Birçok analiz yönteminin temelini olasılık dağılımları oluşturmaktadır. İşin esasında olasılık dağılımları tam anlaşılmadan analiz yöntemleri ile istenilen sonuçların elde edilmesi tek başına bazıları için yeterli olsa da işin felsefesini anlamak açısından kesinlikle yetersizdir. Bu nedenle bu çalışmada öncelikle kesikli (discrete) ve sürekli (continuous) dağılımlar başlıklar halinde verildikten sonra kesikli dağılım türlerinden biri olan Hipergeometrik dağılımı özgün uygulama örnekleriyle ele alınarak somutlaştırılacaktır. Uygulama örnekleri ağırlıklı olarak R programlama dili kullanılarak adım adım yapılacaktır.
Rastlantı ya da kesin olmayan olaylarla ilgilenen olasılık teorisi, rastlantı olaylarını belirli kurallara göre matematik disiplininde inceleyen bir bilim dalıdır. Burada, rastlantı olayından kasıt gerçekleşmesi şansa bağlı olan önceden bilinmeyen olaylardır.
İstatistikte ve makine öğrenmede, diğer bir deyişle veri biliminde sıklıkla kullanılan örneklem uzayına bağlı olarak olasılık fonksiyon türleri kesikli ve sürekli olmak üzere iki ana başlıkta ele alınmaktadır.
- Kesikli Olasılık Fonksiyonu: Olasılık fonksiyonlarından ilki olan kesikli olasılık fonksiyonu örneklem uzayından elde edilen sonlu veya sayılabilir sonsuz sayıda ayrık sonuçları içermektedir.
- Sürekli Olasılık Fonksiyonu: Olasılık fonksiyonlarından diğeri sürekli olasılık fonksiyonu ise örneklem uzayından elde edilen sayılamayacak sonsuz sayıda ve ayrık olmayan sonuçları içermektedir.
Kesikli olasılık fonksiyonu ile sürekli olasılık fonksiyonu arasındaki temel fark şöyle ifade edilebilir: Kesikli olasılık fonksiyonunda kesikli örneklem uzayı noktaları, sürekli olasılık fonksiyonunda sürekli örneklem uzayı ise aralıkları baz almaktadır.
Bahsedilen kesikli ve sürekli olasılık fonksiyonlarına göre dağılımlar iki ana başlık altında verilmektedir.
A) Kesikli Dağılımlar (Discrete Distributions)
- Bernoulli Dağılımı
- Kesikli Uniform Dağılımı
- Binom Dağılımı
- Poisson Dağılımı
- Negatif Binom Dağılımı
- Geometrik Dağılım
- Hipergeometrik Dağılım
B) Sürekli Dağılımlar (Continuous Distributions)
- Normal Dağılım
- Tekbiçimli Uniform Dağılım
- Cauchy Dağılımı
- t Dağılımı
- F Dağılımı
- Ki-kare Dağılımı
- Üstel Dağılım
- Weibull Dağılımı
- Lognormal Dağılımı
- Birnbaum-Saunders
- Gamma Dağılımı
- Çift Üstel Dağılımı
- Güç Normal Dağılımı
- Güç Lognormal Dağılımı
- Tukey-Lambda Dağılımı
- Uç Değer Tip I Dağılımı
- Beta Dağılımı
Hypergeometrik Dağılım
Hipergeometrik dağılım basit tekrarsız tesadüfi örneklem (iadesiz örneklem) seçiminin yapıldığı denemedir. Binom dağılımında ise her örneklem seçiminde başarı olasılığı sabit ve deneyler birbirinden bağımsızdır. Ayrıca Binom dağılımında Hipergeometrik dağılımın aksine basit tekrarlı tesadüfi örneklem (iadeli örneklem) seçiminin yapıldığı denemelerden oluşur. Ancak Hipergeometrik dağılımın ortalaması ile Binom dağılımın ortalaması aynı iken varyansları farklılık göstermektedir. Hipergeometik dağılımın varsayımları şöyledir:
- Her deneyin olası iki sonucu vardır.
- Deneyin tekrarlanma sayısı (n) sabittir.
- Deneyler birbirinden bağımsızdır.
Hipergeometrik dağılımında kullanılan merkezi dağılım ve yayılım ölçüleri Tablo 1’de verilmiştir. Eşitliklerde bir deneyde istenen sonucun ortaya çıkma olasılığı, diğer bir ifadeyle başarı olasılığı p, istenen sonucun ortaya çıkmama olasılığı ise q=1-p‘dir. Tekrarsız örnekleme söz konusu olduğu için başarı olasılığı (p) deneyden deneye farklılık göstermektedir.
