulunmaktadır (p=0,005<0,05). Kaybetme korkusunda bir birimlik artış öğrencilerin ilgi düzeyini 2,27 (OR) kat artırmaktadır.
- Öğrencilerin aldıkları puanlar (masteryg) durumunun ilgi düzeyi üzerinde istatistiksel olarak anlamlı bir etkisi bulunmaktadır (p=0,004<0,05). Puanlardaki bir birimlik artış öğrencilerin ilgi düzeyini 1,02 (OR) kat artırmaktadır.
OR 2.5 % 97.5 %
pass1 2.2704747 1.2695733 4.094901
masteryg 1.0266182 1.0081337 1.045941
fearfail 0.9848875 0.9661514 1.003713
genderid1 1.2614323 0.7178024 2.216537
Gerçekleşen ve tahmin edilen bağımlı değişken değerleri
Bu çalışma tahmin edilen bağımlı değişken olan ilgi seviyesi (interestlev) kategorileri ile gerçekleşen (veri setindeki) ilgi seviyesi (interestlev) kategorilerinin elde edilmesine yönelik yazılan R kod bloğu aşağıdadır.
tahmin<-as.ordered(predict(model))#kurulan modelden elde edilen tahminler
gercek<-as.ordered(df$interestlev)#veri setindeki gözlemler
karsilastirma<-tibble(Gercek=gercek, Tahmin=tahmin)
ilk10<-head(karsilastirma, 10) %>% rename(Gercekİlk_10=Gercek, Tahminİlk_10=Tahmin)
son10<-tail(karsilatirma, 10) %>% rename(GercekSon_10=Gercek, TahminSon_10=Tahmin)
formattable(cbind(Id=seq(1,10),ilk10, son10)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen tahmin edilen ve gerçekleşen bağımlı değişkenin ilk ve son 10 kaydı aşağıdaki tabloda yan yana verilmiştir. Bu kısımdan sonra tahmin edilen bağımlı değişken kategorileri ile veri setindeki bağımlı değişken kategorileri hata matriksi (confusion matrix) ile karşılaştırılarak kurulan modelin hata oranı ortaya konulacaktır.

Hata Matriksi (Confusion Matrix) değerleri
Karışıklık matrisi olarak olarak da adlandırılan hata matrisi sınıflandırma problemlerinin çözümünde hata metriklerini ortaya koyarak kurulan modelin veya modellerin hata oranını değerlendirmektedir.Hata matrisinin makine ve derin öğrenme metodlarının değerlendirilmesinde sıklıkla kullanıldığı görülmektedir. Aşağıda yer alan tabloda hata metriklerinin hesaplanmasına esas teşkil eden tablo verilmiştir. Bu tabloyla sınıflandırma hataları hesaplanabilmektedir. Tabloda yer verilen Tip 1 hata (Type 1 error) istatistikte alfa hatasını göstermektedir. Tip 1 hata H0 hipotezi (null hpypothesis) doğru olduğu halde reddedilmesidir. Tabloda Tip 2 hata (Type II error) olarak adlandırılan hata ise istatistikte Beta hatası olarak da bilinmektedir. Tip 2 hata ise H0 hipotezi (null hpypothesis) yanlış olduğu halde kabul edilmesidir.