Tablo 1: Hipergeometrik Dağılım Merkezi Dağılım ve Yayılım Ölçüleri

Hipergeometrik Olasılık Kütle Fonksiyonu (PMF)
Tablo 1’deki parametreler kullanılarak oluşturulan Hipergeometrik olasılık kütle fonksiyonu (PMF) aşağıdaki eşitlikte verilmiştir. Parantez içindeki eşitlikler tekrarsız kombinasyonları ifade etmektedir.
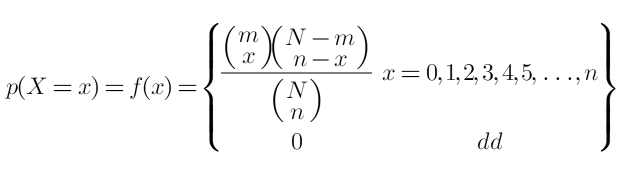
Eşitlikte N anakütle eleman sayısını, m popülasyondaki başarı sayısını, x örneklemdeki başarı sayısını, n örneklem hacmini göstermektedir.
Örnek Uygulamalar
Örnek uygulamalara geçilmeden önce R’da yüklenmesi gereken kütüphaneleri aşağıda verelim. Daha önce aşağıdaki kütüphaneler kurulmamışsa lütfen kurunuz. R studio’yu sıklıkla kullandığım için gerek arayüzünün kullanım kolaylığı gerekse verimli olması açısından R konsol yerine R Studio arayüzünün kullanılması önerilmektedir. Eğer R yüklü değilse yapılan bu işlemleri bulutta yer alan R programlama yazılımını da kullanarak yapabilir ve R Studio arayüzünden bu platform üzerinden yararlanabilirsiniz. Sıklıkla bulut üzerindeki R Studio’yu da şahsen kullanmaktayım. Aşağıda linkten buluta giriş sağlayabilirsiniz. Sıklıkla
RStudio Cloud: https://login.rstudio.cloud/
gereklikütüphaneler<-sapply(c("dplyr","tibble","tidyr","ggplot2","formattable","ggthemes","readr","readxl","xlsx","ggpubr","formattable", "ggstance","vcd"), require, character.only = TRUE)
gereklikütüphaneler
Örnek: Ortalama, Varyans, Basıklık ve Çarpıklık Değerlerinin Hesaplanması
İlk olarak Poisson dağılımında ortalama, varyans, basıklık ve çarpıklık değerlerine bakalım. R’da rhyper(nn, m, n, k) fonksiyonu kullanılarak Hipergeometrik dağılımına uygun gözlemler üretilmiştir. rhyper(nn, m, n, k) fonksiyonunda;
- m torbadaki siyah misketlerin sayısını,
- n torbadaki beyaz misketlerin sayısını,
- k veya x torbadan çekilen misketlerin sayısını (eşitlikte x),
- nn üretilecek gözlem sayısını (eşitlikte N)
göstermektedir.
İçerisinde beyaz ve siyah misketlerin olduğu torba için üretilecek gözlem sayısı (nn) 1000, torbadaki siyah misketlerin sayısı (m) 300, torbadaki beyaz misketlerin sayısı (n) 700, torbadan çekilen misketlerin sayısının ise 820 olduğu bir deneyde Hipergeometrik dağılıma uygun gözlemler üretelim. Ardından aşağıda yazılan R kod bloğunda Hipergeometrik dağılımına ait ortalama, standart sapma, varyans, basıklık ve çarpıklık değerlerini hesaplayalım. Ardından gözlemlerin histogramını çizelim..
set.seed(61)#her defasında aynı sonuçları almak için
nn=1000#üretilecek gözlem sayısı (eşitlikte N)
n=700#torbadaki beyaz misketlerin sayısı
m=300#torbadaki siyah misketlerin sayısı
k=820#torbadan çekilen misketlerin sayısı (eşitlikte x)
hgeoorneklem<-rhyper(nn, m, n, k)#Hipergeometrik Dağılıma uygun tesadüfi üretilen 1000 gözlem
#Hipergeometrik Dağılım Merkezi Dağılım ve Yayılım Ölçüleri
#Bilinenler:
N=1000#üretilecek gözlem sayısı (eşitlikte N)
n=700#torbadaki beyaz misketlerin sayısı
m=300#torbadaki siyah misketlerin sayısı
x=820#torbadan çekilen misketlerin sayısı
#hesaplama adımları
options(scipen=999)#bilimsel notasyondan sonuçları kurtarmak için
p=m/N#başarı olasılığı
q=(N-m)/N#başarısızlık olasılığı. Alternatif hesaplama: 1-p=q
ortalama=1/p
varyans= n*p*q*(N-n) / (N-1)
ssapma= sqrt(varyans)
carpiklik= (N-2*m)*(N-1)^1/2*(N-2*n) / ((n*m*(N-m)*(N-n))^1/2*(N-2))
basiklik= (N^2*(N-1) / n*(N-2)*(N-3)*(N-n))*((N*(N+1)-6*N*(N-n))/m*(N-m) + 3*n*(N-n)*(N+6) /N^2-6)
#sonuçlar tablosu
formattable(cbind(ortalama, ssapma, varyans,carpiklik, basiklik) %>% as_tibble() %>% mutate_if(is.numeric, round,6))
Yukarıdaki R kod bloğunun çalıştırılmasından sonra Hipergeometrik dağılımına ait elde edilen ortalama, varyans, çarpıklık ve basıklık değerleri aşağıdaki tabloda verilmiştir.

Yukarıdaki R kod bloğunda ilgili alan çalıştırıldığında elde edilen veri setine ait histogram aşağıda verilmiştir.

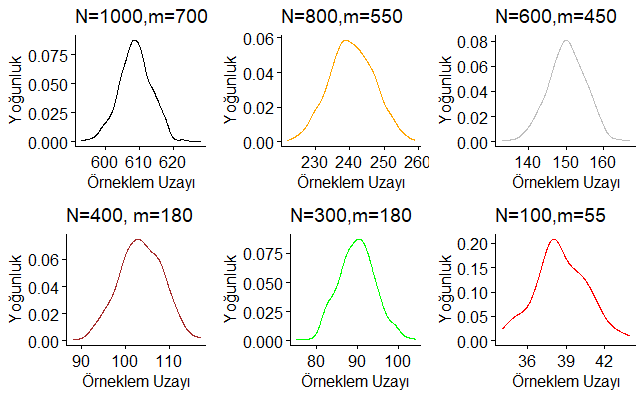
Şimdi de farklı anakütle (popülasyon) eleman sayısı (N veya nn), popülasyondaki başarı sayı (m), örneklem hacmi (n) ve örneklemdeki başarı sayısı (x veya k)’na sahip Geometrik dağılımlara grafik üzerinde bakalım. Aşağıda yazılan R kod bloğu ile;
- nn=1000, m=700, n=300, k=870
- nn=800, m=550, n=250, k=350
- nn=600, m=450, n=150, k=200
- nn=400, m=180, n=220, k=230
- nn=300, m=180, n=120, k=150
- nn=100, m=55, n=45, k=7
parametre değerleri olan Geometrik dağılım eğrileri verilmiştir.
set.seed(6)
l1<-ggdensity(rhyper(nn=1000, m=700, n=300, k=870),main="N=1000,m=700", xlab="Örneklem Uzayı",ylab= "Yoğunluk")
l2<-ggdensity(rhyper(nn=800, m=550, n=250, k=350),main="N=800,m=550", col="orange", xlab="Örneklem Uzayı",ylab= "Yoğunluk")
l3<-ggdensity(rhyper(nn=600, m=450, n=150, k=200),main="N=600,m=450", col="grey",xlab="Örneklem Uzayı",ylab= "Yoğunluk")
l4<-ggdensity(rhyper(nn=400, m=180, n=220, k=230),main="N=400, m=180", col="brown",xlab="Örneklem Uzayı",ylab= "Yoğunluk")
l5<-ggdensity(rhyper(nn=300, m=180, n=120, k=150),main="N=300,m=180", col="green",xlab="Örneklem Uzayı",ylab= "Yoğunluk")
l6<-ggdensity(rhyper(nn=100, m=55, n=45, k=70),main="N=100,m=55", col="red",xlab="Örneklem Uzayı",ylab= "Yoğunluk")
ggarrange(l1,l2,l3,l4,l5,l6)
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen grafikler aşağıda verilmiştir. Örneklem büyüklüğü artıkça Hipergeometrik dağılım Binom dağılıma evrilir.