Sınıflandırma modellerinin performansını değerlendirmede aşağıdaki metriklerden yaygın bir şekilde yararlanılmaktadır.
- Doğruluk (Accuracy): TP+TN / TP+TN+FP+FN eşitliği ile hesaplanır. Modelin genel performansını ortaya koyar.
- Kesinlik (Precision): TP / TP+FP eşitliği ile hesaplanır. Doğru tahminlerin ne kadar kesin olduğunu gösterir.
- Geri çağırma (Recall): TP / TP+FN eşitliği ile hesaplanır. Gerçek pozitif örneklerin oranını verir.
- Özgünlük (Specificity): TN / TN+FP eşitliği ile hesaplanır. Gerçek negatif örneklerin oranını gösterir.
- F1 skoru : 2TP / 2TP+FP+FN eşitliği ile hesaplanır. Dengesiz sınıflar için yararlı hibrit metrik olup, kesinlik (precision) ve geri çağırma (recall) skorlarının ağırlıklı ortalamasını ifade etmektedir.
Ordinal lojistik regresyon metodu sınıflandırma problemlerinin çözümünde kullanıldığı için modelin doğruluğunu ölçümlemek için confusion matris hesaplanmış olup kod bloğu aşağıda verilmiştir.
tahmin<-as.ordered(predict(model))
gercek<-as.ordered(df$interestlev)
cm<-confusionMatrix(tahmin, gercek)
cm
Yukarıdaki kod bloğunun çalıştıırlmasından sonra elde edilen confusion matris çıktılarına aşağıda yer verilmiştir. Modelin bağımlı değişken olan interlev değişkenini doğru tahmin (accuracy) yüzdesi % 49 olup, oldukça düşüktür.
Confusion Matrix and Statistics
Reference
Prediction 1 2 3
1 20 13 4
2 15 29 23
3 16 31 49
Overall Statistics
Accuracy : 0.49
95% CI : (0.4188, 0.5615)
No Information Rate : 0.38
P-Value [Acc > NIR] : 0.0009889
Kappa : 0.2131
Mcnemar's Test P-Value : 0.0362707
Statistics by Class:
Class: 1 Class: 2 Class: 3
Sensitivity 0.3922 0.3973 0.6447
Specificity 0.8859 0.7008 0.6210
Pos Pred Value 0.5405 0.4328 0.5104
Neg Pred Value 0.8098 0.6692 0.7404
Prevalence 0.2550 0.3650 0.3800
Detection Rate 0.1000 0.1450 0.2450
Detection Prevalence 0.1850 0.3350 0.4800
Balanced Accuracy 0.6390 0.5490 0.6329
Bağımlı değişkenin kategorilerine göre sadece hata parametrelerini verecek olursak aşağıdaki kodu yazmamız yeterli olacaktır.
#Kategori bazında hata parametrelerini görme
class<-cm$byClass#sınıfa göre hata oranları
class<-class %>% as_tibble(class) %>% add_column(Class = 1:3, .before = "Sensitivity")
class1<-class[, c(1, 2,3,6, 7, 8)]
pivot<-class1 %>% pivot_longer(-Class, names_to = "Parameters", values_to = "Value")
library(writexl)#sonuçları excele yazdırma
write.xlsx(pivot, "pivot.xlsx")
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen bağımlı değişkenin kategorilere göre hata parametreleri aşağıdaki tabloda verilmiştir.
| Sınıf | Parametreler | Değer |
| 1 | Sensitivity | 0,3922 |
| 1 | Specificity | 0,8859 |
| 1 | Precision | 0,5405 |
| 1 | Recall | 0,3922 |
| 1 | F1 | 0,4545 |
| 2 | Sensitivity | 0,3973 |
| 2 | Specificity | 0,7008 |
| 2 | Precision | 0,4328 |
| 2 | Recall | 0,3973 |
| 2 | F1 | 0,4143 |
| 3 | Sensitivity | 0,6447 |
| 3 | Specificity | 0,6210 |
| 3 | Precision | 0,5104 |
| 3 | Recall | 0,6447 |
| 3 | F1 | 0,5698 |
Yukarıdaki tabloda yer alan hata parametreleri bağımlı değişkenin kategorilerine göre grafikte verilmiş olup, kod bloğu aşağıdadır.
ggplot(pivot, aes(x="", y=Value, group=Class))+
geom_point(aes(fill=Class))+facet_grid(Class~ Parameters, scales="free", space="free")
Yukarıdaki kod bloğunun çalıştırılmasından sonra elde edilen grafik aşağıda verilmiştir. Kurulan modelin bağımlı değişkeni tahmin etme derecesinin değerlendirilmesinde F1 skoru üzerinden gidilecek olursa en iyi tahmin edilen bağımlı değişken (interestlev=çok yüksek (3)) kategorisinin 3 olarak kodlanan “çok yüksek” ilgi düzeyi olduğu görülmektedir. Burada F1 skoru kesinlik (precision) ve geri çağırma (Recall) skorlarının ağırlıklı ortalamasını ifade etmektedir.