Örnek: Kütle Olasılık Fonksiyonu (PMF)’nun Hesaplanması
Daha önce bahsedildiği üzere Hipergeometrik dağılımına ait kütle olasılık fonksiyonunun aşağıdaki eşitlik yardımıyla hesaplandığını belirtmiştik..
Şimdi özgün bir örnek üzerinde kütle olasılık fonsiyonu (pmf) oluşturarak olasılık değerlerini hesaplayalım.
Örnek 1: İçerisinde bordo ve mavi misketlerin olduğu torbada bordo misketlerin sayısı (m) 30, mavi misketlerin sayısı (n) ise 50’dir. Yerine konulmaksızın 20 misket seçiliyor.
- Problemin olasılık fonksiyonunu bulunuz.
- Problemin merkezi dağılım ve yayılım ölçülerini hesaplayınız.
- Torbadan 9 bordo misket çekme olasılığını hesaplayınız.
- Torbadan 1’den 9’a kadar (dahil) bordo misket çekme olasılıklarını hesaplayınız.
Bilinenler
- Anakütledeki eleman sayısı (N) 80’dir.
- Örneklemdeki başarı sayısı (x) 9’dur.
- Popülasyondaki başarı sayısı (m) 30’dur.
- Örneklem hacmi (n) 20’dir.
Çözüm
- Bilinenleri Hipergeometrik kütle olasılık fonksiyonunda yerine koyarsak olasılık fonksiyonu aşağıdaki gibi olacaktır. Parantez içindeki eşitlikler tekrarsız kombinasyonları göstermektedir.

2. Problemin merkezi dağılım ve yayılım ölçüleri aşağıda yazılan R kod bloğunda adım adım hesaplanmıştır.
#Bilinenler
N=80#Anakütledeki eleman sayısı (N) 80'dir.
x=9#Örneklemdeki başarı sayısı (x) 9'dur.
m=30#Popülasyondaki başarı sayısı (m) 30'dur.
n=20#Örneklem hacmi (n) 20'dir.
options(scipen=999)
p=m/N#başarı olasılığı
q=(N-m)/N#başarısızlık olasılığı. Alternatif hesaplama: 1-p=q
ortalama=1/p
varyans= n*p*q*(N-n) / (N-1)
ssapma= sqrt(varyans)
carpiklik= (N-2*m)*(N-1)^1/2*(N-2*n) / ((n*m*(N-m)*(N-n))^1/2*(N-2))
basiklik= (N^2*(N-1) / n*(N-2)*(N-3)*(N-n))*((N*(N+1)-6*N*(N-n))/m*(N-m) + 3*n*(N-n)*(N+6) /N^2-6)
#merkezi dağılım ve yayılım ölçüleri tablosu
formattable(cbind(ortalama, ssapma, varyans,carpiklik, basiklik) %>% as_tibble() %>% mutate_if(is.numeric, round,6))
Yukarıdaki R kod bloğu çalıştırılmasından sonra elde edilen merkezi dağılım ve yayılım ölçüleri tablosu aşağıda verilmiştir.

3. Torbadan 9 tane bordo misket çekme olasılığı hesaplanmış ve aşağıda verilmiştir. Buna göre torbadan 9 tane bordo misket çekme olasılığı yaklaşık 0,15117’dir.

Yukarıda yapılan işlem aşağıda yazılan R kod bloğunda da adım adım hesaplanmıştır. R’da tekrarsız kombinasyonların hesaplanmasından choose() fonksiyonu kullanılmaktadır. R kod bloğunun çalıştırılmasıyla elde edilen sonuç yukarıda elde edilen sonuç ile aynı olup, torbadan 9 tane bordo misket çekme olasılığı 0.1511677’dir.
#Bilinenler
N=80#Anakütledeki eleman sayısı (N) 80'dir.
x=9#Örneklemdeki başarı sayısı (x) 9'dur.
m=30#Popülasyondaki başarı sayısı (m) 30'dur.
n=20#Örneklem hacmi (n) 20'dir.
#torbadan 9 tane bordo misket çekme olasılığı
olasilik<-choose(m,x)*choose(N-m,n-x)/choose(N,n)
olasilik#sonuç:0.1511677
Yukarıdaki aynı işlemi R’da dhyper(x, m, n, k) fonksiyonu da kullanarak yapabilir ve bu sayede yukarıdaki işlemi de kontrol etmiş oluruz.
Bilinenler
N=80#Anakütledeki eleman sayısı (N) 80'dir.
x=9#Örneklemdeki başarı sayısı (x) 9'dur.
m=30#Popülasyondaki başarı sayısı (m) 30'dur.
n=20#Örneklem hacmi (n) 20'dir.
dhyper(x,m,N-m, n)#yani dhyper(9,30,50, 20)
#sonuç:0.1511677
Şimdide aynı işlemi Microsoft Office Excel ortamında da yaparak R bilmeyenlere de kolaylık sağlayalım. İlk olarak istenilen olasılık değerini hesaplamaya esas parametre değerlerini aşağıdaki olumsallık tablosunda verelim.

Şimdi ise torbadan 9 tane bordo misket çekme olasılığını aşağıdaki excel tablosunda verelim. Elde edilen sonuç yukarıda elde edilen sonuçlarla ile aynı olup, torbadan 9 tane bordo misket çekme olasılığı yaklaşık 0.15117’dir.

Microsoft Office Excel ortamında yapılan işlemleri kullanılan fonksiyonları da görebilmeniz adına xlsx uzantılı olarak aşağıda paylaşıyorum. Buradan bu dökümanı indirebilirsiniz.
4. Torbadan 1’den 9’a kadar (dahil) bordo misket çekme olasılıkları aşağıda yazılan R kod bloğunda hesaplanmıştır. Burada olasılıkları hesaplamada sizlere iki alternatif fonksiyon sundum. Dilediğinizi çalıştırarak aynı sonuçlara ulaşabilirsiniz.
N=80#Anakütledeki eleman sayısı (N) 80'dir.
x=1:9#Örneklemdeki başarı sayısı (x) 1'den 9'a kadar (dahil)
m=30#Popülasyondaki başarı sayısı (m) 30'dur.
n=20#Örneklem hacmi (n) 20'dir.
fonksiyon<-dhyper(x,m,N-m, n) %>% as_tibble() %>% rename(Olasilik=value) %>% mutate_if(is.numeric, round,6) %>% add_column("Sıra"=1:9, .before="Olasilik") %>% formattable()
fonksiyon
#yada
olasilik<-choose(m,x)*choose(N-m,n-x)/choose(N,n)
olasilik<-olasilik %>% as_tibble() %>% rename(Olasilik=value) %>% mutate_if(is.numeric, round,6) %>% add_column("Sıra"=1:9, .before="Olasilik") %>% formattable()
olasilik
Yukarıdaki R kod bloğu çalıştırılmasından sonra elde edilen torbadan 1’den 9’a kadar (dahil) bordo misket çekme olasılıkları sırasıyla aşağıdaki tabloda verilmiştir.

Örnek 2: 10 Numara şans oyununda haznede 80 top bulunmaktadır. İçerisinden iadesiz seçilen 22 toptan sırasıyla hiç bilmeyene (0 bilen), 6, 7, 8, 9 ve 10 bilene ikramiye verilmektedir.
İstenenler
- 10 Numara şans oyunu olasılık fonksiyonunu bulunuz.
- 10 Numara şans oyununda sırasıyla hiç bilmeme (0 bilme), 6, 7, 8, 9 ve 10 olasılıklarını sırasıyla hesaplayınız.
Bilinenler
- N= 80 (Anakütledeki eleman sayısı)
- x=0 ve 6’dan 10’a kadar (dahil) (Örneklemdeki başarı sayısı)
- m=10 (Popülasyondaki başarı sayısı)
- n= 22 (Örneklem hacmi)
Çözüm
- Bilinenleri Hipergeometrik kütle olasılık fonksiyonunda yerine koyarsak 10 Numara şans oyunu olasılık fonksiyonu aşağıdaki gibi olacaktır. Parantez içindeki eşitlikler tekrarsız kombinasyonları göstermektedir.

2. 10 numara şans oyununda sırasıyla hiç bilmeme (0 bilme), 6, 7, 8, 9 ve 10 olasılıkları aşağıda yazılan R kod bloğunda hesaplanmıştır.
#bilinenler
N=80#Anakütledeki eleman sayısı (N) 80'dir.
x=c(0, 6:10)#Örneklemdeki başarı sayısı (x) 0 ve 6'dan 10'a kadar (dahil). Burada kazanma olasılıklarının vektör içerisinde tanımlanmasının nedeni aşağıda for döngüsü işlevi görmesinin sağlanarak birden fazla olasılık fonksiyonu yazılmamak istenmemesidir. Böylece işlem süresi kısaltılmış ve işlem yükü de azaltılmıştır.
m=10#Popülasyondaki başarı sayısı (m) 10'dur.
n=22#Örneklem hacmi (n) 22'dir.