Bağımsız değişkenlerin cevap değişkeni üzerindeki etkisi
Bağımsız değişkenlerin her birinin bağımlı değişken üzerindeki etkisini ölçümlemeye yönelik yazılan R kod bloğu aşağıda verilmiştir.
plot(Effect(focal.predictors = "pass",model))
plot(Effect(focal.predictors = "masteryg",model))
plot(Effect(focal.predictors = "fearfail",model))
plot(Effect(focal.predictors = "genderid",model))
#ikili karşılaştırma
plot(Effect(focal.predictors = c("genderid", "pass"),model))
Yukarıdaki kod bloğunun çalıştırılmasından sonra ilk olarak pass bağımsız değişkeninin interestlev bağımlı değişkeni üzerindeki etkisi aşağıdaki şekilde verilmiştir. Burada pass değişkeninin interestlev değişkenindeki 3. seviyede en yüksek olasılıkla etkilediği görülmektedir. Diğer bir ifade ile öğrencilerin dersten geçmesi derse olan ilgisini en yüksek seviyeye çıkarmıştır.

masteryg bağımsız değişkeninin interestlev üzerindeki etkisi aşağıdaki şekilde verilmiştir. Burada öğrencilerin daha yüksek not alması derslere olan ilgi seviyesine en yüksek seviyeye (3=çok yüksek) çıkarmıştır.

fearfail bağımsız değişkeninin interestlev üzerindeki etkisi aşağıdaki şekilde verilmiştir. Öğrencilerin kaybetme (başarısızlık) korkusu derse olan ilgi seviyesini genel olarak azaltmış olup, bu olasılığın en yüksek olduğu ilgi düzeyi 3. düzeydir.

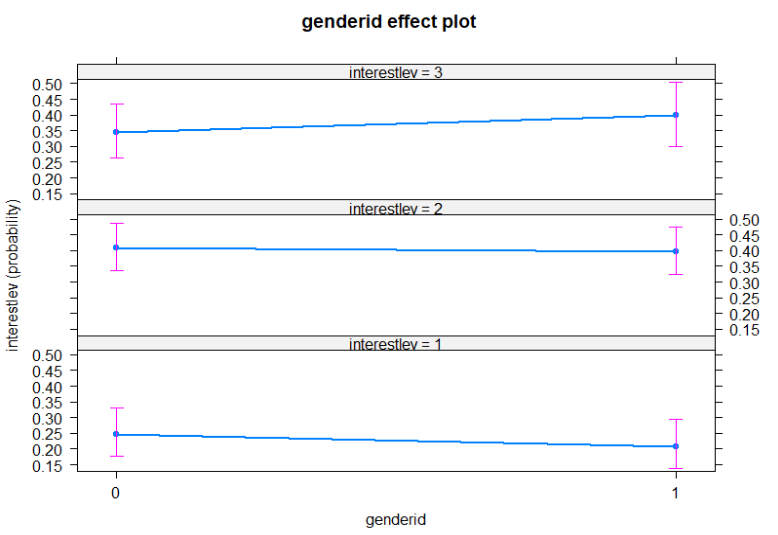
genderid bağımsız değişkeninin interestlev üzerindeki etkisi aşağıdaki şekilde verilmiştir.Şekilden kadın (1)’ların erkek (0)’lere göre daha yüksek ilgi düzeylerine sahip olduğu anlaşılmaktadır.
İki bağımsız değişkenin ortak etkisi ise aşağıdaki şekilde verilmiştir. Burada seçilen bağımsız değişkenler “genderid” ve “pass” değişkenleridir. Burada, dersten kalan kadınların ilgi düzeyinin erkeklere göre nispeten daha yüksek olduğu görülmektedir. Dersten geçen kadınların ilgi düzeyi ise dersten kalan kadınlarda olduğu gibi erkeklere göre daha yüksektir.

Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
https://www.mayo.edu/research/documents/data-types/doc-20408956
https://statistics.laerd.com/statistical-guides/types-of-variable.php
https://drive.google.com/file/d/1xCLN-jtPMsjl46w4lZzEG6_IWnY-7uqJ/view
https://sites.google.com/view/statistics-for-the-real-world/contents
Field, Andy. (2009). Discovering Statistics Using SPSS. Third Edition.
https://www.r-project.org/
http://www.sthda.com/english/articles/32-r-graphics-essentials/129-visualizing-multivariate-categorical-data/
Main Landing Page
https://stanford.edu/~shervine/l/tr/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks
https://sites.google.com/view/statistics-for-the-real-world/contents/logistic-regression-models