#Tablo oluşturma
tablo<-tibble(Kategori=c("Sıfır", "Altı", "Yedi", "Sekiz", "Dokuz", "On"),Kazanma_Olasılığı=as.numeric(choose(m,x)*choose(N-m,n-x)/choose(N,n))) %>% mutate(Tersine_Olasılık=1/Kazanma_Olasılığı) %>% mutate_if(is.numeric, round, 10)
tablo
#formatlanmış tablo
formattable(tablo,
align =rep("r",3),
list(formatter(
"span", style = ~ style(color = "grey",font.weight = "bold")),
`Kazanma_Olasılığı` = color_bar("#FA614B"),
`Tersine_Olasılık` = color_bar("#B0C4DE")
))
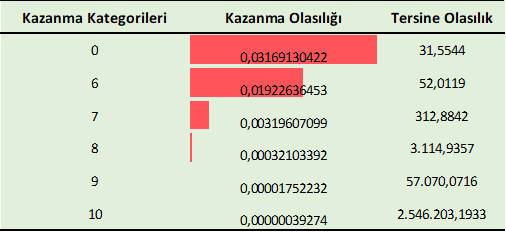
Yukarıdaki R kod bloğunun çalıştırılmasından sonra 10 Numara şans oyununda sırasıyla hiç bilmeme (0 bilme), 6, 7, 8, 9 ve 10 olasılıkları aşağıdaki tabloda verilmiştir. Aynı zamanda daha kolay anlayabilmeniz için hesaplanan olasılıkların çarpmaya göre tersi (1/Olasılık) alınmış ve tabloya yansıtılmıştır. Ortaya konulan bulgulara göre 10 numara şans oyununda
- Hiç bilmediğinizde kazanma olasılığınız yaklaşık 31,55’te 1’dir.
- 6 bildiğinizde kazanma olasılığınız yaklaşık 52,01’de 1’dir.
- 7 bildiğinizde kazanma olasılığınız yaklaşık 312,88’de 1’dir.
- 8 bildiğinizde kazanma olasılığınız yaklaşık 3.114,94’te 1’dir.
- 9 bildiğinizde kazanma olasılığınız yaklaşık 57.070,07’de 1’dir.
- 10 bildiğinizde kazanma olasılığınız yaklaşık 2.546.203,19’da 1’dir.

Yukarıda R’da hesapladığım 10 Numara kazanma olasılıklarını aynı zamanda aşağıda R’da yazdığım for döngüsü kullanarak da yapabiliriz.
N=80#Anakütledeki eleman sayısı (N) 80'dir.
x=c(0, 6:10)#Örneklemdeki başarı sayısı (x) 0 ve 6'dan 10'a kadar (dahil)
m=10#Popülasyondaki başarı sayısı (m) 10'dur.
n=22#Örneklem hacmi (n) 22'dir.
for (i in seq_along(x)) {
x[i] <-choose(m,x[i])*choose(N-m,n-x[i])/choose(N,n)
x[i]<-1/x[i]
}
print(paste(c(0, 6:10),"kazanma olasılığı:", round(x,5),"'de 1'dir."))
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen 10 Numara kazanma olasılıkları kazanma kategorilerine göre aşağıda verilmiştir.
[1] "0 kazanma olasılığı: 31.5544 'de 1'dir."
[2] "6 kazanma olasılığı: 52.01191 'de 1'dir."
[3] "7 kazanma olasılığı: 312.88416 'de 1'dir."
[4] "8 kazanma olasılığı: 3114.93568 'de 1'dir."
[5] "9 kazanma olasılığı: 57070.07157 'de 1'dir."
[6] "10 kazanma olasılığı: 2546203.19328 'de 1'dir."
Yukarıda hesaplanan 10 numara şans oyununda sırasıyla hiç bilmeme (0 bilme), 6, 7, 8, 9 ve 10 olasılıkları R bilmeyenler için ayrıca Microsoft Office Excel ortamında da hesaplanmıştır. Excel ortamında ilk olarak bilinenler tablosunu aşağıda verelim.

Yukarıdaki bilinenler tablosuna göre excel ortamında hesaplanan 10 Numara şans oyunu kazanma olasılıkları kategorilere göre aşağıda verilmiştir.
Şimdi yapılan bu işlemleri excel ortamında kullanılan fonksiyonları da görebilmeniz adına aşağıda xlsx formatında paylaşıyorum.
Hipergeometrik Kümülatif Dağılım Fonksiyonu (CDF)
Hipergeometrik olasılık dağılımda kümülatif dağılım fonksiyonu aşağıdaki eşitlik yardımıyla hesaplanmaktadır.
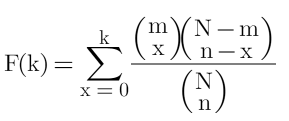
Örnek: Kümülatif Dağılım Fonksiyonu (CDF)’nunun Hesaplanması
Aşağıda yazılan R kod bloğunda ise phyper(q, m, n, k) fonksiyonu kullanılarak kümülatif dağılım fonksiyonu (cdf) hesaplanmıştır. Yukarıdaki örneğimizden hareketle kümülatif dağılım olasılıklarını hesaplayalım.
Örnek: İçerisinde bordo ve mavi misketlerin olduğu torbada bordo misketlerin sayısı (m) 30, mavi misketlerin sayısı (n) ise 50’dir. Yerine konulmaksızın 40 misket seçiliyor. Torbadan 30 bordo misket çekme olasılıklarını kümülatif olarak hesaplayarak grafiğiniz çiziniz.
- k=40:torbadan çekilen misketlerin sayısı (eşitlikte n)
- q=1-30:torbadan çekilen bordo misketlerin sayısı (eşitlikte x)
- m=30:bordo misketlerin sayısı
- n=50:mavi misketlerin sayısı
göstermektedir.
#bilinenler
k=40#torbadan çekilen misketlerin sayısı.
q=1:30#torbadan çekilen bordo misketlerin sayısı
m=30#bordo misketlerin sayısı
n=50#mavi misketlerin sayısı
#kümülatif dağılım fonksiyonu (cdf)
kdf<-phyper(q, m, n, k)
#kümülatif dağılım fonksiyonu (cdf) grafiği
sonuc<-kdf %>% as_tibble() %>% mutate_if(is.numeric, round,8) %>% mutate(Orneklem_Uzayı=1:NROW(kdf), Olasilik=as.numeric(value))
grafik<-sonuc[,-1] %>% ggplot(aes(x=Orneklem_Uzayı,y=Olasilik)) + geom_line(color="brown", size=1.5) +
guides(fill=FALSE) +
scale_x_continuous(breaks=seq(1,30,2))+
ggtitle("Hipergeometrik Kümülatif Dağılım Fonksiyonu (CDF)") +
ylab("Olasılık")+
xlab("Başarılı Denemelerin Sayısı")+
theme_igray()+
theme(plot.title = element_text(hjust = 0.5))
grafik
Yukarıdaki R kod bloğunun çalıştırılmasından sonra elde edilen kümülatif olasılık değerleri aşağıda verilmiştir. Kümülatif olasılık değerlerini hesapladığımız için aşağıda da görüleceği üzere her halükarda son olasılık değeri 1’e eşittir veya yaklaşık 1’dir ve böyle olduğu da aşağıda görülmektedir.
[1] 0.00000000001051915 0.00000000050173131 0.00000001390300665
[4] 0.00000025297218642 0.00000323655554991 0.00003043067474839
[7] 0.00021690463496653 0.00119977780028297 0.00524622638731670
[10] 0.01841741653811158 0.05262830004666962 0.12403056070278859
[13] 0.24438754856460831 0.40880379091155827 0.59119620908844150
[16] 0.75561245143539157 0.87596943929721127 0.94737169995333037
[19] 0.98158258346188842 0.99475377361268325 0.99880022219971698
[22] 0.99978309536503351 0.99996956932525161 0.99999676344445010
[25] 0.99999974702781358 0.99999998609699337 0.99999999949826868
[28] 0.99999999998948086 0.99999999999990452 1.00000000000000000
Şimdi de hesaplanan bu kümülatif olasılık değerlerine göre kümülatif olasılık fonksiyonu (CDF:Cumulative Distribution Function)’nun grafiğini çizelim.

Yapılan çalışma ile özellikle veri bilimi (data science) ile ilgilenen akademi ve saha çalışanlarına bir katkı sunulması amaçlanmıştır.
Daha önce kesikli olasılıklı dağılım türleri üzerine örnek uygulama yaptığım çalışmaların linklerini de aşağıda paylaşıyorum ilgilenenler için.
Bernoulli Olasılık Dağılımı Üzerine Bir Vaka Çalışması
Binom Olasılık Dağılımı Üzerine Bir Vaka Çalışması
Kesikli Uniform Olasılık Dağılımı Üzerine Bir Vaka Çalışması
Poisson Olasılık Dağılımı Üzerine Bir Vaka Çalışması
Negatif Binom Olasılık Dağılımı Üzerine Bir Vaka Çalışması
Geometrik Olasılık Dağılımı Üzerine Bir Vaka Çalışması
Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Saygılarımla.
Not: Kaynak gösterilmeden alıntı yapılamaz veya kopyalanamaz.
Note: It can not be cited or copied without referencing.
Yararlanılan Kaynaklar
- https://www.sciencedirect.com/topics/engineering/hypergeometric-distribution
- https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781119197096.app03
- http://www.math.ucsd.edu/~gptesler/186/slides/186_hypergeom_17-handout.pdf
- https://link.springer.com/referenceworkentry/10.1007%2F978-3-642-04898-2_294
- https://tr.wikipedia.org/wiki/Hipergeometrik_da%C4%9F%C4%B1l%C4%B1m
- https://web.stanford.edu/class/bios221/labs/simulation/Lab_3_simulation.html
- https://www.sciencedirect.com/topics/computer-science/geometric-distribution/pdf
- https://online.stat.psu.edu/stat504/node/169/
- https://cran.r-project.org/web/packages/ggpubr/ggpubr.pdf
- http://www.mas.ncl.ac.uk/~nag48/teaching/MAS1403/notes4.pdf
- https://tevfikbulut.com/2020/07/23/rda-poisson-ve-negatif-binom-regresyon-yontemleri-uzerine-bir-vaka-calismasi-a-case-study-on-poisson-and-negative-binomial-regression-methods-in-r/
- https://my.ilstu.edu/~wjschne/442/SimulatingRandomData.html#discrete-uniform-distribution
- https://en.wikipedia.org/wiki/Discrete_uniform_distribution
- http://www.hcs.harvard.edu/cs50-probability/binomial.php
- http://people.stern.nyu.edu/adamodar/New_Home_Page/StatFile/statdistns.htm
- https://statisticsglobe.com/bernoulli-distribution-in-r-dbern-pbern-qbern-rbern
- https://stat.ethz.ch/R-manual/R-devel/library/stats/html/Distributions.html
- https://my.ilstu.edu/~wjschne/442/SimulatingRandomData.html#bernoulli-distribution
- https://www.itl.nist.gov/div898/handbook/eda/section3/eda366.htm
- RStudio Cloud: https://login.rstudio.cloud/
- Matematiksel İstatistik, İsmail Erdem, Gözden Geçirilmiş ve Genişletilmiş 3. Baskı.
- The R Project for Statistical Computing. https://www.r-project.org/
- Microsoft Office Excel 2010 Version, Microsoft Corporation. Technology company. Redmond, Washington, United States
- https://online.stat.psu.edu/stat504/node/57/#:~:text=The%20Poisson%20Model%20(distribution)%20Assumptions,the%20same%20for%20all%20teams.
- http://kisi.deu.edu.tr//kemal.sehirli/B%c3%b6l%c3%bcm%204%20-%20Part1(d%c3%bczeltme).pdf
- https://stat.ethz.ch/R-manual/R-devel/library/stats/html/Geometric.html
- http://www.imatheq.com/imatheq/com/imatheq/math-equation-editor.html
- https://tr.wikipedia.org/wiki/Hipergeometrik_da%C4%9F%C4%B1l%C4%B1m
- http://www-eio.upc.es/teaching/pe/www.computing.dcu.ie/~jhorgan/chapter12slides.pdf
- https://tevfikbulut.com/2020/08/02/sans-oyunlari-perspektifinden-olasilik-probability-from-the-perspective-of-chance-games/
- https://www.mathworks.com/help/stats/hygecdf.html
- https://en.wikipedia.org/wiki/Hypergeometric_distribution
- http://www.imatheq.com/corpsite/index.html
- http://www.math.ucsd.edu/~gptesler/186/slides/186_hypergeom_17-handout.pdf
- http://www-eio.upc.es/teaching/pe/www.computing.dcu.ie/~jhorgan/chapter12slides.pdf
- https://stat.ethz.ch/R-manual/R-devel/library/stats/html/Hypergeometric.html